







1.什么是组函数?
其实,可能你用过组函数但是不太了解这个概念,组函数是相对于单行函数而言的,前面的使用的各种查询或者是一些基本的类型转换函数、各种对于字符类型和number类型的操作函数等,都是针对于一条具体的函数记录而言的,组函数则是针对于多条函数而言的。比如组函数中的sum、count等函数。是在数据表中针对多条数据进行就和或者计数等。需要明确一点:所有的组函数都忽略空值,但是可以使用前面提到的NVL、NVL2、NULLIF和COALESCE函数来友好的规避掉空值。
2.常用的组函数
| 函数 | 描述 |
|---|---|
| avg | 对分组数据取平均值 |
| sum | 对分组数据求和 |
| min | 求分组数据中的最小值 |
| max | 求分组数据中的最大值 |
| count | 求分组数据的总数 |
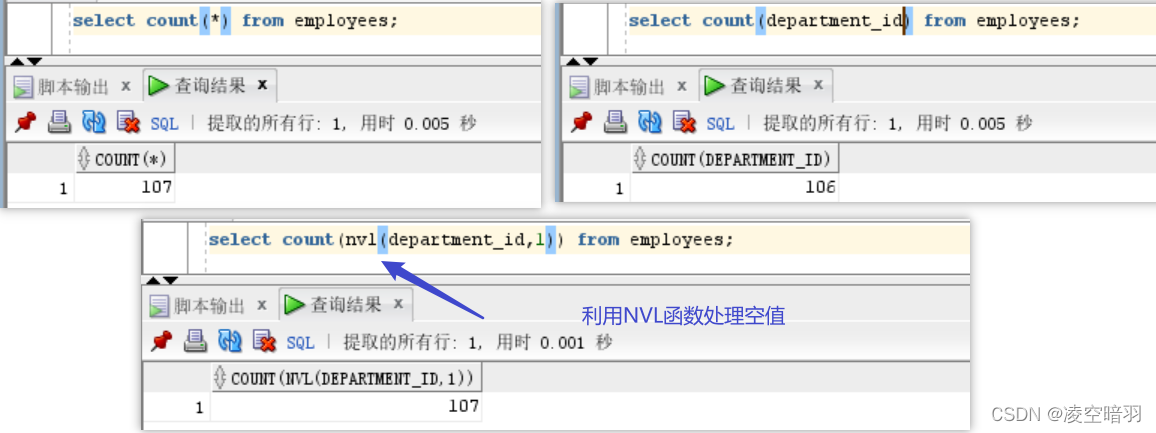
