






hue工具介绍
HUE是CDH提供一个hive和hdfs的操作工具,在hue中编写了hiveSQl也可以操作hdfs的文件
http://hadoop01:9870 hdfs的web访问端口
hdfs://hadoop01:8020 hdfs的程序访问端口






数仓介绍
数据仓库是由一整套体系构成,包含数据采集,数据存储,数据计算,数据展示等
数据仓库主要作用对过往的历史数据进行分析处理,为公司决策停供数据支撑。
数仓特征
- 面向主题
- 集成性
- 非易失性
- 时变性
OLTP和OLAP
OLTP(On-Line Transaction Processing)即联机事务处理,也称为面向交易的处理过程,
OLAP(On-Line Analytical Processing)即联机分析处理,有时也称为决策支持系统(DSS)
| id | name | address | dt |
| 1 | 张三 | 北京 | 2023-5-7 |
| 2 | 张三 | 上海 | 2024-2-2 |
ETL
ETL(Extra, Transfer, Load)包括数据抽取、数据转换、数据导入三个过程。
主题和主题域
主题和主题域介绍
主题是对数据进行归类,每个分类是一个主题
主题域根据分析的领域,将联系较为紧密的数据主题的集合在一起
主题域下面可以有多个主题,主题还可以划分成更多的子主题,主题和主题之间的建设可能会有交叉现象
主题域的划分
- 按照系统划分
- 生产系统 生产主题域
- 商品原材料库存核销数据 商品主题
- 订单主题
- 财务系统
- 商品原材料库存核销数据 商品主题
- 销售主题
- 人力系统
- 生产系统 生产主题域
- 按照部门划分
- 人力部门 人力主题域
- 员工主题 员工数据
- 招聘主题 招聘数据
- 生产部门
- 销售部门
- 后勤部门
- 人力部门 人力主题域
- 按照业务划分
- 门店零售业务
- 批发业务
- 团购业务
- 按照行业经验
- 银行证券业
- 当事人、产品、协议、事件、资产、财务、机构、地域、营销、渠道
- 银行证券业
黑马甄选是按照业务功能划分主题域
核销 、售卖、会员、库存、订单
公司由数据分析师和数据产品经理根据公司业务场景设计主题,搭建分析的指标体系,形成指标文档
数据仓库和数据集市
数据集市
就是数据仓库`的一个子集,它主要面向部门级业务,并且只面向某个特定的主题
数据集市由业务部门定义、设计和开发,业务部门进行管理和维护

数仓设计
定义设计规范
- 表命名
分层_主题_实体+业务+维度_分区
分层 ods,dw,dwd
主题 sale(销售主题) user(用户主题)
实体+业务+维度
- 示例:
- store_goods_statistics_day
- store_member_statistics_day
- mysql中的表名+计算维度
ods_sale_store_goods_statistics_day_dt
规范不是前置要求,不同公司可能根据业务设计表名
- 字段类型规范
- 数量类型整数为bigint
- 金额类型为decimal(27, 2),表示:27位有效数字,其中小数部分2位
- 数量类型小数为decimal(27, 3),表示:27位有效数字,其中小数部分3位
- 字符串(名字,描述信息等)类型为string
- 日期类型为string
- 时间类型为timestamp
黑马甄选按照当前设计给进行设计
数仓分层设计
数据仓库最基础分层 ,分层本质就是创建不同的数据库,
原始数据层 ODS
- 将数据源的数据导入数仓ods层
- 创建一个ods的数据库,然后按照数据源中的表创建ods库下的hive表
数据仓库层 DW 数据处理
数据服务层 ADS 计算结果
数据分层设计到的有什么作用?
- 简化复杂问题。
- 通过将复杂的数据处理过程分解为多个步骤或层次,可以使问题更加易于理解和处理。
- select sum(age) from tb1 join tb2 on tb1.id =tb2.id where age > 20 group by gender
- 结构更清晰。
- 每个数据层都有其明确的作用域,这有助于在使用表时方便地定位和理解。
- 数据血缘追踪。
- 分层结构使得数据血缘关系更加明确,便于追踪和调试。
- 用空间换时间。
- 通过预处理大量数据,可以提高应用系统的用户体验(效率),虽然这可能导致数据仓库中存在冗余数据。
- 数据重复使用,减少重复开发。
- 规范的数据分层可以促进数据和指标的统一,减少重复开发,并提高数据复用率。
- 数据隔离和屏蔽原始数据异常。
- 分层结构可以帮助隔离原始数据的异常或敏感性,保护真实数据与统计数据解耦。
- 数据安全。
- 通过分层,可以更方便地对不同层的数据进行权限管理,屏蔽敏感数据。
- 增强扩展性和便于后期维护。
- 不分层可能会导致整个数据清洗过程受到源业务系统规则变化的影响,而分层可以简化数据清洗过程,提高扩展性,便于后期维护。

