







 目录Excel操作Pandas数据处理新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入Excel操作Pandas数据处理你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdo
目录Excel操作Pandas数据处理新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入Excel操作Pandas数据处理你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdo
目录
- 0. 概述
- 1. 读取(打开)excel
- 2. 不规则数据结构pd.read读取
- 3. xw选取数据转成dataframe
- 4. xw定位行列位置,将处理结果填入表中
- 5. xw追加(粘贴)数据并向下应用公式
- 5.5. xw粘贴数据方法的限制
- 6. 使用xw临时打开python内数据为一个excel表格
- 7. 时间处理
- 8. xw插入行并复制内容
- 9. xw遍历sheet,按需选取
- 10. 列字母与列数字转化
- 11. dataframe重置多层表头为单层表头
- 12. 代码替代excel公式(pandas列计算)
- 13. 数据拼接concat和merge
- 14. 遍历文件夹下所有文件
- 15. 存档数据更新,并封装为一个函数
- 16. vlookup功能的类似实现
- 17. 数据去重的处理(pivot_table和groupby)
- 18. 压缩包解压
- 19. 自动发送邮件(简易)
- 20. 连接数据库
- 22. Jupyter Notebook引用自己写的代码文件
- 23. 按某列空白值折叠表格
- 24. 对某列空白值做向下填充
- 25. 模拟键鼠操作浏览器(了解)
- 26. 删除变量释放内存
- 27. 一些不常见的报错
0. 概述
1、已转移其他笔记平台,这边停更
1. 读取(打开)excel
常用两种方法
(还有其他可操作库,因为没有用过不作介绍了)
一种是pandas的read
import pandas as pd
filepath = ...
# 读取excel
df = pd.read_excel(filepath)
# 读取csv
df = pd.read_csv(filepath)
"""上述两个read常用的参数有:
1、sheet_name=['sheet1'] 如果文件里有多个sheet,需要指定读取哪一个,默认0
2、skiprows=n 跳过文件的前n行
3、nrows=n 只取文件的前n行
4、usecols=['a','b','c'] 如果文件行列数不规则,可以指定选取需要的a,b,c列
5、如果表格中表头是不全的,比如有的列有名字,有的列没有名字,则会自动对空列名补上“Unnamed:1”
这个特性在有些时候有用,有些时候没有,网上也有很多搜索关于怎么去掉这个,所以因人而异。
个人而言会写一个简单的函数过滤掉无效的列
"""
另一种的使用xlwings库,网上基础教程比较完善,基本框架如下:
import xlwings as xw
app=xw.App(visible=False,add_book=False) #前三行代码固定
app.display_alerts=False
app.screen_updating=False
readpath = 'E:/..略..' #文件路径
wb = app.books.open(readpath) #打开文件,定义为一个workbook变量
sht = wb.sheets[0] #选取目标sheet,可使用数字表示sheet顺序,0即选取第一个,常用在只有一个sheet的情况,多个sheet时推荐使用字符串具体指定,且能在一次打开中多次切换sheet
df = pd.DataFrame(sht.range("A1:D10").value) #选取目标区域转化成dataframe,以进行后续的加工处理
##
# 这里做数据处理
##
wb.save() #默认原文件保存,若在此处传入其他路径,就相当于另存为
wb.close() #关闭workbook
app.quit() #关闭app
"""
注意事项:
1、使用xw时,文件会被占用,此时手动打开excel会让你以只读方式打开
只有wb.close()或app.quit()后,才会将文件释放出来
如果xw这部分直接写在一个函数里,遇到报错后进程不会结束,文件无法释放出来
因为封装在函数内也就无法手动quit,通常只能restart kernel
所以建议与try..except搭配使用,以确保任何意外下总是释放文件,个人常用框架为:
app=xw.App(visible=False,add_book=False)
app.display_alerts=False
app.screen_updating=False
try:
...
except Exception as e:
print(type(e), e) #打印错误
app.quit()
2、理论上可以在一个app下操作多次excel,通常为了不出现冲突,每次完成一个excel操作后我都会app.quit(),别的地方需要时再新定义一个app即可。
3、经验上wb.close()不是必须的,对于中间步骤的数据文件,如果一次性打开了数十个,我会偷懒在调用结束后直接app.quit()
之后在打开excel时会看到提示上次未正常关闭的文件,但是问题不大,一般都忽略
4、对于数据量较大,文件内除数据外还有大量公式、格式、透视表的excel,xw的打开速度会快于pd.read,数据结构简单单纯数据量大pd.read也很快
5、运行过程中偶尔会出现类似com_error: (-2147023174, 'RPC 服务器不可用。', None, None)的错误
经验上可以检查一下指定sheet时是不是给了一个不存在的sheet name,但更多时候重新运行一遍就可以了,且在运行期间尽量不去手动关闭其他的excel表
"""
第3点图注

