






官方已经出指令了 不用这么麻烦了
功能说明
影刀提供的调用流程,必须要开发期就确定调用的子流程名称,如下图:
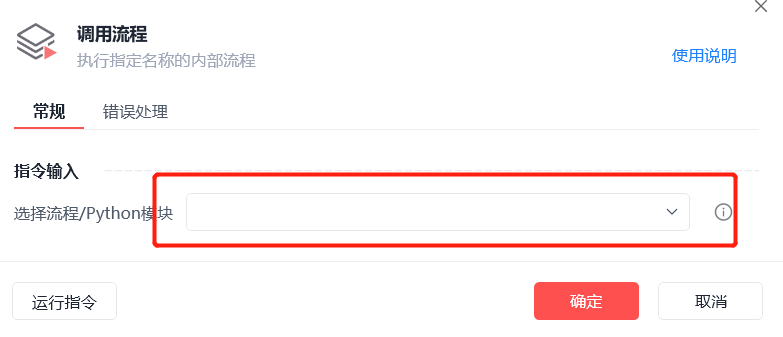
期望:
调用流程名可以参数化
实现方案
1. 编写调用模块
第一步:新建python流程,且为流程添加参数
- 新建 invoke.py文件
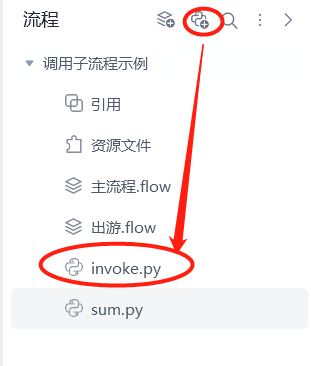
- 入参:流程名、流程参数;出参:调用结果,见下图:

