







#系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
java代理?
动态代理:
动态代理利用了JDK API,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。
- newproxyInstance(classloader loader, //指定当前使用的类加载器
-
class<?>[] interfaces, //目标对象实现的接口类型 -
invocationHandler h) // 事件处理器 - invocationHandler: override invoke(Object proxy, Method method, Object[] args);
静态代理和动态代理的区别
- 静态代理在编译时已经确定实现,编译完成后代理类是一个实际的class文件。
- 动态代理在运行时生成的,即编译完成后没有实际的class文件,而在运行时动态生成字节码,并加载到JVM中。
cglib代理
是一个第三方的代码生成类库,运行时在内存中动态生成一个子类对象从而实现对目标对象功能的扩展。可以代理没有实现接口的类;底层是通过使用一个小而快的字节码处理框架ASM来转换字节码并生成新的类。
cglib与Java动态代理的最大区别
- 使用动态代理的对象必须实现一个或者多个接口
- 使用cglib代理的对象无需生成接口,但是不能对final修饰的类进行代理
序列化
为什么需要序列化
java序列化是指把java对象转换为字节序列化的过程,而java反序列化是指把字节序列化恢复为java对象的过程。
- 永久的保存对象,保存对象的字节序列到本地或数据库中
- 通过序列化以字节流的形式使对象在网络中进行传递和接收
- 通过序列化在进程间传递对象
几种常用的序列化
- JSON 是一种轻量级的数据交换语言,该语言以易于让人阅读的文字为基础,用来传输由属性值或者序列性的值组成的数据对象,类似 xml,Json 比 xml更小、更快更容易解析。JSON 由于采用字符方式存储,占用相对于字节方式较大,并且序列化后类的信息会丢失,可能导致反序列化失败。
- Kryo 是一个快速高效的 Java 序列化框架,旨在提供快速、高效和易用的 API。无论文件、数据库或网络数据 Kryo 都可以随时完成序列化。 Kryo 还可以执行自动深拷贝、浅拷贝。这是对象到对象的直接拷贝,而不是对象->字节->对象的拷贝。kryo 速度较快,序列化后体积较小,但是跨语言支持较复杂。
- Hessian 是一个基于二进制的协议,Hessian 支持很多种语言,例如 Java、python、c++,、net/c#、D、Erlang、PHP、Ruby、object-c等,它的序列化和反序列化也是非常高效。速度较慢,序列化后的体积较大。
负载均衡
目的
通过调度集群,达到最佳资源使用,最大吞吐率,最小化响应时间,避免单点过载问题
静态均衡:
- 轮询法:将请求按顺序轮询分配到每个节点上,不关心每个节点实际的连接和当前的系统负载
- 随机法:将请求随机分配到每个节点上
- 源地址哈希法:根据客户端的IP地址取模,通过哈希函数得到一个数值,与节点数进行取模。(hot spot问题)
- 加权轮询
- 加权随机
动态均衡:
- 最小连接数:根据每个节点的连接情况动态地选取其中积压连接数最少的节点处理请求
- 最快响应算法:根据请求响应时间,来动态调节每个节点的权重
- 观察模式法:结合最小连接数和最快响应,进行一个权重分配
Dubbo的四种负载均衡:
-
RandomLoadBalance:random生成随机数
-
LeastActiveLoadBalance:
(1)如果获得的活跃度小于最小活跃度,请求发送到当前invoke
(2)如果活跃度等于最小活跃度,比较权重
(3)如果都相等则随机 -
ConsisitentHashLoadBalance:
(1)为了解决互联网的hotspot问题
(2)引入虚拟节点来解决数据倾斜问题
数据倾斜问题: -
RoundRobinLoadBalance
内存零拷贝
DMA: 直接内存访问。在进行I/O设备和内存数据传输的时候,数据搬运的工作全部交给DMA控制器,CPU不再参与任何与数据搬运相关的工作,这样CPU可以处理其他事情。
如何实现零拷贝?
