






目录
前言:
Yolov5主要分为五种网络模型(YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x):
针对于640*640:

针对于1280*1280:
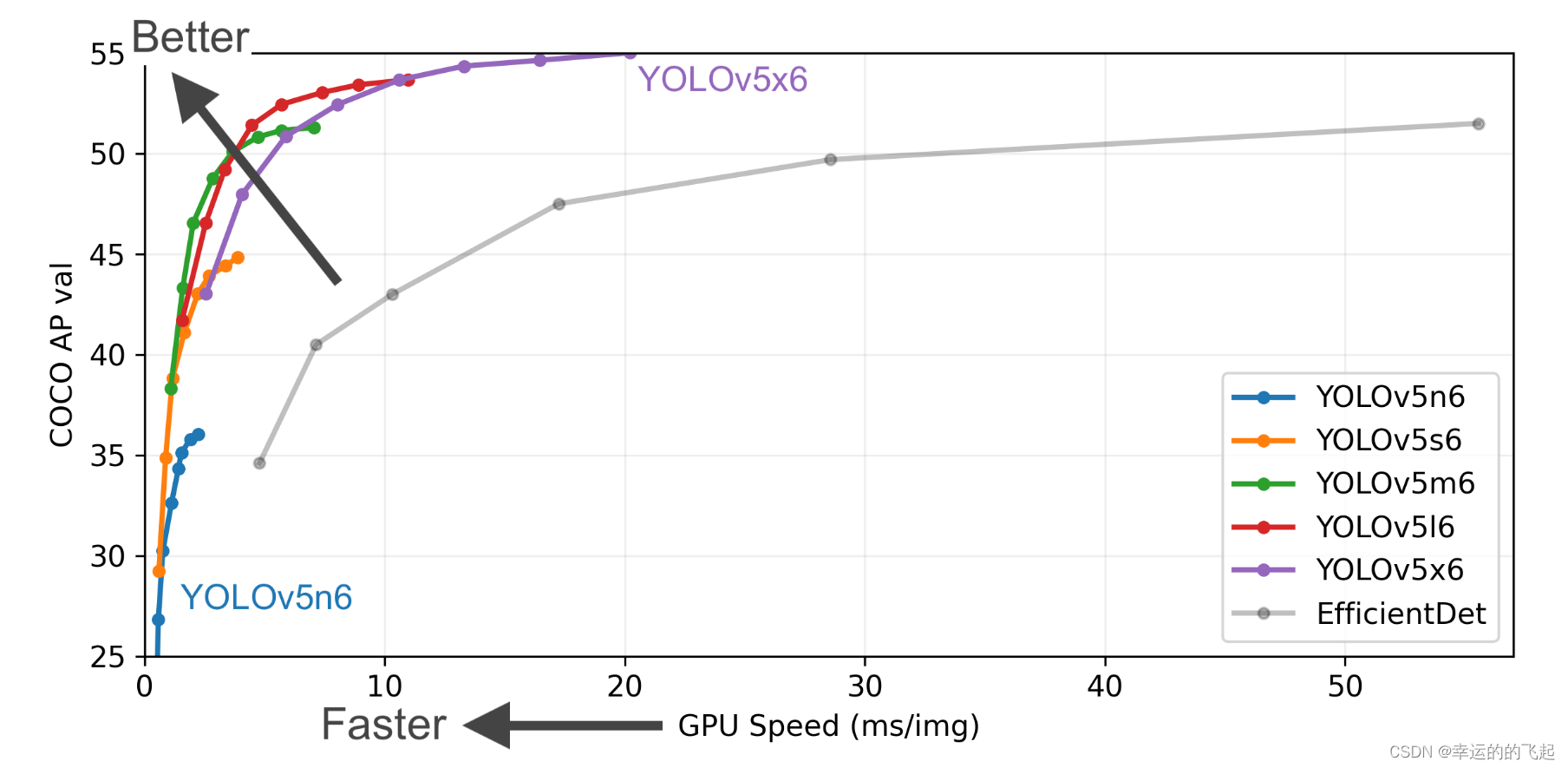

Yolov5有n,m,s,l,x五种结构,主要是网络层次结构的深浅,x的网络层次和通道数最多。
Yolov5的网络结构主要分为:
- Backbone:主要对输入图像进行特征提取。
- Neck:主要对特征图进行多尺度特征融合,并把这些特征传递给预测层。
- Head:进行最终的回归预测,主要负责物体检测任务中的特征提取和预测,在输入的图像上提取高层次的特征,并使用这些特征来预测图像中出现的物体的位置和类别。
Yolov5网络结构图:
以yolov5(v6.1)为例:
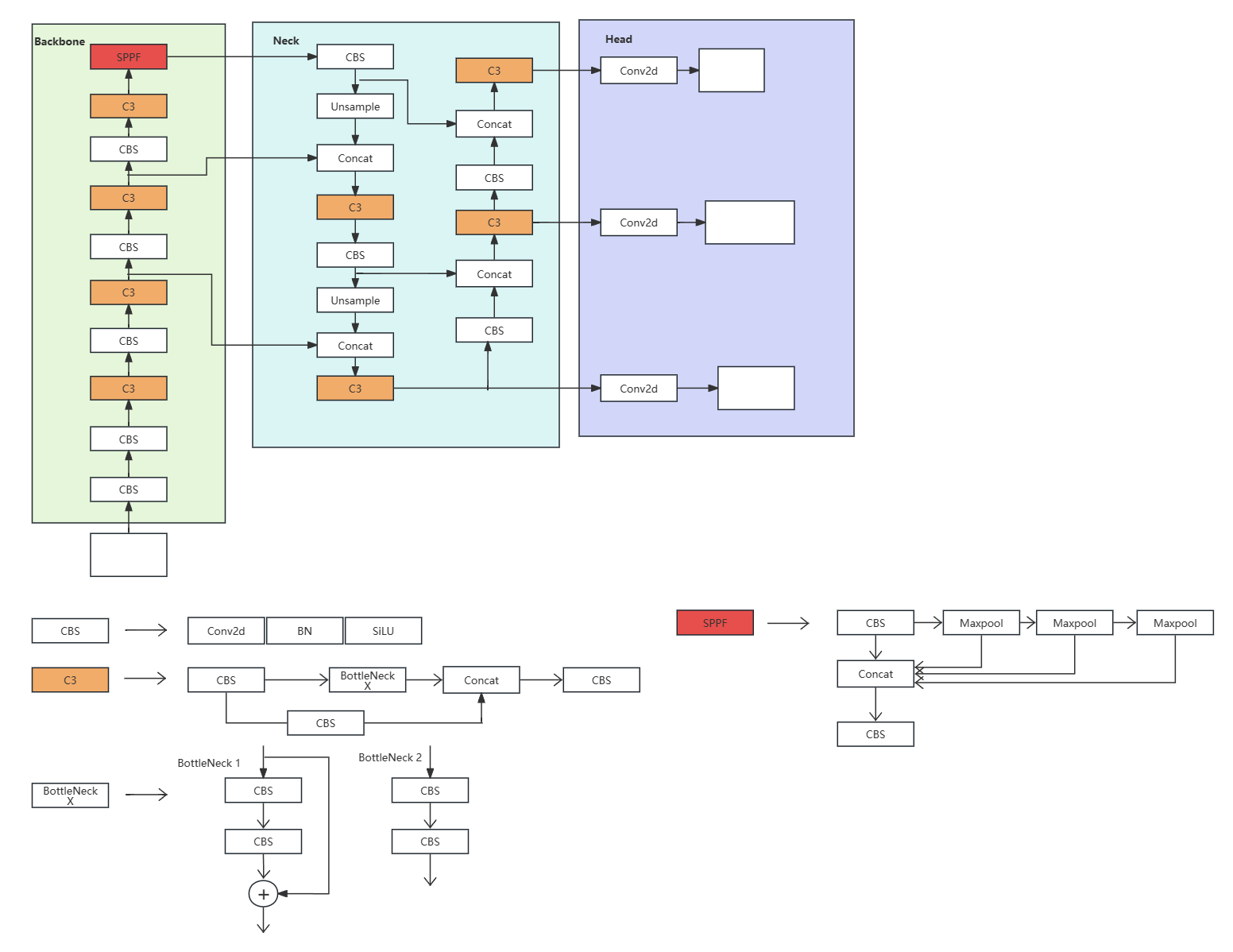
Yolov5的改进:
- 输入端:数据增强、自适应锚框计算、自适应的图像缩放
- Bockbone:New CSP+Darknet53
- Neck:FPN+PAN、SPPF
- Head:CIOU Loss
数据增强:
- Mixup:将两个图合并为一张,改变透明度。
- CutMix:选择两张图像,将图像A进行随机缩放和剪裁,粘贴到图像B上。实现掩盖的作用,使难度增加。
- Mosaic:选择四张图像,进行随机缩放、剪裁、排布,组成一张图像。增加数据复杂性,加快训练速度。
- Copy paste:将图像中的一部分复制到其他图像中。
自适应锚框计算:
将计算先验框高宽比的程序代码嵌入到整个训练过程中。每次训练时,代码将自动计算最佳锚框值,从而确保目标检测的准确性和性能。同时,如果用户觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭,进行手动调整。
自适应的图像缩放:
在做推理预测时,以最小代价增加图像的边缘框,目的减少过多的冗余信息。
步骤:
- 根据原始图片大小以及输入到网络的图片大小计算缩放比例。
- 选择较小的缩放系数。
- 计算需要填充的黑色区域。
举例:
已知原始图片尺寸为800×600,而输入到网络的图片尺寸为416×416。
- 缩放比列:416/800=0.52 416/600=0.69
- 选择较小缩放系数:0.52
- 计算填充区域:缩放后的图片为416*312(800*0.52=416,600*0.52=312),可知需要填充宽(416-312=104)。进行取余,要求宽必须是32的倍数(图像经历了5次降维,2^5=32),104mod32=8,即图像的左右两边各填充4(8/2=4)
New CSP+Darknet53:


