







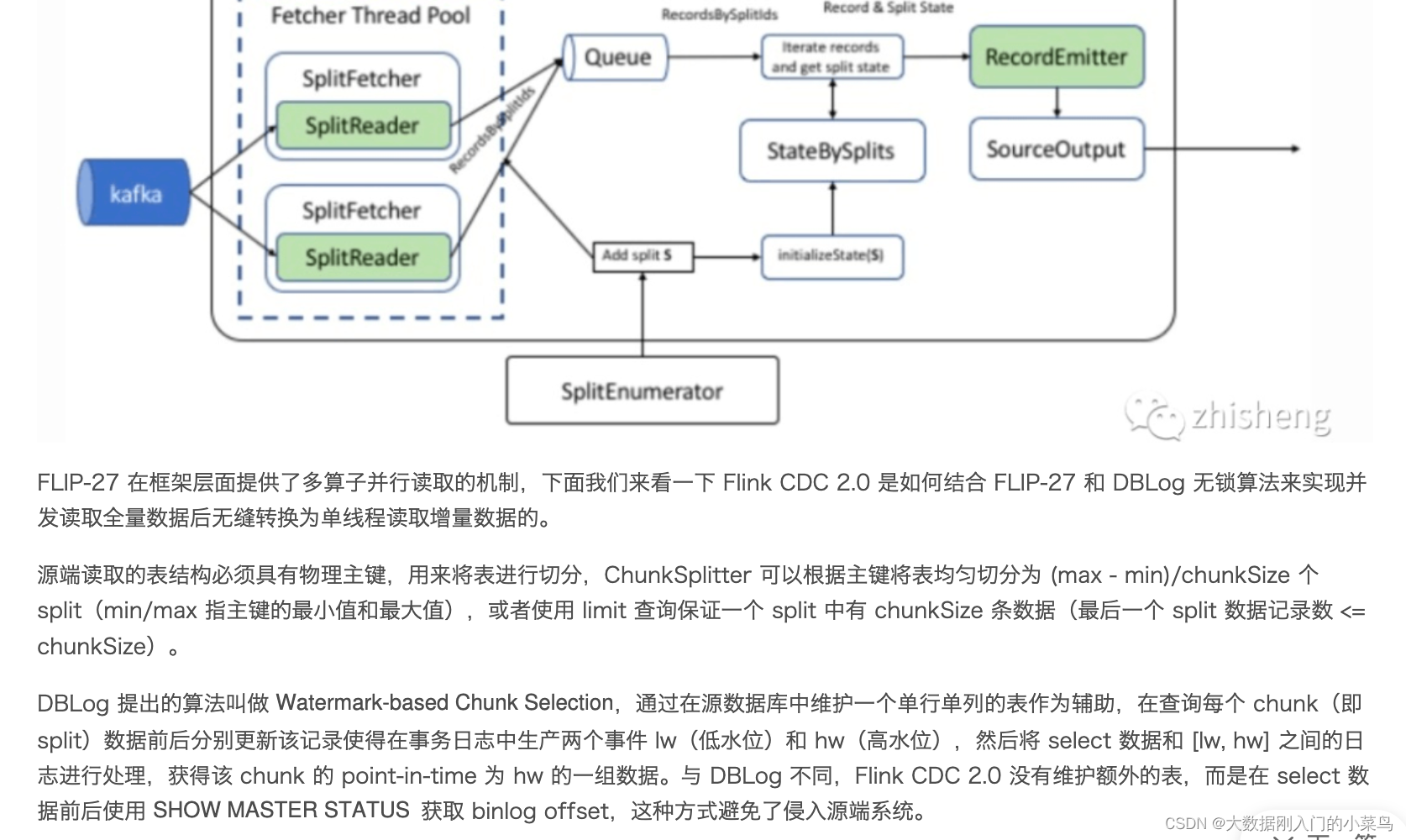
在对于有主键的表做初始化模式,整体的流程主要分为5个阶段:
1.Chunk切分;

2.Chunk分配;(实现并⾏读取数据&CheckPoint)