- mmap+write
mmap() 系统调用函数会直接把内核缓存区的数据【映射】到用户空间,这样操作系统内核与用户空间不需要就不需要进行任何的数据拷贝。 - sendfile
Netty
Netty的高性能
- IO线程模型:同步非堵塞,同最少的资源做更多的事情
- 内存零拷贝:尽量减少不必要的内存拷贝,实现更高效率的传输
- 内存池设计:申请的内存(直接内存)可以重用
- 串行化处理读写:避免了使用锁带来的开销
- 高性能序列化协议。
线程模型:
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池 boss线程池和work线程池
- boss线程池:负责处理请求的accept事件,当接收到 accept 事件的请求时,把对应的 socket 封装到一个 NioSocketChannel 中,并交给 worker 线程池。
- work线程池:负责处理请求read和write,由对应的Handler 处理。
Reactor模式:
Reactor模式是事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。
从结构上有点类似生产者消费者,每当一个Event输入到Service Handler之后,该Service Handler会立刻根据不同的Event类型将其分发给对应的Request Handler来处理。
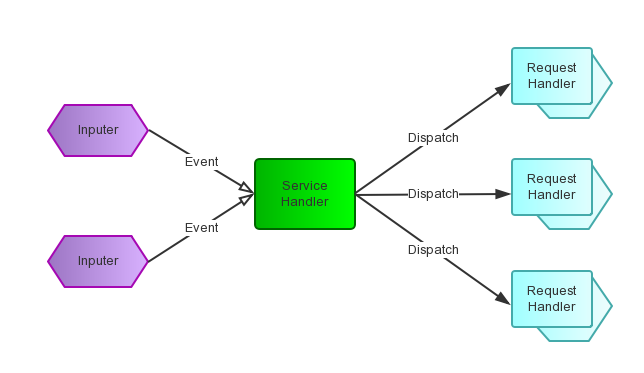
-
单线程模型:所有I/O操作都由一个线程完成,即多路复用、事件分发和处理都是在一个Reactor 线程上完成的。既要接收客户端的连接请求,向服务端发起连接,又要发送/读取请求或应答/响应消息。一个NIO 线程同时处理成百上千的链路,性能上无法支撑,速度慢,若线程进入死循环,整个程序不可用,对于高负载、大并发的应用场景不合适。一个线程(单线程)来处理CONNECT事件(Acceptor),一个线程池来处理read,一个线程池来处理write,那么Reactor Thread 到handler都是异步的。
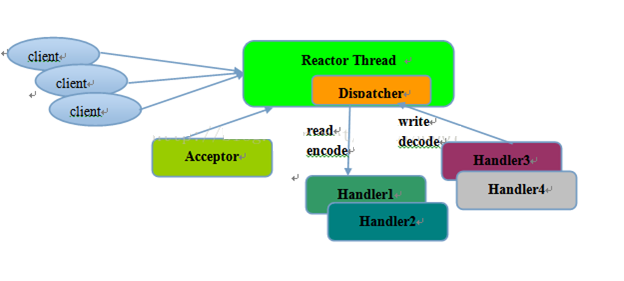
-
多线程模型:有一个NIO 线程(Acceptor) 只负责监听服务端,接收客户端的TCP 连接请求;NIO 线程池负责网络IO 的操作,即消息的读取、解码、编码和发送;1 个NIO 线程可以同时处理N 条链路,但是1 个链路只对应1 个NIO 线程,这是为了防止发生并发操作问题。但在并发百万客户端连接或需要安全认证时,一个Acceptor 线程可能会存在性能不足问题。通过了Reactor Thread Pool来提高了event的分发能力。
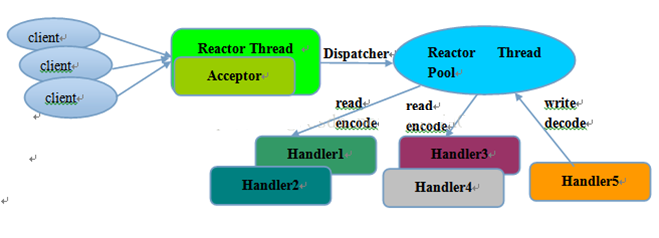
-
主从多线程模型:Acceptor 线程用于绑定监听端口,接收客户端连接,将SocketChannel 从主线程池的 Reactor 线程的多路复用器上移除,重新注册到Sub 线程池的线程上,用于处理I/O 的读写等操作,从而保证 mainReactor 只负责接入认证、握手等操作。
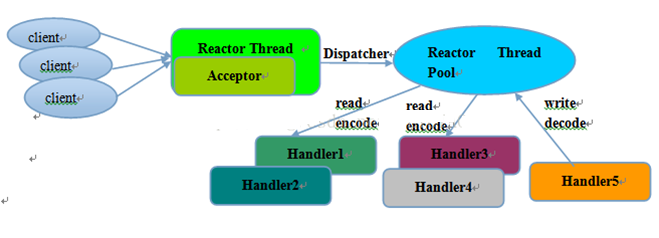
Netty的零拷贝
- Netty的接收和发送的ByteBuffer采用DirectBuffer,使用堆外内存直接Socket读写。相比传统的堆内内存少了一次缓存区拷贝。
