






目录
简介:
学习K8S最主要的三个核心资源,POD 、控制器 、service;后期所有的功能都是用来补充来使其功能更加完善,管理更加完备
service是用于K8S的服务发现的重要组件,pod作为运行业务的承载方式,要想被客户端访问或者集群内部其它服务访问,就需要提供一个访问入口;
传统来说ip+端口是普适的访问方式,但是pod是一种动态的资源,它会因故障被重建或重启,因而pod ip会发生变化,所以使用ip作为pod的访问入口并不合适;而K8S是通过service来充当pod与访问端的中间代理,要访问pod首先访问pod对应的service,再由service代理到对应的pod
而pod采用了标签来代替ip作为唯一标识,以供service筛选。service对应的也有标签选择器用来筛选pod标签
而service本身是ipvs规则,是由kube-porxy组件生成的,这个规则只要不删除就会一直存在,但是删除了service ip也会发生变化,这样一来客户端仍有无法访问到service ip的风险
因此K8S使用了DNS来记录service ip和service域名的记录,客户端使用域名就可以通过DNS中拿到对应的service ip了,而当service ip发生变化时,DNS也会动态的即使跟新到记录表中,这样即使service ip发生改变,仍然可以通过service的域名拿到对应的service ip,有了service ip就可以访问到Service 而后service代理到对应的pod上
service有四种类型:(主要用两种)
1、clusterIP: 在K8S集群内部通信使用,无法接入集群外部流量
2、NodePort: 可以接入集群外部流量,在每个node节点监听一个相同的端口,用于客户端的访问,会把请求转发到对应的service,然后service再转发给pod; 用于将K8S服务暴露给K8S以外的客户端访问
注:serviceIP=clusterIP
NodePort 访问流程如下:
client ------->nodeIP:nodePort------->clusterIP:clusterPort-------->podIP:containerPort
何为无头服务?
service的模式都是在上一种模式的基础上增强版,nodePort就是在clusterIP的基础上新增了功能,并不是一种新的功能模式,因为nodePort模式下客户端访问过程中还是要经过clusterIP的,这意味着clusterIP是service最基本要件,但也可以把这个clusterIP移除掉,而一旦No cluster,就称为无头服务了,无头服务的主要作用在于可以把服务名称(service_name)直接解析到后端的podIP;而本来只能解析到serviceIP
一、创建clusterIP类型的service资源服务
使用clusterIP类型service,使服务只限于K8S集群内部访问
1、创建一个nginx容器
# vim deployment-node.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: ng-deploy
template:
metadata:
labels:
app: ng-deploy
spec:
containers:
- name: nginx-app
image: nginx:1.20.0
ports:
- containerPort: 80
root@k8s-deploy:~/yaml/yl# kubectl apply -f deployment-node.yaml
 nginx服务已经启动了,但如果想要从K8S集群环境以外的地方访问到这个服务,那就必须要创建service, 通过service来访问nginx
nginx服务已经启动了,但如果想要从K8S集群环境以外的地方访问到这个服务,那就必须要创建service, 通过service来访问nginx
2、创建一个service资源
# vim svc.yaml
kind: Service
apiVersion: v1
metadata:
name: ng-deploy
spec:
ports:
- name: http
port: 80 #service端口
targetPort: 80 #容器端口
protocol: TCP
# type: ClusterIP #这个可以不写,默认就是clusterIP
selector:
app: ng-deploy
注:service必须要和pod在同一个namespace中,没有声明namespace,默认就在default,在default namespace中所有pod中找标签key=app,value=ng-deploy的pod,符合这个标签的pod就会被关联到这个service的后端
root@k8s-deploy:~/yaml/yl# kubectl apply -f svc.yaml 
可以看见service服务已经启动了,是clusterIP类型的,service ip是10.100.25.220
因为clusterIP类型的service只支持K8S集群内部访问,所以现在集群内部节点是可以访问的,集群之外的主机是无法访问的
3、访问测试
3.1、集群内部节点node1访问service ip
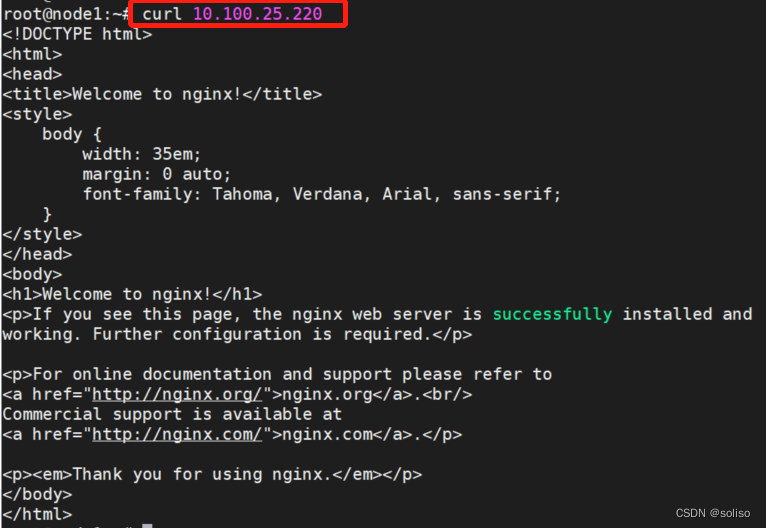
3.2、集群之外的部署服务器是无法访问的
4、通信过程解说
之所以K8S集群内部可以访问是因为集群内部节点有生成了ipvs规则,在集群内部生成的虚拟子网
而集群之外的节点没有这个网络的路由,自然是无法联通的
可以根据ipvs规则看见访问10.100.25.220地址就会被转发到10.200.104.41