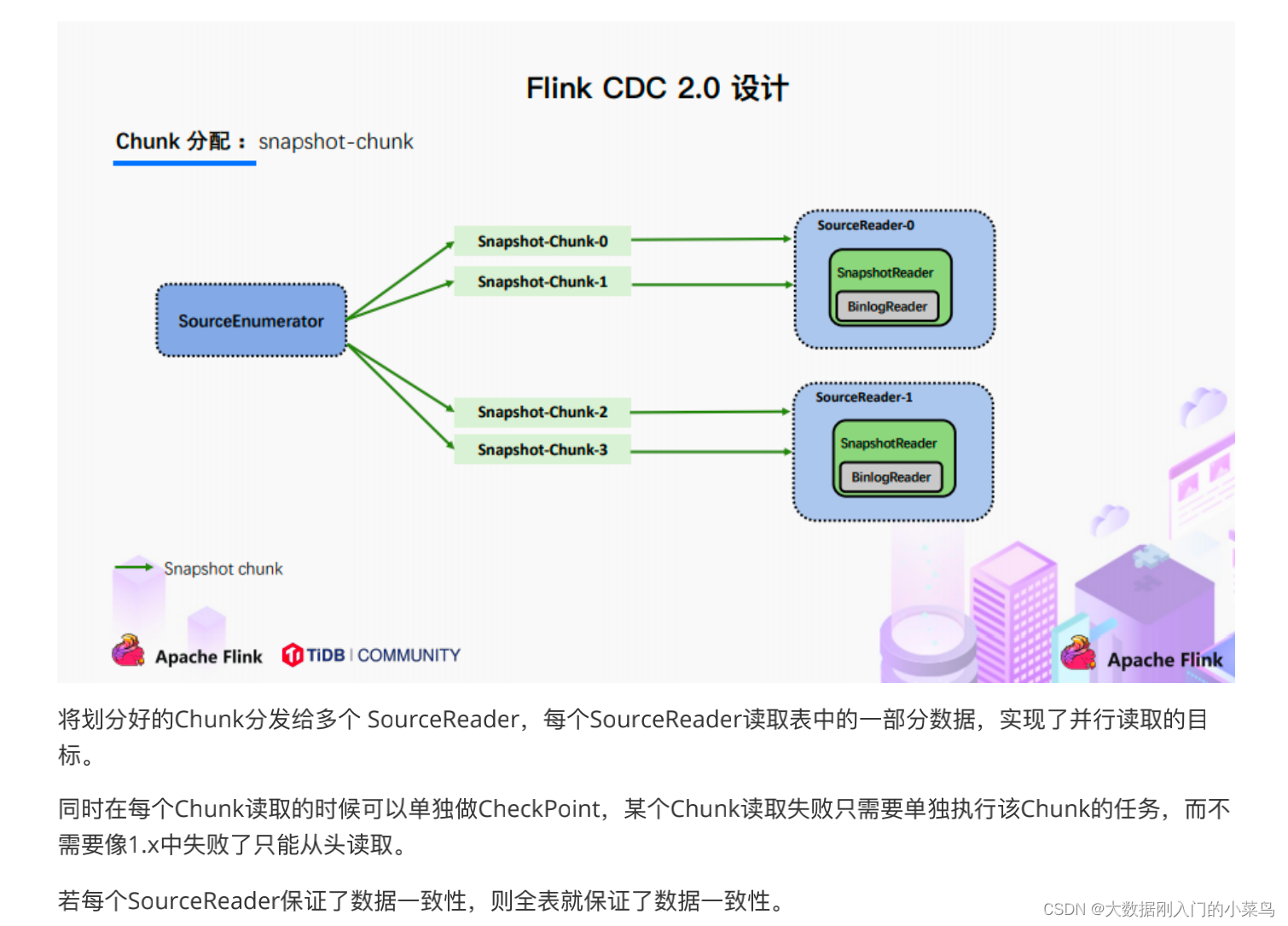
3.Chunk读取;(实现⽆锁读取)
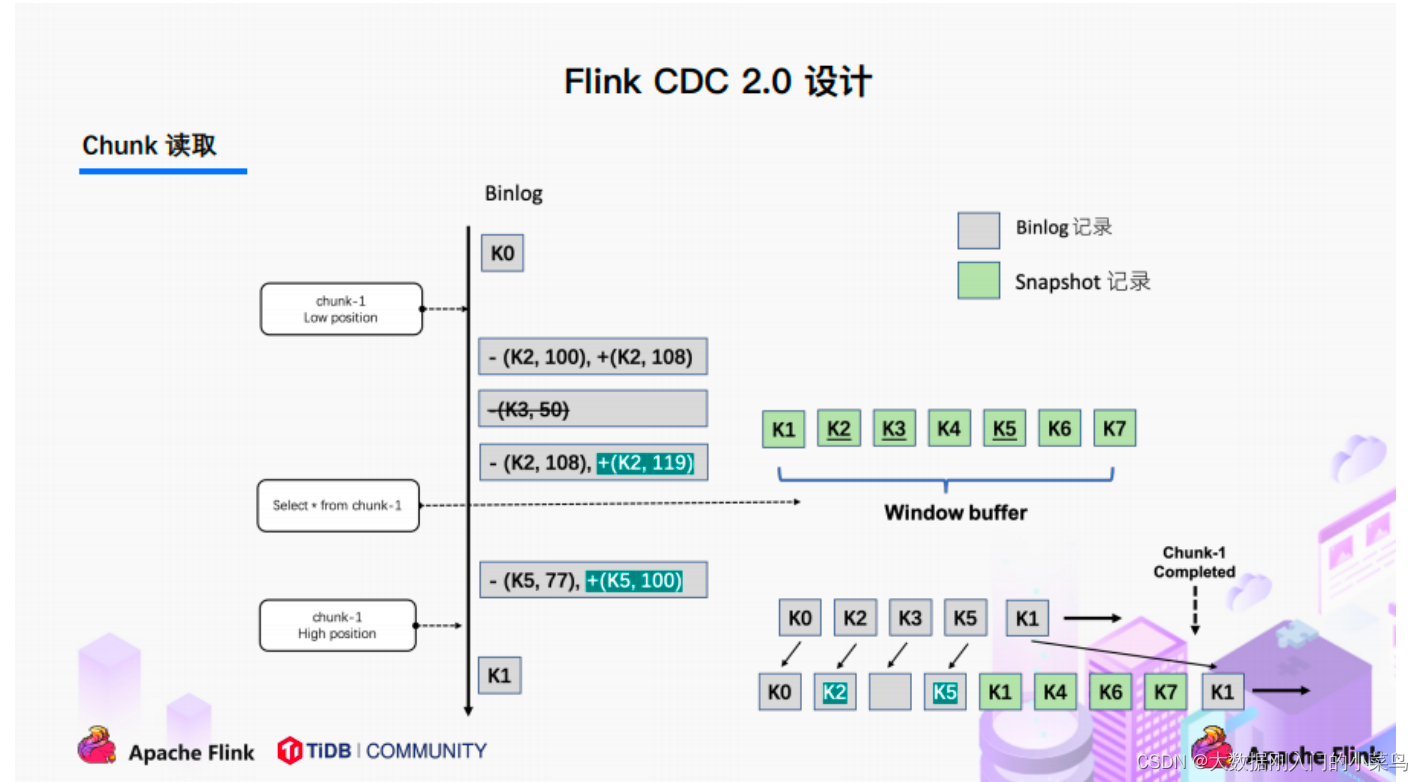
读取可以分为5个阶段