- Netty提供了组合Buffer对象,可以聚合多个byteBuffer对象。用户可以像操作一个 Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式将几个小 Buffer 合并成一个大的 Buffer。
- Netty文件传输采用的是TransferTo,它可以直接将文件缓冲区的数据发送到目标 Channel,避免了传统通过循环 write 方式导致的内存拷贝问题
传统的内存拷贝(四次数据拷贝和四次上下文切换)
- (1)数据从磁盘读到内核缓存区(DMA拷贝)
- (2)用户缓存区到用户缓存区
- (3)用户缓存区到socket缓存区
- (4)Socket缓存区到网卡缓存区
FileChannel.TransferTo
- (1)调用transferTo,数据从文件由DMA引擎拷贝到内核read buffer
- (2)接着DMA从内核read buffer将数据拷贝到网卡接口buffer
I/O多路复用模型
- 在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。一个线程,通过记录I/O流的状态来同时管理多个I/O,可以提高服务器的吞吐能力
select、poll、epoll:
select的基本原理:
- 监视文件3类描述符: writefds、readfds、和exceptfds;
- 调用后select函数会阻塞住,等有数据 可读、可写、出异常 或者 超时 就会返回
- select函数正常返回后,通过遍历fdset整个数组才能发现哪些句柄发生了事件,来找到就绪的描述符fd,然后进行对应的IO操作
- 几乎在所有平台支持,跨平台性好
缺点:
- select采用轮询的方式扫描文件描述符,全部扫描,随着文件描述符FD数量增多而性能下降
- 每次调用 select(),需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)
- 最大的缺陷就是单个进程打开的FD有限制,默认是1024 (可修改宏定义,但是效率仍然慢)
poll的基本原理:
- select() 和 poll() 系统调用的大体一样,处理多个描述符也是使用轮询的方式,根据描述符的状态进行处理
- 一样需要把 fd 集合从用户态拷贝到内核态,并进行遍历
- 最大区别是: poll没有最大文件描述符限制(使用链表的方式存储fd)
epoll基本原理:
- 在2.6内核中提出的,对比select和poll,epoll更加灵活,没有描述符限制,用户态拷贝到内核态只需要一次使用事件通知,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用callback的回调机制来激活对应的fd
- 没fd这个限制,所支持的FD上限是操作系统的最大文件句柄数,1G内存大概支持10万个句柄
- 效率提高,使用回调通知而不是轮询的方式,不会随着FD数目的增加效率下降
- 通过callback机制通知,内核和用户空间mmap同一块内存实现
epoll触发
- Leavel-triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
- Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!!
