






目录
简介:
etcd是coreOS团队发起的开源项目,是一个高可用的分布式键值(key-value)数据库,是go语言编写的,再K8S集群中是重要组件,用于存储K8S集群数据
官网 https://etcd.io/
硬件推荐 https://etcd.io/docs/v3.5/op-guide/hardware/etcd备份与恢复
1、修改etcd.service配置集群
root@etcd1:~# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd
ExecStart=/usr/local/bin/etcd \
--name=etcd-172.31.7.106 \ #当前节点名称
--cert-file=/etc/kubernetes/ssl/etcd.pem \
--key-file=/etc/kubernetes/ssl/etcd-key.pem \
--peer-cert-file=/etc/kubernetes/ssl/etcd.pem \
--peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--initial-advertise-peer-urls=https://172.31.7.106:2380 \ #通告自己的集群端口
--listen-peer-urls=https://172.31.7.106:2380 \ #集群之间通信端口
--listen-client-urls=https://172.31.7.106:2379,http://127.0.0.1:2379 \ #客户端访问地址
--advertise-client-urls=https://172.31.7.106:2379 \ #通告自己的客户端端口
--initial-cluster-token=etcd-cluster-0 \ #创建集群使用token,一个集群内的节点保持一致
--initial-cluster=etcd-172.31.7.106=https://172.31.7.106:2380,etcd-172.31.7.107=https://172.31.7.107:2380,etcd-172.31.7.108=https://172.31.7.108:2380 \
#上面配置是集群内所有节点信息
--initial-cluster-state=new \ #新建集群的时候的值为new,如果是已经存在的集群为existing
--data-dir=/var/lib/etcd \ #数据目录路径
--wal-dir= \
--snapshot-count=50000 \ #快照数量,可以做50000个快照
--auto-compaction-retention=1 \ #第一次压缩等待1h,以后压缩间隔时间是1h的10%,也就是6min
--auto-compaction-mode=periodic \ #指定周期性压缩,对etcd中的数据压缩,节省磁盘空间
--max-request-bytes=10485760 \ #最大请求字节数,客户端在请求etcd时数据量大小不能超过该值(官方默认值是不能超过10M,=10485760字节)
--quota-backend-bytes=8589934592 #在etcd中能存储数据的总量,磁盘存储空间大小限制,默认2G,存储超过8G启动会有告警信息
Restart=always
RestartSec=15
LimitNOFILE=65536
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target2、重启K8S集群所有etcd节点
集群中每个etcd节点都按照要求修改配置文件后重启
3、验证
root@etcd1:~# /usr/local/bin/etcdctl defrag --cluster --endpoints=https://172.31.7.106:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem
Finished defragmenting etcd member[https://172.31.7.107:2379]
Finished defragmenting etcd member[https://172.31.7.108:2379]
Finished defragmenting etcd member[https://172.31.7.106:2379]各节点认证
![]()


显示集群成员信息
#/usr/local/bin/etcdctl --write-out=table member list --endpoints=https://172.31.7.106:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem
etcd常用命令
4、通过etcd数据恢复
4.1、删除pod资源
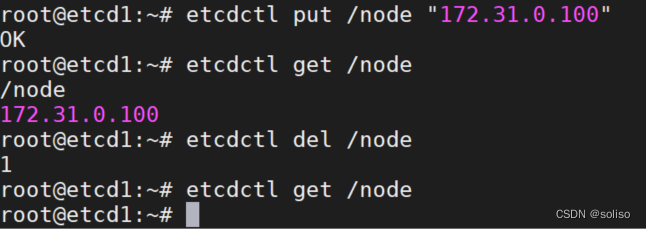
演示通过etcd直接删除pod,现在有三个myapp pod,可以直接从etcd层面删除pod

查看
root@etcd1:~# etcdctl get / --keys-only --prefix | grep myserver-myapp
删除
root@etcd1:~# etcdctl del /registry/pods/myserver/myserver-myapp-0
1
put写入数据,get查看数据,del删除数据
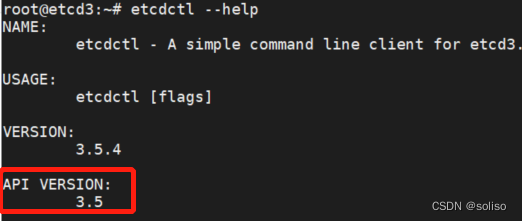
etcd v3 API版本数据备份与恢复
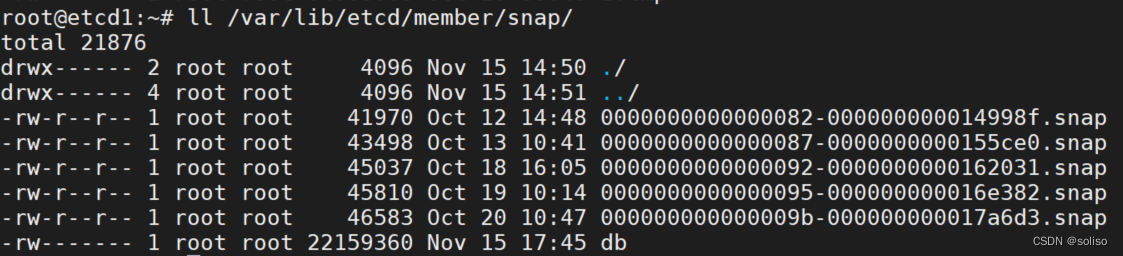
预写日志

