







 相关知识RDD介绍RDD是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性。 在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用 RDD操作进行求值。RDD结构图RDD具有五大特性: 一组分片(Partition),即数据集的基本组成单...
相关知识RDD介绍RDD是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性。 在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用 RDD操作进行求值。RDD结构图RDD具有五大特性: 一组分片(Partition),即数据集的基本组成单...
- 相关知识
RDD介绍
RDD是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性。 在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用 RDD操作进行求值。
RDD结构图
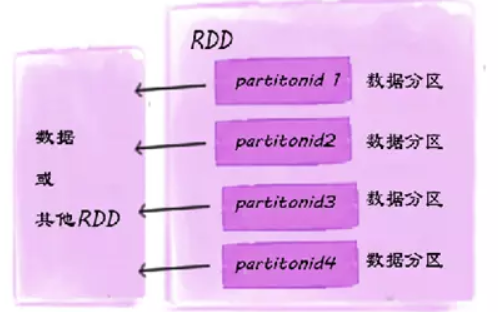
RDD具有五大特性:
-
一组分片(
Partition),即数据集的基本组成单位(RDD是由一系列的partition组成的)。将数据加载为RDD时,一般会遵循数据的本地性(一般一个HDFS里的block会加载为一个partition)。 -
RDD之间的依赖关系。依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