Netty中重要的组件:
- Channel:Netty 网络操作抽象类,它除了包括基本的 I/O 操作,如 bind、connect、read、write 等
- EventLoop:主要是配合 Channel 处理 I/O 操作,用来处理连接的生命周期中所发生的事情。
- ChannelFuture:Netty 框架中所有的 I/O 操作都为异步的,因此我们需要 ChannelFuture 的 addListener()注册一个 ChannelFutureListener 监听事件,当操作执行成功或者失败时,监听就会自动触发返回结果。
- ChannelHandler:充当了所有处理入站和出站数据的逻辑容器。ChannelHandler 主要用来处理各种事件,这里的事件很广泛,比如可以是连接、数据接收、异常、数据转换等。
- ChannelPipeline:为 ChannelHandler 链提供了容器,当 channel 创建时,就会被自动分配到它专属的 ChannelPipeline,这个关联是永久性的。
Netty发送消息的几种方式
- 直接写入 Channel 中,消息从 ChannelPipeline 当中尾部开始移动;
- 写入和 ChannelHandler 绑定的 ChannelHandlerContext 中,消息从 ChannelPipeline 中的下一个 ChannelHandler 中移动
Netty中的责任链
使用场景:
对于一个请求来说,如果有个对象都有机会处理它,而且不明确到底是哪个对象会处理请求时,我们可以考虑使用责任链模式实现它,让请求从链的头部往后移动,直到链上的一个节点成功处理了它为止。
优点:
- 发送者不需要知道自己发送的这个请求到底会被哪个对象处理掉,实现了发送者和接受者的解耦
- 简化了发送者对象的设计
- 可以动态的添加节点和删除节点
缺点:
- 所有的请求都从链的头部开始遍历,对性能有损耗
- 极差的情况,不保证请求一定会被处理
Netty的责任链:
- netty 的 pipeline 设计,就采用了责任链设计模式, 底层采用双向链表的数据结构, 将链上的各个处理器串联起来
- 客户端每一个请求的到来,netty 都认为,pipeline 中的所有的处理器都有机会处理它,因此,对于入栈的请求,全部从头节点开始往后传播,一直传播到尾节点(来到尾节点的 msg 会被释放掉)
责任终止机制:
- 在pipeline中的任意一个节点,只要我们不手动的往下传播下去,这个事件就会终止传播在当前节点
- 对于入站数据,默认会传递到尾节点,进行回收,如果我们不进行下一步传播,事件就会终止在当前节点
Netty的心跳机制:
- 首先 TCP 协议的实现中也提供了 keepalive 报文用来探测对端是否可用。TCP 层将在定时时间到后发送相应的 KeepAlive 探针以确定连接可用性。
- ChannelOption.SO_KEEPALIVE, true 表示打开 TCP 的 keepAlive 设置
- TCP的心跳问题:
考虑一种情况,某台服务器因为某些原因导致负载超高,CPU 100%,无法响应任何业务请求,但是使用 TCP 探针则仍旧能够确定连接状态,这就是典型的连接活着但业务提供方已死的状态,对客户端而言,这时的最好选择就是断线后重新连接其他服务器,而不是一直认为当前服务器是可用状态一直向当前服务器发送些必然会失败的请求。
Netty 中提供了 IdleStateHandler 类专门用于处理心跳:
public IdleStateHandler(long readerIdleTime, long writerIdleTime,
long allIdleTime,TimeUnit unit){
}
- 第一个参数是隔多久检查一下读事件是否发生,如果 channelRead() 方法超过 readerIdleTime 时间未被调用则会触发超时事件调用 userEventTrigger() 方法;
- 第二个参数是隔多久检查一下写事件是否发生,writerIdleTime 写空闲超时时间设定,如果 write() 方法超过 writerIdleTime 时间未被调用则会触发超时事件调用 userEventTrigger() 方法;
- 第三个参数是全能型参数,隔多久检查读写事件;
Zookeeper
CAP定理
- Consistency(一致性):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
- Availability(可用性):在集群中一部分节点故障后,集群整体是否还能响应客户端的请求
- 分区容错性 (Partitiontolerance):系统如果不能再时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C或A之间做出选择。
注:在保证分区容错性的情况下只能保证AP或者CP
BASE
核心思想:BASE是对CAP的一致性和可用性权衡的结果。即使无法保证强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 基本可用(Basically Available):基本可用是指分布系统在出现不可预知故障的时候,允许损失部分可用性。
(1)在响应时间上的损失:正常情况下,一个在线搜索引擎需要再0.5s内返回查询结果,出现异常,允许到2-3s。
(2)功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。 - 软状态Soft state:软状态也称弱状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
- 最终一致性Eventually consistent:最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
服务降级和熔断
服务降级:
概念:整体资源块不够时,忍痛将某些服务先关掉,待度过难关,再开启回来。
服务熔断:
概念:指在软件系统中,由于某些原因使得服务出现过载的现象,为防止造成整个系统的故障,从而采用了一种保护措施,相当于过载保护。
两者的类似性:
- 目的一致性:都是从可用性可靠性着想,为了防止系统的整体缓慢甚至奔溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