说明:count如果只是想拿到数据的条数,推荐使用count(*),因为如果count的时候指定了字段,比如count(department_id),该字段如果在某条记录中为空,那么对应的条数会比实际的条数更少,而count(*)除非该记录都是空值才不计数。当然如果需要找分配了部门的职员数也可以直接使用count(department_id)。另外,如果单纯想拿到部门数,可以使用count( destinct department_id)。这里给出一个利用NVL处理空值的例子:
3.group by分组
前面的函数对数据的操作都是整个表的操作,我们也可以使用group by自定义分组来处理数据。需要注意的是:
(1)group_by分组是在数据处理完成之后进行的,可以和where同时使用;
(2)group_by中不能使用别名;
(3)group_by分组必须和分组函数一起使用,否则group_by就失去意义报错;
(4)group_by的分组结果默认采用升序排列(这个只能先记住了,不太好测试),可以使用order by来修改排序规则。
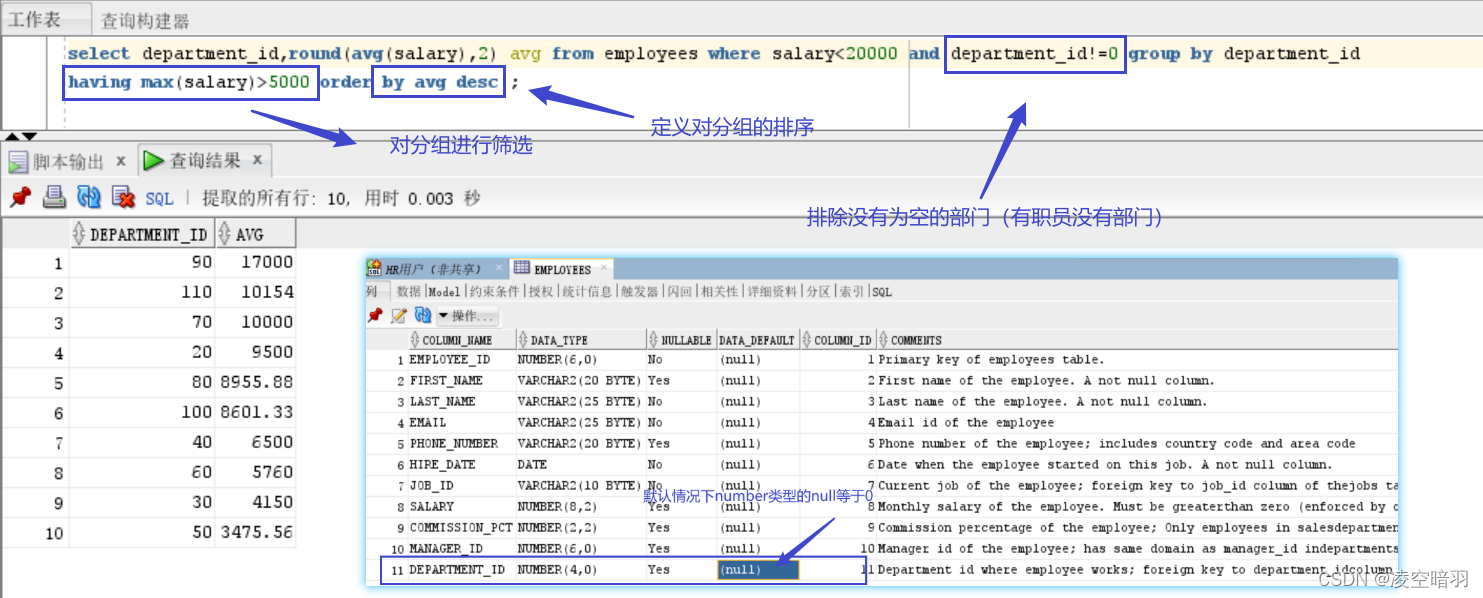
(5)虽然group_by可以和where一起使用,但是其实是使用where过滤之后再来分组的,不能够使用where对各个分组进行刷选。于是就出现了having关键字,用来实现对分组的筛选,举例如下:
4.分组查询与子查询
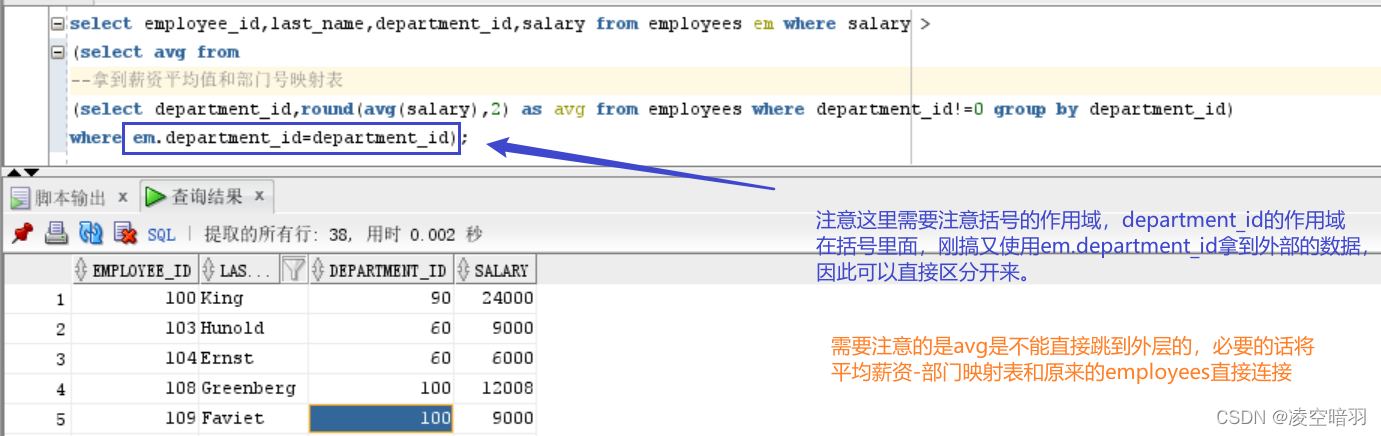
分组查询和子查询配合使用还是比较广泛的,使用方式如下(1)基本使用,举例:得到某个部门中薪资高于该部门平均薪资的职员信息:
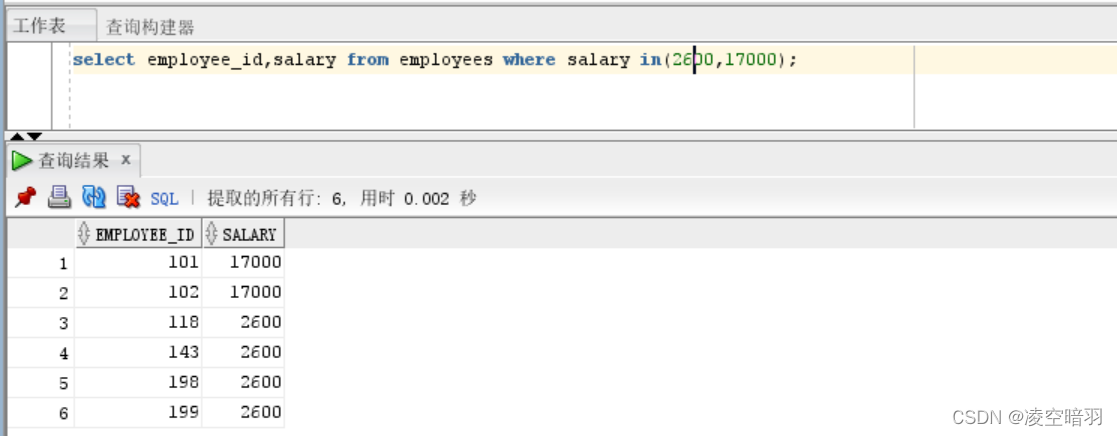
(2)IN关键字的使用,使用方法比较好理解,查询目标字段是否在某个范围中(数组范围):