1)SourceReader读取表数据之前先记录当前的Binlog位置信息记为低位点;
2)SourceReader将⾃身区间内的数据查询出来并放置在buffer中;
3)查询完成之后记录当前的Binlog位置信息记为⾼位点;
4)在增量部分消费从低位点到⾼位点的Binlog(注意:在binlog读取阶段做);
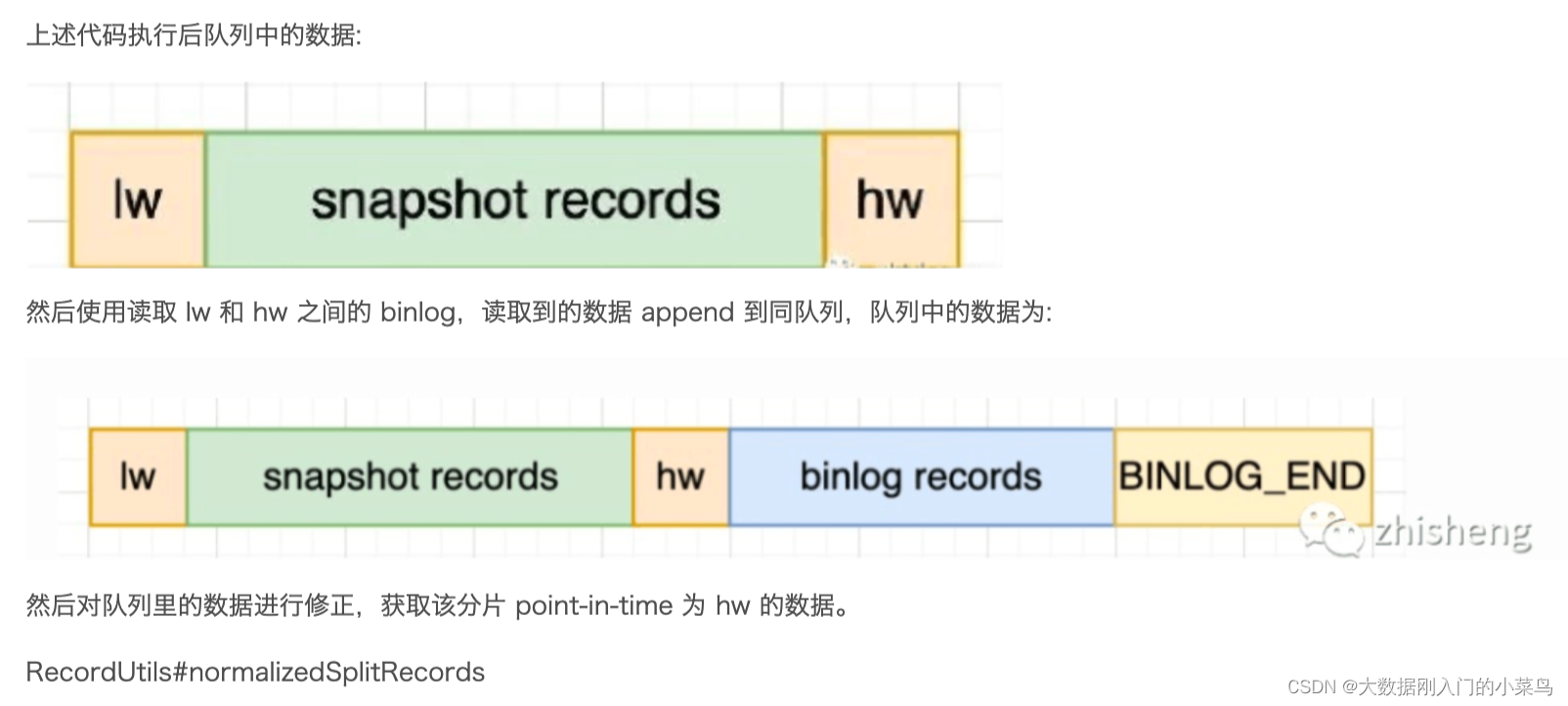
5)根据主键,对buffer中的数据进⾏修正并输出(注意:在binlog读取阶段做)。
