






引入datetime包
import datetime
写入日期:
datetime.datetime.strptime('2001-01-01','%Y-%m-%d')

但是这种方法需要同时写出日期的格式,十分麻烦,有没有一种方法可以自动识别日期格式的呢?答案是有的。
引入 dateutil包:
import dateutil
写入日期:
dateutil.parser.parse('2001-01-01')

甚至月份在前、月份是英文缩写都可以被识别:
dateutil.parser.parse('JAN-03-2001')

接下来是时间对象的生成:
使用pandas的date_range函数,最基本的两个参数是开始时间和结束时间:
pd.date_range('2000-01-01','2010-01-01')
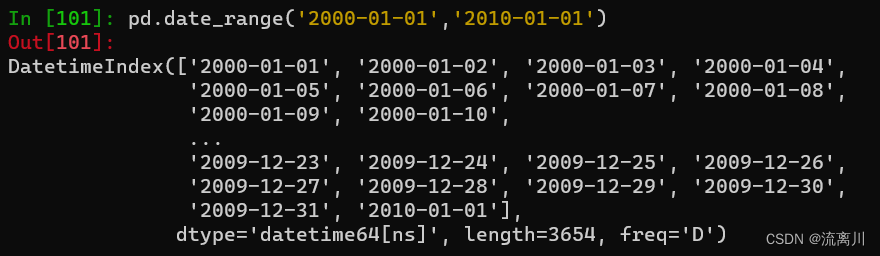
生成从2000年1月1日到2010年1月1日中所有的日期对象。
加入periods参数,生成开始时间后一个周期内所有日期对象:
pd.date_range('2000-01-01',periods=30)
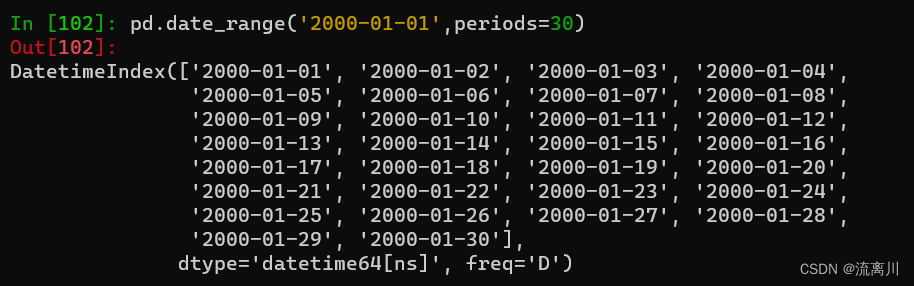
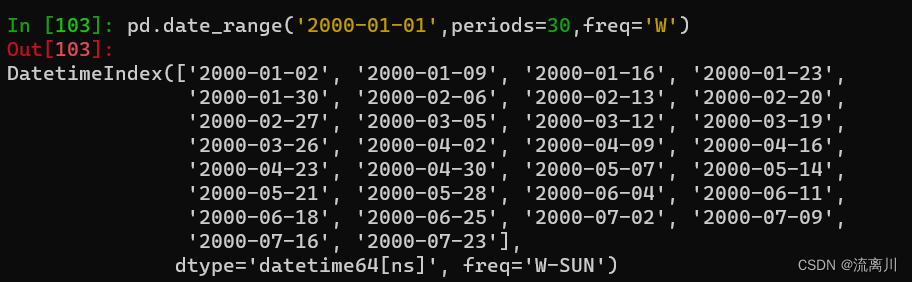
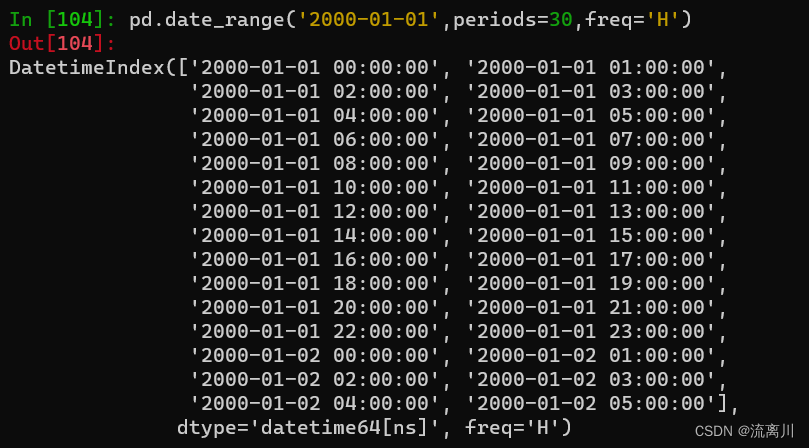
继续加入freq(频率)参数,无freq参数时默认值为D(天),W代表在范围内生成以周为频率的日期对象,H代表小时,B代表非工作日,W-MON代表周一,甚至3h1
0min也是可以的:
pd.date_range('2000-01-01',periods=30,freq='W')
pd.date_range('2000-01-01',periods=30,freq='H')
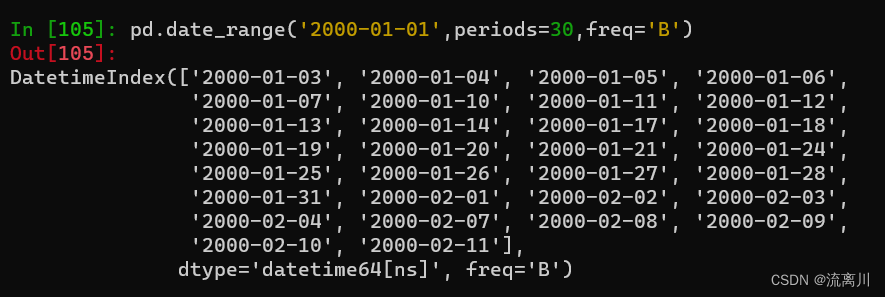
pd.date_range('2000-01-01',periods=30,freq='B')
pd.date_range('2000-01-01',periods=30,freq='W-MON')

