













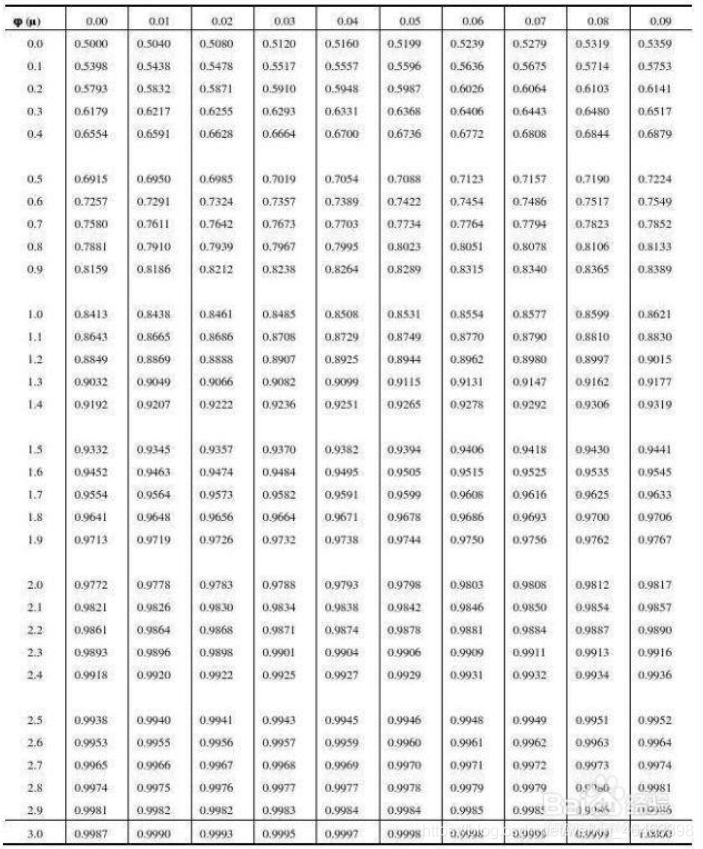
正态分布概率分布表,自查概率密度函数
调用函数如下
% M-K总体趋势检验
clc
clear
%file= readmatrix("7777.csv");
data=[1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 19 18 ...
17 16 15 14 3 15 1 2 5 1 15 2 5 21 4 7 58 9 6 4 5 1 2 0]; %输入原始数据--时间序列
%趋势检验
data=data';
alp=0.05; %假设置信度为0.05
[Zmk,beta,output] = MK_trend(data,alp)
%突变检验
[UF,UB]= MK_mutation(data);
%概率密度函数
F=@(t)integral(@(x)(exp(-x.^2/2)/sqrt(2*pi)),-t,t)-(1-alp);
UF1 = fsolve(F,1);
%绘图
x=1:1:length(UF);
UF1=UF1.*ones(length(UF),1);
figure;
plot(x,UF,'b-')
hold on;
plot(x,UB,'g-')
hold on;
plot(x,UF1,'r-')
趋势检验调用函数
%趋势检验
function [Zmk,beta,output] = MK_trend(data,alp)
%Zmk为趋势检验统计值,beta横梁趋势大小的指标,output假设检验结果
%计算检验统计值S
sgn=[];
for i=1:size(data,1)-1
if data(i)>data(i+1)
sgn(i,1)=-1;
elseif data(i)==data(i+1)
sgn(i,1)=0;
elseif data(i)<data(i+1)
sgn(i,1)=1;
end
end
S=sum(sgn);
%计算方差Var
%当数据量小于10个数据的时候,此时数据量太小,一般是直接去概率表中查找S,这里直接给出S与Zmk的关系式
if size(data,1)<=10
Zmk=2*S/((size(data,1))*(size(data,1)-1));
%当数据量大于10个数据的时候
else
%判断数据是否都是唯一的数据,如果数据唯一的话采用下面的计算方法
if length(unique(data))==length(data)
Var=((size(data,1))*(size(data,1)-1)*(2*size(data,1)+5))/18;
%当数据量不唯一的时候
else
%找出所有重复数据的重复次数
count=hist(data,unique(data));
%将重复次数为1的数据剔除掉
count(count==1)=[];
%计算Var
Var=(length(data)*(length(data)-1)*(2*length(data)+5)...
-sum(count.*(count-1).*(2.*count+5)))/18;
end
%计算Zmk
if S>0
Zmk=(S-1)/sqrt(Var);
elseif S==0
Zmk=0;
elseif S<0
Zmk=(S+1)/sqrt(Var);
end
end
%衡量趋势大小的指标
t=1;
for i=2:length(data)
for j=1:(i-1)
slope(t)=(data(i)-data(j))/(i-j);
t=t+1;
end
end
beta=median(slope);
%假设检验,双边假设,判断趋势是否明显
%概率密度函数
F=@(t)integral(@(x)(exp(-x.^2/2)/sqrt(2*pi)),-t,t)-(1-alp);
Zmk1 = fsolve(F,1);
if Zmk>0
if abs(Zmk)>=Zmk1
output=1; %'在alp的置信水平上,数据处于明显上升的趋势'
else
output=2; %'在alp的置信水平上,数据处于上升趋势'
end
elseif Zmk<0
if abs(Zmk)>=Zmk1
output=3; %'在alp的置信水平上,数据处于明显下降的趋势'
else
output=4; %'在alp的置信水平上,数据处于下降趋势'
end
else
output=5; %'不增不减'
end
end
突变检验
function [UF,UB]= MK_mutation(data)
%将正序放在第一列,逆序放在第二列
data=[data flipud(data)];
for n=1:2
for i =2:size(data,1)
r=[];
%计算秩序列
for j=1:i-1
if data(i,n)>data(j,n)
r(j,n)=1;
else
r(j,n)=0;
end
end
k=i-1;
Sk(k,n)=sum(r(:,n));
%计算均值
ESk(k,n)=k*(k+1)/4;
%计算方差
VarSk(k,n)=k*(k-1)*(2*k+5)/72;
%计算统计变量
UFk(k,n)=(Sk(k,n)-ESk(k,n))/sqrt(VarSk(k,n));
end
end
%正序计算结果取第一列
UF=UFk(:,1);
%逆序计算结果取第二列的负数
UB=flipud(-UFk(:,2));
%UF1、UB1都为0;
%UF=[0;UF];
%UB=[0;UB];


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