-自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
两者的区别:
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始);
- 实现方式不太一样
服务限流 :
- 漏桶算法:将所有请求,保存在一个队列桶中,然后以固定的频率,从桶中取出请求。
- 令牌桶算法:令牌以固定频率向桶中添加令牌,如果桶满了,令牌丢弃。
当有请求进来时,从桶中拿到令牌,才能进行访问。如果拿不到令牌拒绝访问。
两者区别:如果10秒内,没有任何请求,突然进来1万个请求,漏桶算法还是以固定的频率进行请求,而令牌算法桶中如果有1万个令牌,这1万个请求就会都请求成功。后续再有别的请求时,就会被拒绝。令牌桶算法对业务峰值有很好的承载能力。
zookeeper的文件系统:
- Zookeeper 提供一个多层级的节点命名空间(节点称为 znode)。与文件系统不同的是,这些节点都可以设置关联的数据,而文件系统中只有文件节点可以存放数据而目录节点不行。
- Zookeeper 为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存放数据上限为1M。
zookeeper怎么保证主从节点的状态同步:
Zookeeper 的核心是原子广播机制,这个机制保证了各个 server 之间的同步。实现这个机制的协议叫做 Zab 协议。Zab 协议有两种模式,它们分别是恢复模式和广播模式。
- 恢复模式:当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数 server 完成了和 leader 的状态同步以后,恢复模式就结束了。状态同步保证了 leader 和 server 具有相同的系统状态。
- 广播模式:一旦 leader 已经和多数的 follower 进行了状态同步后,它就可以开始广播消息了,即进入广播状态。这时候当一个 server 加入 ZooKeeper 服务中,它会在恢复模式下启动,发现 leader,并和 leader 进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper 服务一直维持在 Broadcast 状态,直到 leader 崩溃了或者 leader 失去了大部分的 followers 支持。
服务器角色:
-
Leader:
(1)事务请求的唯一调度和处理者,保证集群事务处理的顺序性
(2)集群内部各服务的调度者 -
Follower:
(1)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(2)参与事务请求 Proposal 的投票
(3)参与 Leader 选举投票 -
Observer
(1)3.0 版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
(2)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(3)不参与任何形式的投票
几种常用的注册中心
- Zookeeper:(CP)即任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是 Zookeeper 不能保证每次服务请求都是可达的。
- Spring Cloud Eureka :(AP)Eureka Server 采用的是Peer to Peer 对等通信。这是一种去中心化的架构,无 master/slave 之分,每一个 Peer 都是对等的。
- Nacos:(AP+CP)
Dubbo
Dubbo使用的序列化框架
- Hessian
- Duddo
- FastJson
- Java自带
集群容错方案
- Failover Cluster :失败自动切换,自动重试其他服务器
- Failfast Cluster:快速失败,立即报错,只发生一次调用
- Failsafe Cluster:失败安全,出现异常时,直接忽略
- Failback Cluster:失败自动恢复,记录失败请求,定时重发
- Forking Cluster:并行调用多个服务器,只要一个成功就返回
- Broadcast Cluster:广播逐个调用所有提供者,任意一个失败则报错
java基础
java元注解
- @Retention:这个注解的存活时间
- @Documented:能够将注解中的元素包含到javadoc中
- @Target 指定注解运行的地方
- @Inherited 继承的意思
- @Repeatable 表示可重复的
HashMap
- 数据结构:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
- 重写equals,只有k, V 都相等才可以
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
- hash 定位桶
static final int hash(Object key) {
int h;
// 1、先拿到key的hashcode
// 2、将hashcode的高16位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
int n = tab.length;
// 将(tab.length - 1) 与 hash值进行&运算
int index = (n - 1) & hash;
将 hashCode 的高 16 位与 hashCode 进行异或运算,主要是为了在 table 的 length 较小的时候,让高位也参与运算,并且不会有太大的开销。降低hash冲突
- get 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1.对table进行校验:table不为空 && table长度大于0 &&
// table索引位置(使用table.length - 1和hash值进行位与运算)的节点不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 2.检查first节点的hash值和key是否和入参的一样,如果一样则first即为目标节点,直接返回first节点