可以看下路由表,发现10.200.104.41这个地址被转发给了172.31.7.112,而这个地址就node2的节点ip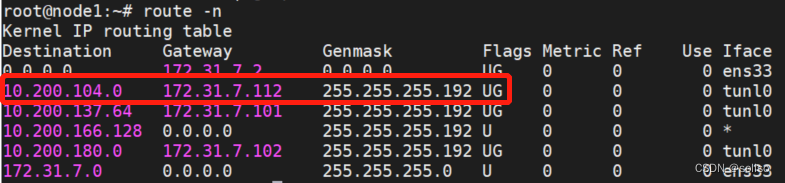
此时172.31.7.112就会有这个路由表,可以看见10.200.104.41会转给cali5a4294a369f这个网卡,而这个网卡就是pod在宿主机的网卡,通过这个网卡就到达容器了,容器接收请求后再原路返回
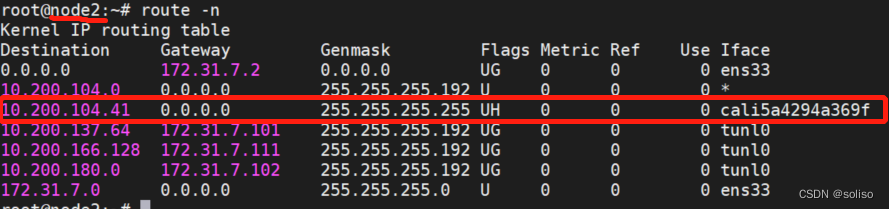
总结:之所以有上面的各种规则,所以clusterIP类型的service,在K8S内部是联通的;而K8S集群外的主机没有生成这些规则所以无法联通
二、创建nodePort类型service资源
使用nodePort类型Service,使服务可以被集群外部访问到
先把前面的service删除

1、修改yaml文件
把svc.yaml文件修改成NodePort类型的service
# vim svc.yaml
kind: Service
apiVersion: v1
metadata:
name: ng-deploy
spec:
ports:
- name: http
port: 81 #service监听的端口,会把81端口的请求转给容器的80端口
targetPort: 80 #容器监听的端口
nodePort: 30012 #手动指定个宿主机端口,每个node节点都会监听这个端口,这个端口的请求会转给service端口的81
protocol: TCP
type: NodePort #类型指定为NodePort,它会在每个node节点监听一个相同的端口
selector:
app: ng-deploy
2、创建资源
# kubectl apply -f svc.yaml
3、测试访问
访问任意node节点的30012端口
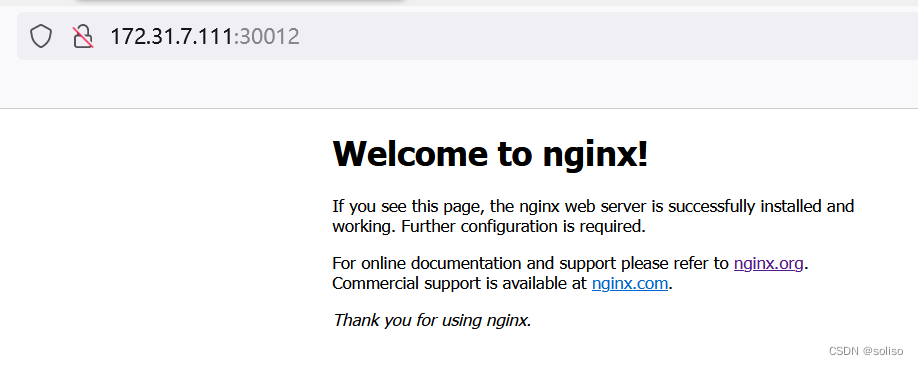
这样就可以直接访问到node节点的服务了
三、负载均衡器服务代理
负载均衡器部署可参照博客: https://blog.csdn.net/weixin_46476452/article/details/127783634这里也可以使用负载均衡器来做服务代理
vim /etc/haproxy/haproxy.cfg 进入配置文件添加代理,而后重启服务
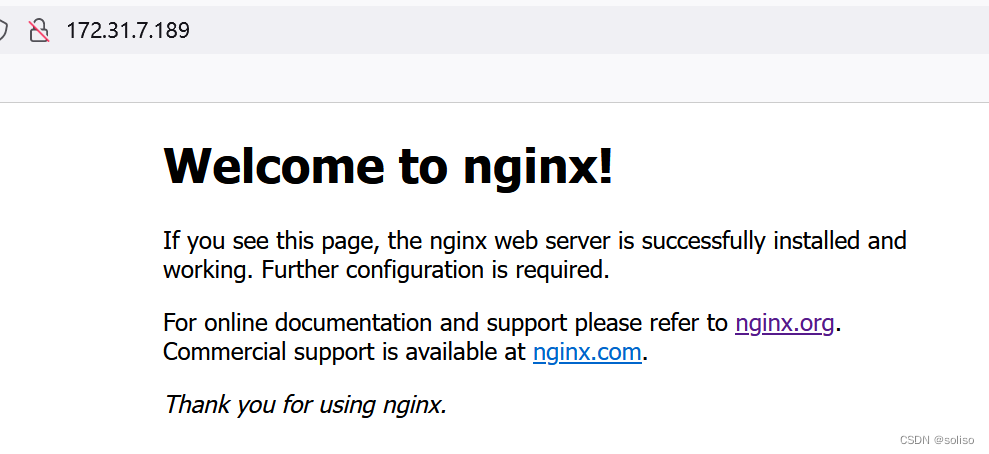
用172.31.7.189这个VIP来代理nignx服务

这样就可以通过负载均衡器访问pod服务了















 2726
2726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