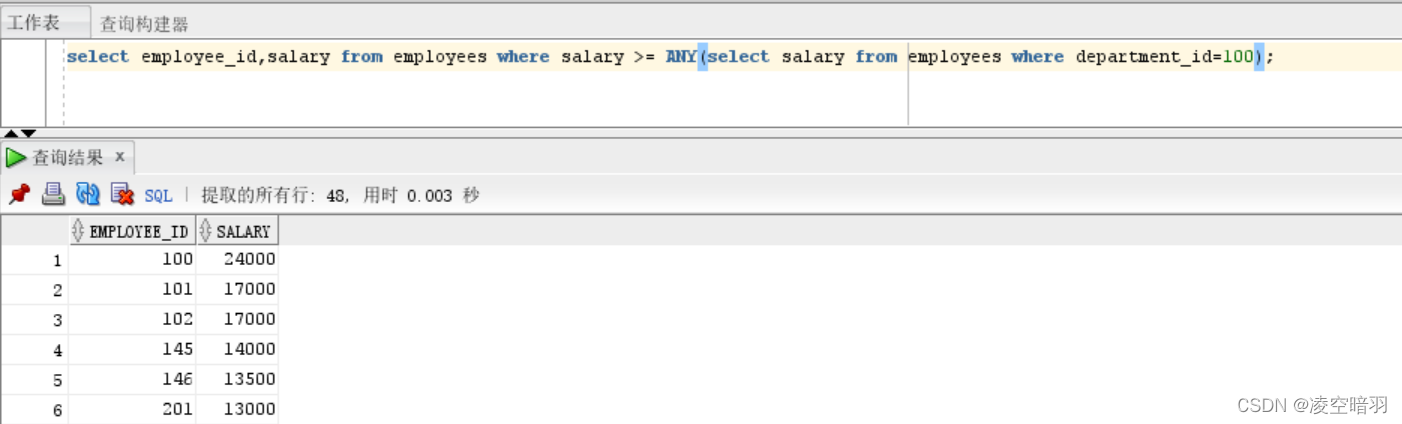
(3)ANY关键字的使用,查询目标字段是否能够符合给定条件中的任意一个:
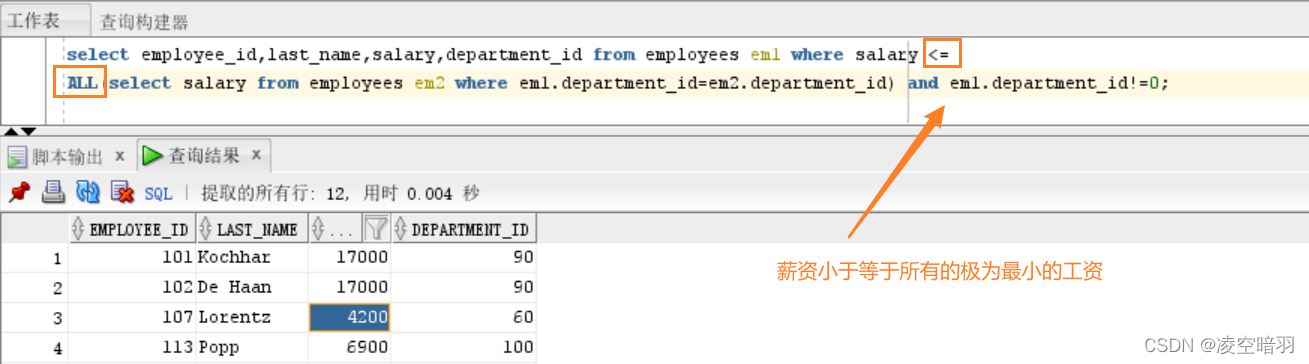
(4)ALL关键字的使用,举例:得到某部门(需要含有部门)中雇员的最低薪资情况:
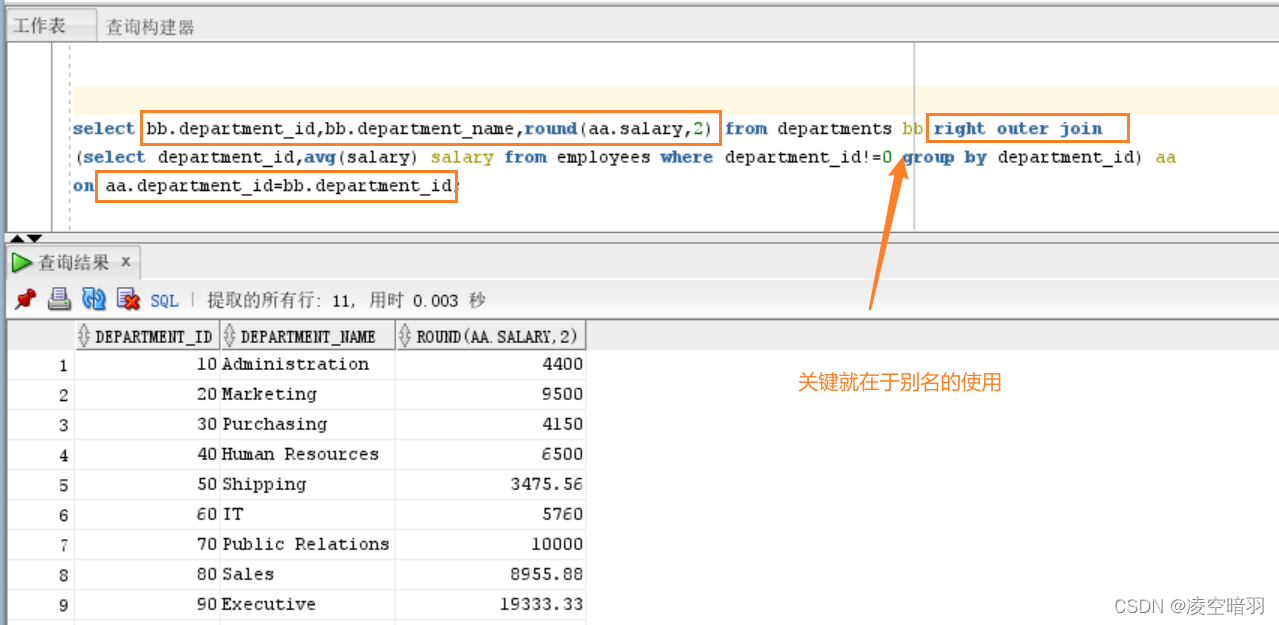
(5)最后,有一个有意思一点的查询要求。举例:得到各部门(需含有雇员)的平均薪资以及部门信息情况,这个当时还是纠结了很久的,后来在数据库老师的提点下实现了,关键就在于可以把查询结果赋予临时表名,这样就能够利用数据库进行的连接语法实现:















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