2021/9新增:
最近处理的数据量越来越大,逐渐发现一些新的问题:
1、数据量大(100M上下或更大)、混杂(中文、数字等)的表格,使用pandas.read系列会慢到心碎,常常5分钟起步
2、上述同样的数据,xlwings能较快的读出来(1分钟上下),但是!一旦文件体积大于200M,会报内存错误(电脑当时的内存非常充足),故猜想这是xlwings本身的限制。但是不知道如何解决
为什么说是200M呢,因为相同的使用环境下,190+M的文件都可以打开,202M的一定会报错,故200M是本人猜测,网上也没查到相关信息

3、综上,使用csv文件似乎是突破限制的一个办法,对于读取速度可以用pandas.read_csv的chunksize方法解决(read_excel无该方法),读取上效果比较理想,但是会遇到关于文本格式的新问题(也有对应的解决办法)
4、如果数据量继续增大,下一步的考虑只能是导入本地数据库了
2. 不规则数据结构pd.read读取
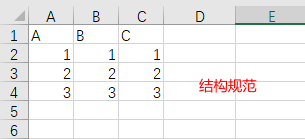

如果数据结构是n*m,则读取十分方便,不需要额外操作。
如果数据结构是混合的,像上图那样只需要提取中间一部分的内容,且每次目标内容所在位置并不完全一样(如果相对位置固定也简单很多),但上下文数据之间具备一定的布局规律。这时就需要判断起止位置,把目标截取出来。
对图上例子如下:
import csv
file_path = ....
with open(file_path, "r", encoding='utf8') as csvfile:
reader = csv.reader(csvfile)
tag = False #是否找到开始位置的判断变量
row = 0 #当前所在行
for i in reader: #遍历文件行,输出每行为列表形式
if i == ['A1', 'B1', 'C1']: #寻找开始行
start_row = row
tag = True
if len(i) == 0 and tag == True: #寻找结束行
end_row = row
break
row += 1
print(file_path, start_row, end_row)
temp = pd.read_csv(file_path, skiprows=start_row, usecols=[0, 1, 2]) #因为从0开始,start_row不需要-1
df = temp.iloc[:end_row-start_row-1].copy() #根据文件格式得到的式子
3. xw选取数据转成dataframe
对于结构规范的表,在打开表后,直接如下即可选出数据
df = pd.DataFrame(sht.used_range.value)
"""
注意此处的used_range有可能把excel的全部140多万行都选进来,因为有时候我们看到没内容的地方并不代表就是空的
这需要手动选取空白区域,删除行(或列),就可以了
"""
不同于pd.read会自动把第一行作为表头,使用xw需要手动操作一下
df = pd.DataFrame(sht.used_range.value)
df.columns = df.iloc[0].values #用第一行重置表头
df = df.drop(0) #删掉第一行
df = df.reset_index(drop=True) #重置index
若需要手动选择一定范围的数据,就使用df = pd.DataFrame(sht.range("A1:A2").value),至于range里怎么圈定范围,就有很多情况了,这个根据具体情况来。
4. xw定位行列位置,将处理结果填入表中
思路是借助dataframe,定位目标的行索引 ridx 和列索引 cidx ,再还原到实际表中的行列位置,向该位置的单元格填入结果
# 行列坐标参考获取
last_row = pd.DataFrame(sht.range("A:A").value).last_valid_index()+1
df_ridx = pd.DataFrame(sht.range("A2:B"+str(last_row)).value) #行索引
df_cidx = pd.DataFrame(sht.range("C1:AH1").value) #列索引
# 填数
col_name = 'xxx' #目标列
pvt = xxx #pvt是一个处理好的dataframe数据
idx = df_cidx[df_cidx[0].str.contains(col_name)==True].index
cidx= idx[0] + 3 #列坐标,+3是因为上面从C列开始获取索引,还原到表中则要补上前面三列的位置
pvt_len = len(pvt)
for k in range(pvt_len):
geo = pvt.iloc[k]['country']
os = pvt.iloc[k]['os']
day = pvt.iloc[k]['date']
try:
idx = df_ridx[(df_ridx[0]==day)
&(df_ridx[1].str.contains(os)==True)
&(df_ridx[1].str.contains(geo)==True) #使用等于还是只包含某字段就好,视实际情况选择
].index
ridx = idx[0] + 2 #行坐标,+2理由与列类似
sht.range(ridx,cidx).value = pvt.iloc[k][col_name] #填数
except IndexError:
pass
5. xw追加(粘贴)数据并向下应用公式
对应手动操作:在现有的表最后粘贴上新的数据,并将旁边的公式拉下来
图示