第二步,在invoke.py中编写逻辑,如下:
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import importlib
import os
import json
import xbot_visual
def main(args):
flow_name = args.get('流程名',None)
params = args.get('流程参数',{})
if flow_name is None:
raise ValueError('流程名称必须指定')
#调用流程
folder = source_folder()
process_name = find_process_name(folder, flow_name)
#处理回参
outputs = parse_output(folder, process_name)
args['调用结果'] = run(process_name, params, outputs)
def run(module_name, inputs, outputs):
if outputs is not None:
prargs = {}.fromkeys(outputs)
else:
prargs = None
if inputs is not None:
for key, value in inputs.items():
prargs[key] = value
mod = importlib.import_module(f"..{module_name}", __name__)
mod.main(prargs)
#取返回值
results = {}
if outputs and prargs:
for item in outputs:
results[item] = prargs.get(item,None)
return results
def find_process_name(source_folder, flowname):
# parse package.json
with open(os.path.join(source_folder,'package.json'),'r',encoding='utf-8') as f:
json_obj = json.loads(f.read())
flows = json_obj['flows']
for flow in flows:
if flow['name'] == flowname:
filename = flow['filename']
if filename == 'main':
raise ValueError('无法调用主流程')
return filename
raise ValueError(f'未找到名为【{flowname}】的流程,请检查!')
def parse_output(source_folder,process_name):
flow_file_name = os.path.join(source_folder,'.dev',f'{process_name}.flow.json')
if not os.path.exists(flow_file_name):
raise ValueError(f'未找到名为【{process_name}】的流程文件,请检查!') #一般不会找不到,除非文件损坏
outputs = []
with open(flow_file_name,'r',encoding='utf-8') as f:
json_obj = json.loads(f.read())
params = json_obj["parameters"]
for p in params:
if p['direction'] == 'Out':
outputs.append(p['name'])
return outputs
def source_folder():
return os.path.dirname(__file__)2. 如何调用
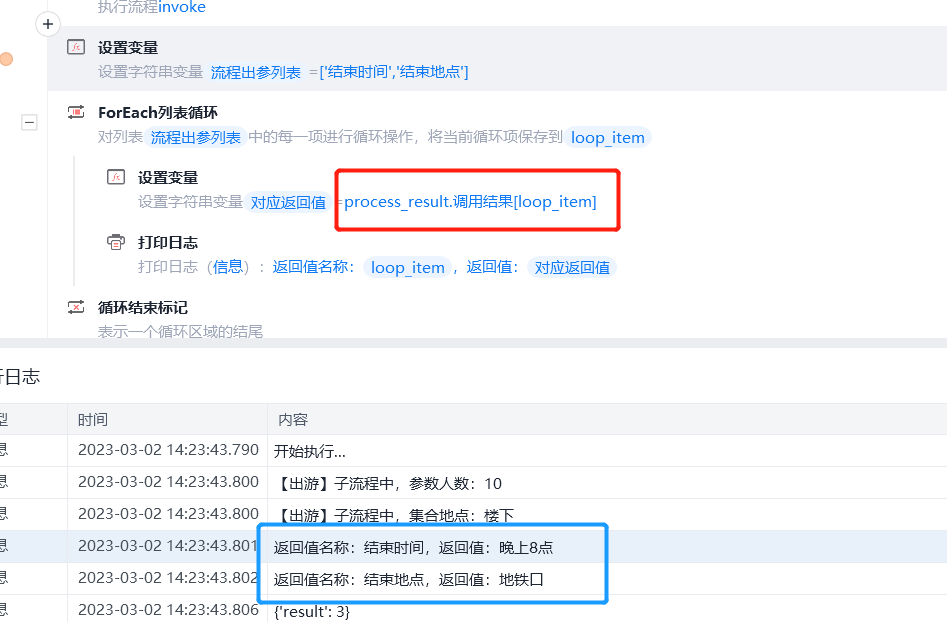
假定有这样的一个流程:
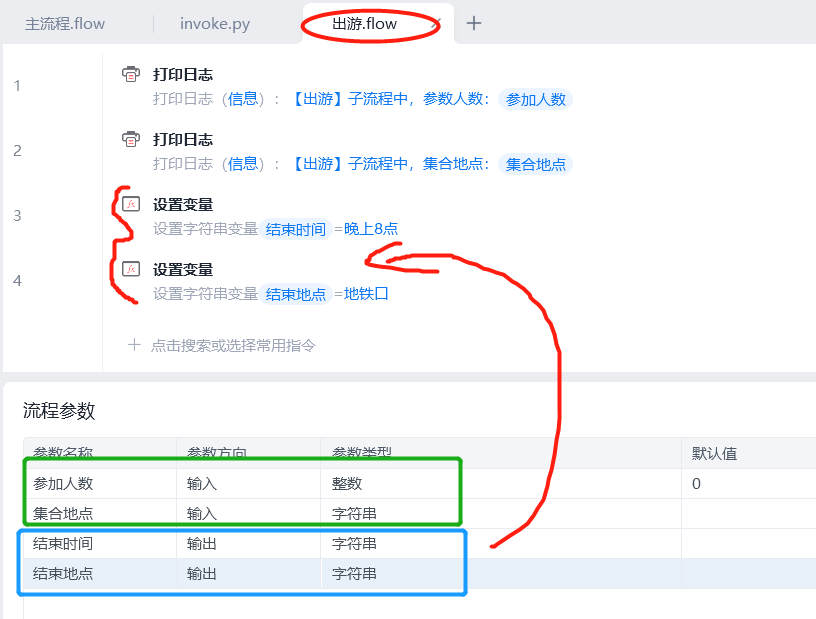
调用前,准备流程名和参数
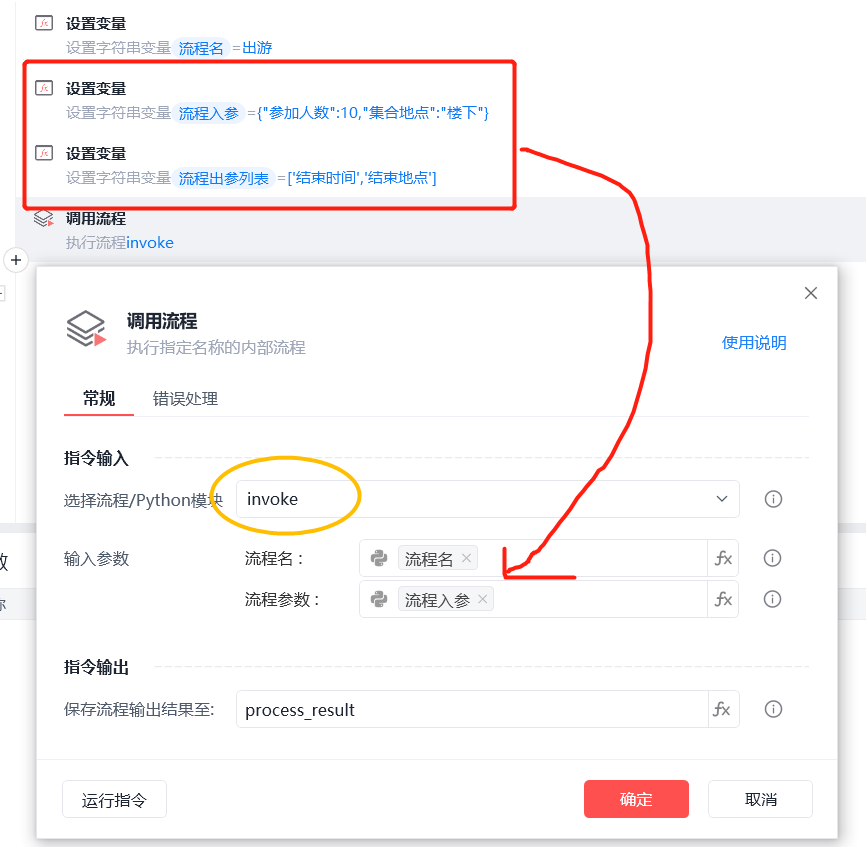
调用后,获取流程的回参
关于作者:持续分享干货,不断授人以渔,不辍收集软件,不停成长进阶,致力成为超有用的号主。全网同名【小可耐教你学RPA】,速来关注,与大家一同快乐成长、努力学习! 涉及领域广泛,包括 RPA 技能、生活经验、法律学习、科普文章、自媒体经验、理财知识、保险、人生思考、反赌、反诈骗等。 文章更新频率一切随缘。 赠人玫瑰,手有余香。爱分享,爱思考。ps:收集的教程和思路可能来源互联网,我这边只做整合,如有侵权及时联系,方便下架!

















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