由上图可知,进行了激活函数的改进,并使用残差结构,既实现了计算量的降低,也更好的进行了特征融合。
FPN+PAN:
在yolov5的网络结构中采取了自上而下,自下而上的双塔结构,既得到了高层语义信息,又得到了低层细节信息,更好的进行了特征融合。
 |  |
SPPF:
SPPF存在于yolov5 v6.1之后的版本中,是在SPP基础上改进的。


由上图可知,由并行的Max pool改为了串行的Max pool,速度上得到了提高。
GIOU Loss:
对边框回归损失进行优化,主要是让边框坐标和真实坐标越接近越好,其发展历程:
Smooth L1 Loss --> IOU Loss --> GIOU Loss --> DIOU Loss-->CIOU Loss
IOU Loss :检测框与目标框重叠面积,即IOU Loss=1-(交集/并集)。但是当两个框没有交集时,IOU Loss为0,无法反映两者之间的距离大小。

GIOU Loss:在IOU的基础上,它通过计算两个框的最小外接矩形面积,再计算出IOU,然后计算矩形面积中不属于两个框的区域占矩形面积的比重,最后用IOU减去这个比重得到GIOU。

DIOU Loss:在IOU和GIOU的基础上,增加了中心点归一化距离,解决了目标框完全包裹预测框时GIOU无意义的问题。

CIOU Loss:在DIOU的基础上,它增加了预测框长宽比和目标框长宽比之间的关系进行添加,提升了损失函数的抑制效果,加强了待测目标的统一性。

总结:
yolov5系列不同的版本之间主要的框架结构都是相同的,只是根据不同的需要,在细节部分有所不同,比如使用的激活函数不同,或者是更换了不一样的边框回归损失函数等操作。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









