







第三章使用 TypeScript 编写爬虫工具
爬去 官网的 项目名称 和 当前课程学习人数
1. 构建 TypeScript文件目录 项目
1. npm init -y。 项目中新增package.json文件
2. tsc --init。 项目中新增tsconfig.json文件
3. npm uninstall ts-node -g 全局卸载ts-node
4. cnpm install -D ts-node 在本地项目中配置ts-node
5. 新建src目录,创建crowller.ts。 console.log(‘项目初始化完毕’)
6. 修改package.json配置,使用 npm run dev 启动
"scripts": { "dev": "ts-node ./src/crowller.ts" },
7. npm install typescript -D 本地安装typescript
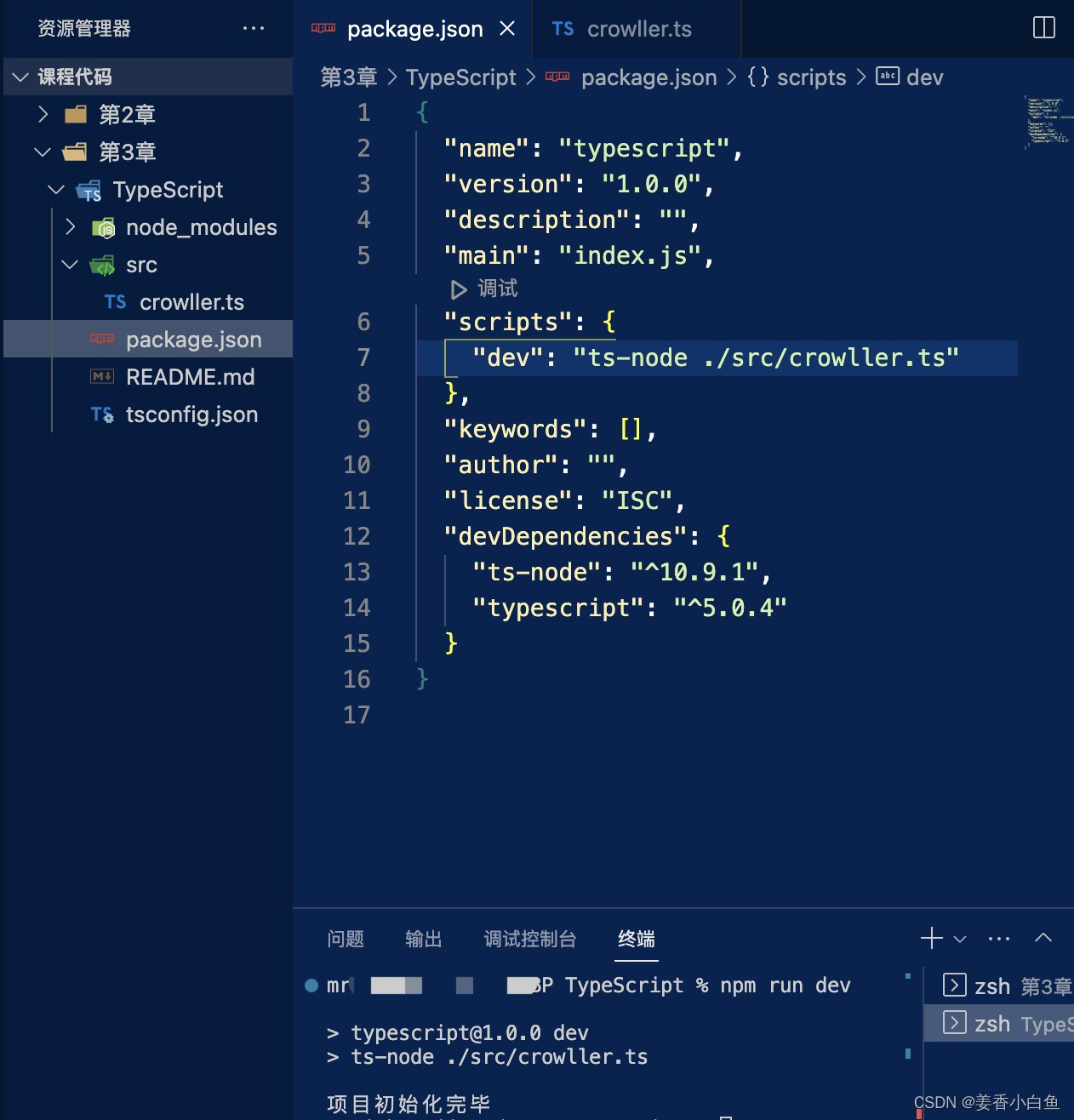
构建完成后的 package.json文件
{
"name": "typescript",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"dev": "ts-node ./src/crowller.ts"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"ts-node": "^10.9.1",
"typescript": "^5.0.4"
}
}
控制台终端 npm run dev
2. 爬取网址html上的数据内容
1. 通过 superagent 这个工具 获取网址上面,html的内容
2. js库ts无法直接读取 cnpm install superagent–save
3. ts使用翻译文件 @types/引入js库 cnpm install @types/superagent -D
/**
* 创建一个 名称为Crowller的类
* 访问类型
* public 允许 在类的内外被调用
* private 允许 在类内部被使用,不允许类外部使用
* protected 允许 在类内及 继承的子类中被使用,不允许类外使用
* ts 无法直接引用 js库 ,需要一个.d.ts的翻译文件,才可以引入 js库
*/
/* 通过 superagent 这个工具 获取网址上面,html的内容
js库ts无法直接读取 cnpm install superagent--save
ts使用翻译文件 @types/引入js库 cnpm install @type 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