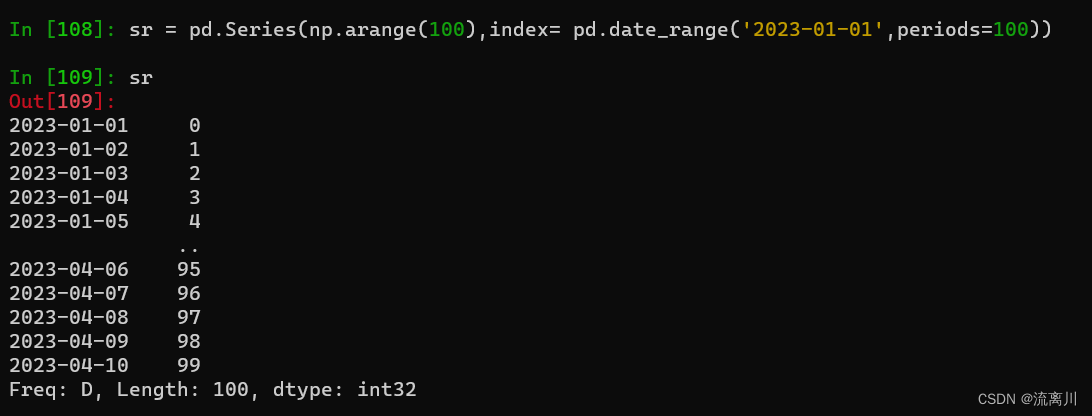
将创建好的时间对象放进Series中:
sr = pd.Series(np.arange(100),index= pd.date_range('2023-01-01',periods=100))
接下来是时间对象的搜索:
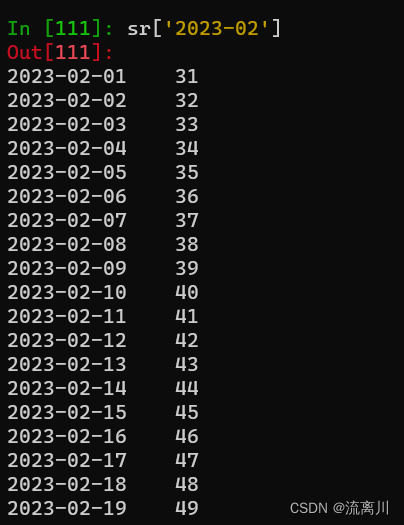
搜索2023年2月的所有数据:
sr['2023-02']
还可以搜索范围日期:
sr['2023-02-01':'2023-03-02']
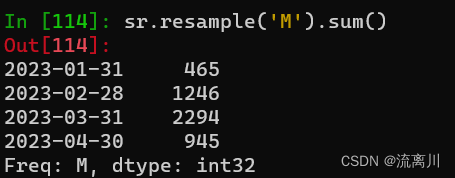
查看某个时间周期内的统计数据,如查看每月的销售额之和:
sr.resample('M').sum()
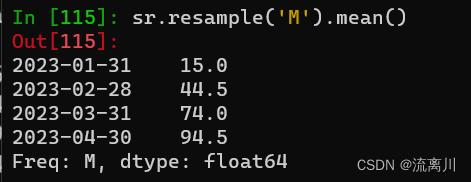
如查看每月的平均销售额:
sr.resample('M').mean()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