4.2、数据备份
数据备份到/tmp/test.db
root@etcd1:~# etcdctl snapshot save /tmp/test.db
后面可以使用test.db文件来恢复数据
root@etcd1:~# ll /tmp/test.db
-rw------- 1 root root 22159392 Nov 15 17:49 /tmp/test.db
etcd集群三个服务器,只需要备份一份,可以给三个服务器恢复4.3、数据恢复
把快照文件/tmp/test.db恢复到/opt/etcd2目录中
root@etcd1:~# etcdctl snapshot restore /tmp/test.db --data-dir="/opt/etcd2"以项目为背景做备份与恢复
root@k8s-deploy:/etc/kubeasz# ./ezctl --help
backup <cluster> to backup the cluster state (etcd snapshot)
备份集群状态,本质就是给etcd做快照实现
1、查看下backup任务内容
root@k8s-deploy:/etc/kubeasz# vim playbooks/94.backup.yml
2、创建3个pod
root@k8s-deploy:/etc/kubeasz# kubectl run net-test1 --image=centos:7.9.2009 sleep 10000000 -n myserver
root@k8s-deploy:/etc/kubeasz# kubectl run net-test2 --image=centos:7.9.2009 sleep 10000000 -n myserver
root@k8s-deploy:/etc/kubeasz# kubectl run net-test3 --image=centos:7.9.2009 sleep 10000000 -n myserver
3、可以看见有这3个pod了
root@k8s-deploy:/etc/kubeasz# kubectl get pod -A | grep test
myserver net-test1 1/1 Running 0 2m42s
myserver net-test2 1/1 Running 0 2m27s
myserver net-test3 1/1 Running 0 5s
4、下面开始备份
root@k8s-deploy:/etc/kubeasz# ./ezctl backup k8s-cluster1
PLAY RECAP ********************************************************************************************************************************
localhost : ok=10 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
备份完后的文件在/etc/kubeasz/clusters/k8s-cluster1/backup/11月十五号的,并且会强制拷贝至snapshot.db,因为默认恢复是通过snapshot.db文件进行恢复的,因此想要恢复到哪个版本就需要把那个版本的文件手动拷贝到snapshot.db文件中

下面删除一个pod,只剩下两个test pod了
root@k8s-deploy:/etc/kubeasz# kubectl delete pod net-test3 -n myserver
基于刚刚删除之后再进行一次备份
root@k8s-deploy:/etc/kubeasz# ./ezctl backup k8s-cluster1
PLAY RECAP *************************************************************************************************************************
localhost : ok=10 changed=6 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 新备份的db文件同时也会拷贝到snapshot.db
现在使用上面备份的文件,这个文件备份的是有三个test pod的,下面就将它还原
可以看下恢复任务的文件
root@k8s-deploy:/etc/kubeasz# vim roles/cluster-restore/tasks/main.yml
root@k8s-deploy:/etc/kubeasz# cd clusters/k8s-cluster1/backup/
root@k8s-deploy:/etc/kubeasz/clusters/k8s-cluster1/backup# ll
total 73756
drwxr-xr-x 2 root root 4096 Nov 15 20:55 ./
drwxr-xr-x 5 root root 4096 Nov 15 14:44 ../
-rw------- 1 root root 4509728 Sep 9 20:43 snapshot_202209092043.db
-rw------- 1 root root 4509728 Sep 9 21:10 snapshot_202209092110.db
-rw------- 1 root root 22159392 Nov 15 18:11 snapshot_202211151811.db
-rw------- 1 root root 22159392 Nov 15 20:55 snapshot_202211152055.db
-rw------- 1 root root 22159392 Nov 15 20:55 snapshot.db
把备份了三个test pod是文件拷贝至snapshot.db
root@k8s-deploy:/etc/kubeasz/clusters/k8s-cluster1/backup# cp snapshot_202211151811.db snapshot.db
此时test的pod还是两个
root@k8s-deploy:/etc/kubeasz# kubectl get pod -A | grep test
myserver net-test1 1/1 Running 0 3h52m
myserver net-test2 1/1 Running 0 3h52m
进行恢复
root@k8s-deploy:/etc/kubeasz# ./ezctl restore k8s-cluster1
PLAY RECAP *************************************************************************************************************************
172.31.7.101 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.102 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.103 : ok=5 changed=4 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.106 : ok=10 changed=8 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.107 : ok=10 changed=8 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.108 : ok=10 changed=8 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.111 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.112 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
172.31.7.113 : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0经过刚刚的数据恢复,再来看下pod情况

同理可以用删除后的备份文件再恢复到删除后的状态














 2665
2665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