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 3.如果first不是目标节点,并且first的next节点不为空则继续遍历
if ((e = first.next) != null) {
if (first instanceof TreeNode)
// 4.如果是红黑树节点,则调用红黑树的查找目标节点方法getTreeNode
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 5.执行链表节点的查找,向下遍历链表, 直至找到节点的key和入参的key相等时,返回该节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
// 6.找不到符合的返回空
return null;
}
红黑树查找
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
// 1.将p节点赋值为调用此方法的节点,即为红黑树根节点
TreeNode<K,V> p = this;
// 2.从p节点开始向下遍历
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
// 3.如果传入的hash值小于p节点的hash值,则往p节点的左边遍历
if ((ph = p.hash) > h)
p = pl;
else if (ph < h) // 4.如果传入的hash值大于p节点的hash值,则往p节点的右边遍历
p = pr;
// 5.如果传入的hash值和key值等于p节点的hash值和key值,则p节点为目标节点,返回p节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null) // 6.p节点的左节点为空则将向右遍历
p = pr;
else if (pr == null) // 7.p节点的右节点为空则向左遍历
p = pl;
// 8.将p节点与k进行比较
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) && // 8.1 kc不为空代表k实现了Comparable
(dir = compareComparables(kc, k, pk)) != 0)// 8.2 k<pk则dir<0, k>pk则dir>0
// 8.3 k<pk则向左遍历(p赋值为p的左节点), 否则向右遍历
p = (dir < 0) ? pl : pr;
// 9.代码走到此处, 代表key所属类没有实现Comparable, 直接指定向p的右边遍历
else if ((q = pr.find(h, k, kc)) != null)
return q;
// 10.代码走到此处代表“pr.find(h, k, kc)”为空, 因此直接向左遍历
else
p = pl;
} while (p != null);
return null;
}
- put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1.校验table是否为空或者length等于0,如果是则调用resize方法进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2.通过hash值计算索引位置,将该索引位置的头节点赋值给p,如果p为空则直接在该索引位置新增一个节点即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
// table表该索引位置不为空,则进行查找
Node<K,V> e; K k;
// 3.判断p节点的key和hash值是否跟传入的相等,如果相等, 则p节点即为要查找的目标节点,将p节点赋值给e节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4.判断p节点是否为TreeNode, 如果是则调用红黑树的putTreeVal方法查找目标节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 5.走到这代表p节点为普通链表节点,则调用普通的链表方法进行查找,使用binCount统计链表的节点数
for (int binCount = 0; ; ++binCount) {
// 6.如果p的next节点为空时,则代表找不到目标节点,则新增一个节点并插入链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 7.校验节点数是否超过8个,如果超过则调用treeifyBin方法将链表节点转为红黑树节点,
// 减一是因为循环是从p节点的下一个节点开始的
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 8.如果e节点存在hash值和key值都与传入的相同,则e节点即为目标节点,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; // 将p指向下一个节点
}
}
// 9.如果e节点不为空,则代表目标节点存在,使用传入的value覆盖该节点的value,并返回oldValue
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 用于LinkedHashMap
return oldValue;
}
}
++modCount;
// 10.如果插入节点后节点数超过阈值,则调用resize方法进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 用于LinkedHashMap
return null;
}
1.校验 table 是否为空或者 length 等于0,如果是则调用 resize 方法进行初始化,见resize方法详解。
2.如果 p 节点不是目标节点,则判断 p 节点是否为 TreeNode,如果是则调用红黑树的 putTreeVal 方法查找目标节点,见代码块4详解。
3.校验节点数是否超过 8 个,如果超过则调用 treeifyBin方法 将链表节点转为红黑树节点,
- 红黑树数据结构:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
// ...
