






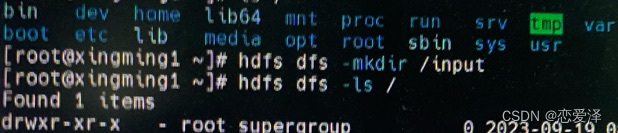
hdfs dfs -mkdir /input
在自己名字文件添加内容 可以用ls查看内容复制进去加入自己名
vi sunrenze.txt
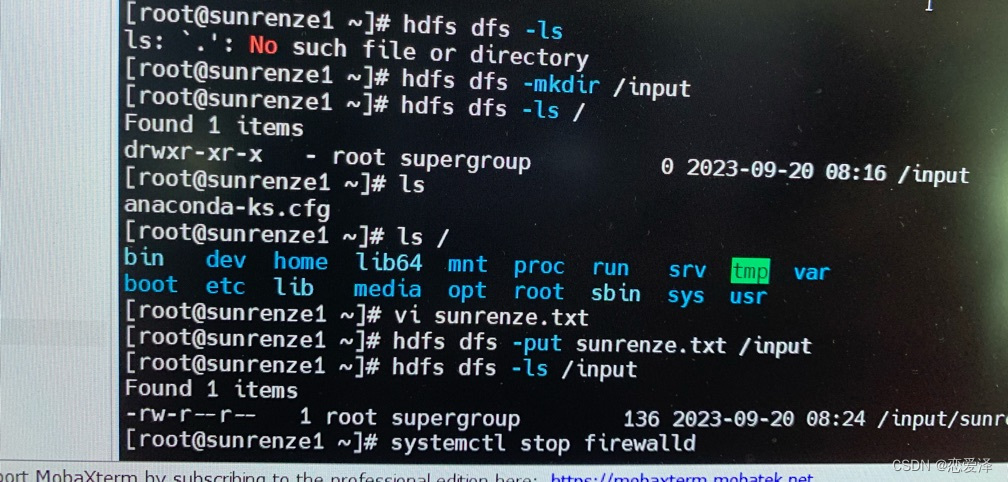
编写完成后hdfs dfs -put sunrenze.txt /input
查看
hdfs dfs -ls /input
查看
ls /opt/module/hadoop-3.3.1/tmp/dfs/data/current/
启用包
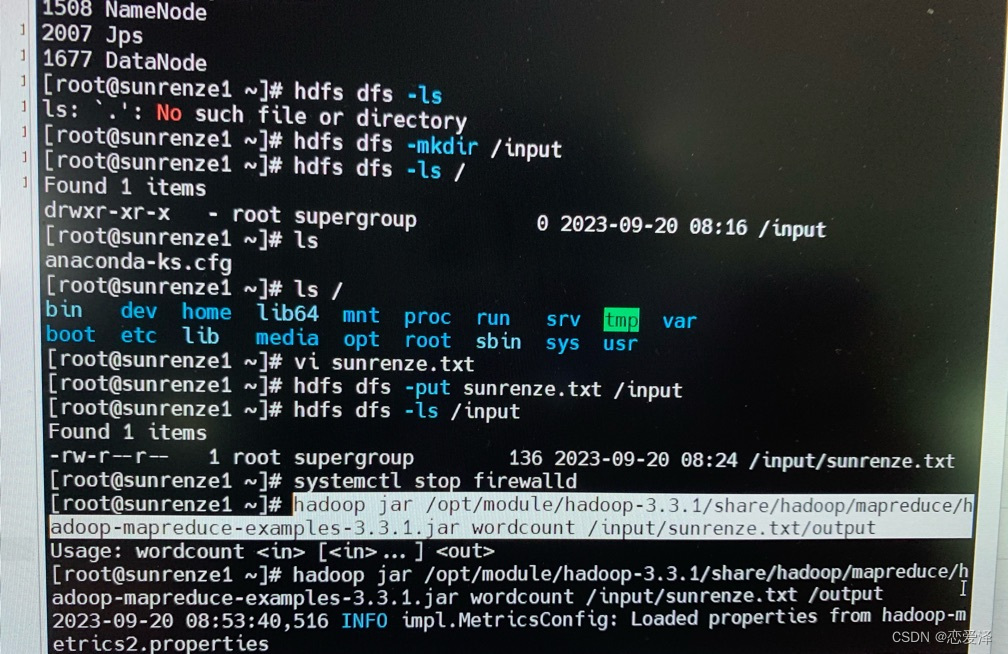
hadoop jar /opt/module/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input/yinxin.txt /output
查看output
hdfs dfs -ls /output
执行
hdfs dfs -cat /output/part-r-00000
就会出现统计
然后继续编辑 hadoop env 记得切换回目录
vi hadoop-env.sh
内容
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
编辑
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
编辑
vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