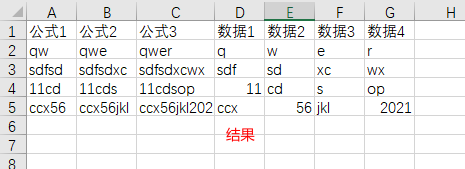
df_input = xxx #处理好的,待粘贴的数据
col_name = 'D' #对应上图示例
col_num = 4 #D列对应的列位置数值
last_row = sht.range('A' + str(sht.cells.last_cell.row)).end('up').row #原最后一行
sht.range(last_row+1,col_num).options(index=0,header=0,expand='table').value = df_input #粘贴数据
new_last_row = sht.range(col_name + str(sht.cells.last_cell.row)).end('up').row #贴入新数据后的最后一行
formula = sht.range((last_row,1),(last_row,col_num-1)).formula #提取公式
sht.range((last_row,1),(new_last_row,col_num-1)).options(expand='table').formula = formula #粘贴公式
#此处语句是实现了粘贴,公式粘贴后会自动变更对应的行列参数,因此达到效果
#注意粘贴公式时要带上原有公式区域的最后一行
"""
1、注意在使用这个功能时,需要在原excel中设置好公式自动更新,否则会失效!(被坑过)具体设置位置如下图所示
2、这个粘贴方法存在上限,下一点细说
"""
注意设置为自动(默认自动,一般不会动到这里,仅作须知)

5.5. xw粘贴数据方法的限制
上一点已经涉及,模拟粘贴的核心代码就是sht.range(last_row+1,col_num).options(index=0,header=0,expand='table').value = df_input #粘贴数据
这里单独说一下此方法的上限,举一个实际例子如下:
已知 result 是一个(1081119, 6)的数据集,sht 为读取的一个csv文件sheet。
可见如果截取前100万行,可以正常执行粘贴,但是全部执行的话就会报错。经查证错误代码-2147352567表示索引错误,原因就是在粘贴时数据量超出了excel表格可展示上限,导致索引错误。
从这个问题可以理解到,xw操作excel就像是系统替你打开了表格,以程序代替手动对表格进行操作,并没有超越手动表格的限制,对于更大数据量的读取存储操作,只有使用pd.read()/pd.save()这样的操作。


---------------------------------------------- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