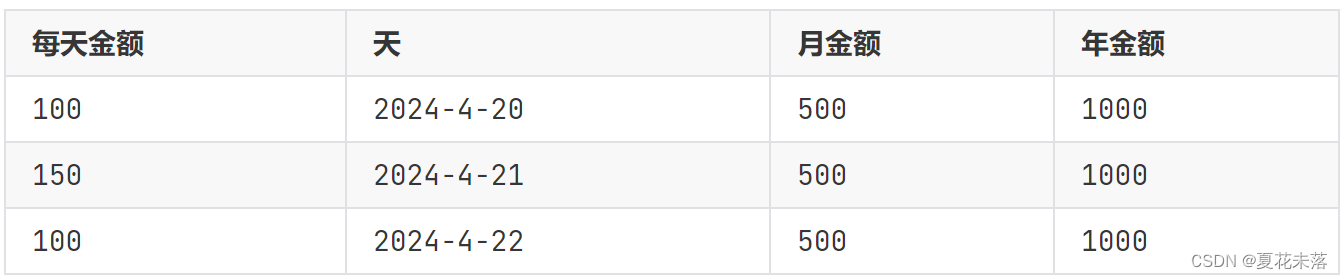
group by substr(2024-04-20,1,4)
在黑马甄选中,维度表数据比较多,单独创建了一个DIM层用来处理维度表数据
数仓建模设计
数仓建模本质就是在数仓中如何设计表存储计算数据
数仓一般采用维度建模方式来设计不同的表
维度模型是Ralph Kimall所倡导,他的《数据仓库工具箱》是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。

粗粒度 123819023809,3,5000,
细粒度 123819023809,小米手机 红色 12G+256G,3999,1
在DWD层确认维度表和事实表,然后将事实表和维度表数据进行管理
在DWM层进行主题宽表关联
星状模型
每个事实表都自己独立的维度表,会造成重复创建维度表

雪花模型

星座模型
多个事实表可以关联相同的维度表

项目中采用星座模型
DIM维度层数据处理
维度表介绍

DIM层表数据处理
hive表的中文问题解决
在mysql中执行如下语句
use hive;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;

创建DIM层表
创建原始数据表,根据mysql中的维度表字段数据创建dim层中表数据
表需要进行分区,一天为单位进行分区保存数据
-- 查看建表语句
show create table 表名


导入dataxweb任务
启动服务
/export/server/datax-web-2.1.2/bin/start-all.sh


执行datax任务导入ods原始表数据


处理维度表数据
hive的配置
-- 开启动态分区方案
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开启动态分区支持(默认true)
set hive.exec.dynamic.partition=true;
-- 设置各个节点生成动态分区的最大数量: 默认为100个 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions.pernode=10000;
-- 设置最大生成动态分区的数量: 默认为1000 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions=100000;
-- hive一次性最大能够创建多少个文件: 默认为10w
set hive.exec.max.created.files=150000;
-- hive压缩
-- 开启中间结果压缩
set hive.exec.compress.intermediate=true;
-- 开启最终结果压缩
set hive.exec.compress.output=true;
-- 写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