}
- resize
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 1.老表的容量不为0,即老表不为空
if (oldCap > 0) {
// 1.1 判断老表的容量是否超过最大容量值:如果超过则将阈值设置为Integer.MAX_VALUE,并直接返回老表,
// 此时oldCap * 2比Integer.MAX_VALUE大,因此无法进行重新分布,只是单纯的将阈值扩容到最大
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 1.2 将newCap赋值为oldCap的2倍,如果newCap<最大容量并且oldCap>=16, 则将新阈值设置为原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 2.如果老表的容量为0, 老表的阈值大于0, 是因为初始容量被放入阈值,则将新表的容量设置为老表的阈值
else if (oldThr > 0)
newCap = oldThr;
else {
// 3.老表的容量为0, 老表的阈值为0,这种情况是没有传初始容量的new方法创建的空表,将阈值和容量设置为默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 4.如果新表的阈值为空, 则通过新的容量*负载因子获得阈值
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 5.将当前阈值设置为刚计算出来的新的阈值,定义新表,容量为刚计算出来的新容量,将table设置为新定义的表。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 6.如果老表不为空,则需遍历所有节点,将节点赋值给新表
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) { // 将索引值为j的老表头节点赋值给e
oldTab[j] = null; // 将老表的节点设置为空, 以便垃圾收集器回收空间
// 7.如果e.next为空, 则代表老表的该位置只有1个节点,计算新表的索引位置, 直接将该节点放在该位置
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 8.如果是红黑树节点,则进行红黑树的重hash分布(跟链表的hash分布基本相同)
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 9.如果是普通的链表节点,则进行普通的重hash分布
Node<K,V> loHead = null, loTail = null; // 存储索引位置为:“原索引位置”的节点
Node<K,V> hiHead = null, hiTail = null; // 存储索引位置为:“原索引位置+oldCap”的节点
Node<K,V> next;
do {
next = e.next;
// 9.1 如果e的hash值与老表的容量进行与运算为0,则扩容后的索引位置跟老表的索引位置一样
if ((e.hash & oldCap) == 0) {
if (loTail == null) // 如果loTail为空, 代表该节点为第一个节点
loHead = e; // 则将loHead赋值为第一个节点
else
loTail.next = e; // 否则将节点添加在loTail后面
loTail = e; // 并将loTail赋值为新增的节点
}
// 9.2 如果e的hash值与老表的容量进行与运算为非0,则扩容后的索引位置为:老表的索引位置+oldCap
else {
if (hiTail == null) // 如果hiTail为空, 代表该节点为第一个节点
hiHead = e; // 则将hiHead赋值为第一个节点
else
hiTail.next = e; // 否则将节点添加在hiTail后面
hiTail = e; // 并将hiTail赋值为新增的节点
}
} while ((e = next) != null);
// 10.如果loTail不为空(说明老表的数据有分布到新表上“原索引位置”的节点),则将最后一个节点
// 的next设为空,并将新表上索引位置为“原索引位置”的节点设置为对应的头节点
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 11.如果hiTail不为空(说明老表的数据有分布到新表上“原索引+oldCap位置”的节点),则将最后
// 一个节点的next设为空,并将新表上索引位置为“原索引+oldCap”的节点设置为对应的头节点
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 12.返回新表
return newTab;
}
CAS
参数:内存地址:V,旧的预期值A,即将更新的目标值。
缺点:
- 循环时间长开销大:CAS失败会一直尝试
- 只能保证一个变量的原子操作。
- ABA问题
volatile:
happens-before
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁lock操作
- volatile变量规则:对一个变量的写操作先于后面对这个变量的读操作
- 传递规则:如果操作A先于操作B,B先于C,则A先于C
MySQL
计算机网络
输入URL过程
URL检查-->域名解析-->TCP三次握手-->建立TCP三次连接-->服务器响应http请求,浏览器得到HTML代码-->浏览器解析HTML代码中的资源-->页面渲染
应用层
DNS解析过程
- 检查浏览器DNS缓存
- 操作系统DNS缓存
- 读取hosts文件
- 发起DNS的系统调用,发起域名解析请求
计算机操作系统
虚拟内存
1.为什么要有虚拟内存?
