







问题提出:
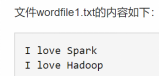
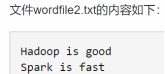
假设HDFS中/user/hadoop/input文件夹下有文件wordfile1.txt和wordfile2.txt。现在需要设计一个词频统计程序,统计input文件夹下所有文件中每个单词的出现次数。

运行过程:
1.Map操作的输入是<key,value>形式,即key是文档中的行号,value是改行的内容
map第一个任务:
<1,I love spark>
<2,I love hadoop>
map第二个任务:
<1,hadoop is good>
<2,spark is fast>
分别做计算(map函数体):功能 按照空格分割出孤立的单词,以<key,value>的形式作为中间结果进行输出
Eg1:
I,1
love,1
spark,1
I,1
love,1
hadoop,1
map端的shuffle(如果用户没有定义combiner函数,把具有相同的key的键值对归并成一个键值对),输出 <key,list>形式
(输入数据和执行map任务,写入缓存-磁盘,溢写(分区,排序,合并),文件归并(是文件变小))
以下为定义了combiner函数:
第一个map任务合并后结果
<I,2><love,2><spark,1><hadoop,1>
第二个map任务合并后结果
<hadoop,1><spark,1><fast,1><good,1><is,2>
第一个map任务归并后结果
无
第二个map任务归并后结果
无
Map输出:
<I,2><love,2><spark,1><hadoop,1>
<hadoop,1><spark,1><fast,1><good,1><is,2>
2.Reduce(几个key对应几个reduce)—shuffle端:领取数据,归并,把数据输入给reduce任务
第一个reduce任务:计算key为I的任务
第二个reduce任务:计算key为hadoop的任务
…
<hadoop,1><hadoop,1> -> <hadoop,List<1,1>> -> 做reduce函数体(功能:词频加和)
reduce输出
<I,2><hadoop,2>...














 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