1.因为我们得到的物理内存都是有限的,每个进程都要执行的时候都给所有内存,很显然不够用,于是没有分配资源的进程只能等待。当一个进程执行完以后,再讲等待的进程装进内存,是很没有效率的。
2.由于指令都是直接访问物理内存的,那么这个进程就可以修改其他进程的数据
3.因为内存是随机分配的,所以程序运行的地址也是不正确的
2.虚拟内存的概念
进程得到的虚拟内存是一个连续的地址空间(进程认为的),实际上,它通常是被分隔成多个物理内存碎片,还有一部分存储在外部磁盘存储器上,在需要时进行数据交换。
3.虚拟内存是如何工作的?
当每个进程创建的时候,内存会在进程分配4G的虚拟内存,当进程还没有开始运行的时候,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射关系(存储器映射)。这个时候数据和代码都还在磁盘上,当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存中,从磁盘上将数据拷贝到物理内存中,mmap是用来建立虚拟空间和磁盘空间的映射关系。
物理地址和逻辑地址
物理地址:
加载到内存地址寄存器中的地址,内存单元的真正地址。0~2^64。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查。
逻辑地址:
CPU所生成的地址,逻辑地址是内存和编程使用的。要经过寻址方式的计算或变换才得到内存储器中的实际有效地址即物理地址。一个逻辑地址由两部份组成,段标识符: 段内偏移量。
线性地址(虚拟地址):
是逻辑地址到物理地址变换之间的中间层。CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线程地址,再利用其页式内存管理单元,转换为最终物理地址。
快表:
为了解决虚拟地址到物理地址的转换速度,操作系统在页表方案的基础上引入了快表来加速虚拟地址到物理地址的转换。就是一个缓存机制:
1.根据虚拟地址中的页号查找页号查快表
2.如果该页在快表中,直接从快表中读取相应的物理地址
3.如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中
4.当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页
多级页表:
引入多级页表的主要目的是为了避免把全部页表一直放在内存中占用过多空间,时间换空间。
局部性原理:
1.时间局部性:如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某条数据被访问过,不久以后该数据可能再次被访问。由于程序中存在大量的额循环操作
2.空间局部性:一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之类,这是因为指令通常是顺序存放的、顺序执行的。
时间局部性是通过将近来使用的指令和数据保存到高速缓存存储器中,并使用高速缓存的层次结构实现。空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
虚拟存储器:
基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其他部分留在外存,就可以启动程序执行。由于外存往往比内存大很多,所以我们运行的软件的内存大小实际上是可以比计算机系统实际的内存大小大的。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换到外存上,从而腾出空间存放将要调入内存的信息。这样,计算机好像为用户提供了一个比实际内存大的多的存储器——虚拟存储器。
设计模式
六大原则:
- 开闭原则:多扩展开放,对修改关闭
- 里氏替换原则:不能更改父类中的方法
- 依赖倒置原则:面向接口编程
- 单一职责原则:一个类只负责一个功能领域中相应的职责
- 接口隔离原则
- 迪米特法则:一个类尽可能少的与其他类发生作用














 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