通过以上5个阶段可以保证每个Chunk最终的输出就是在⾼位点时该Chunk中最新的数据,但是⽬前只是做到了保
证单个Chunk中的数据⼀致性。
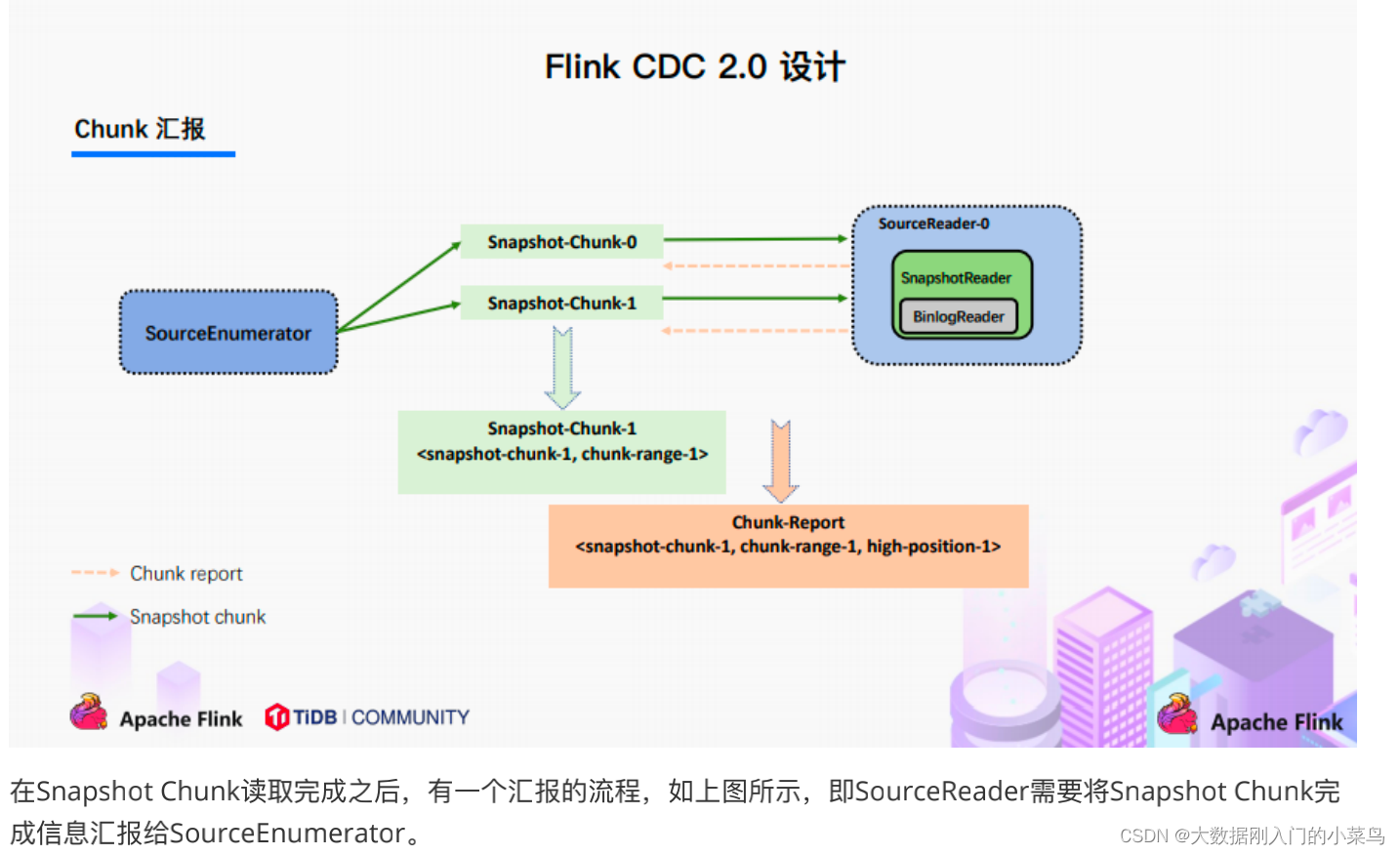
4.Chunk汇报;
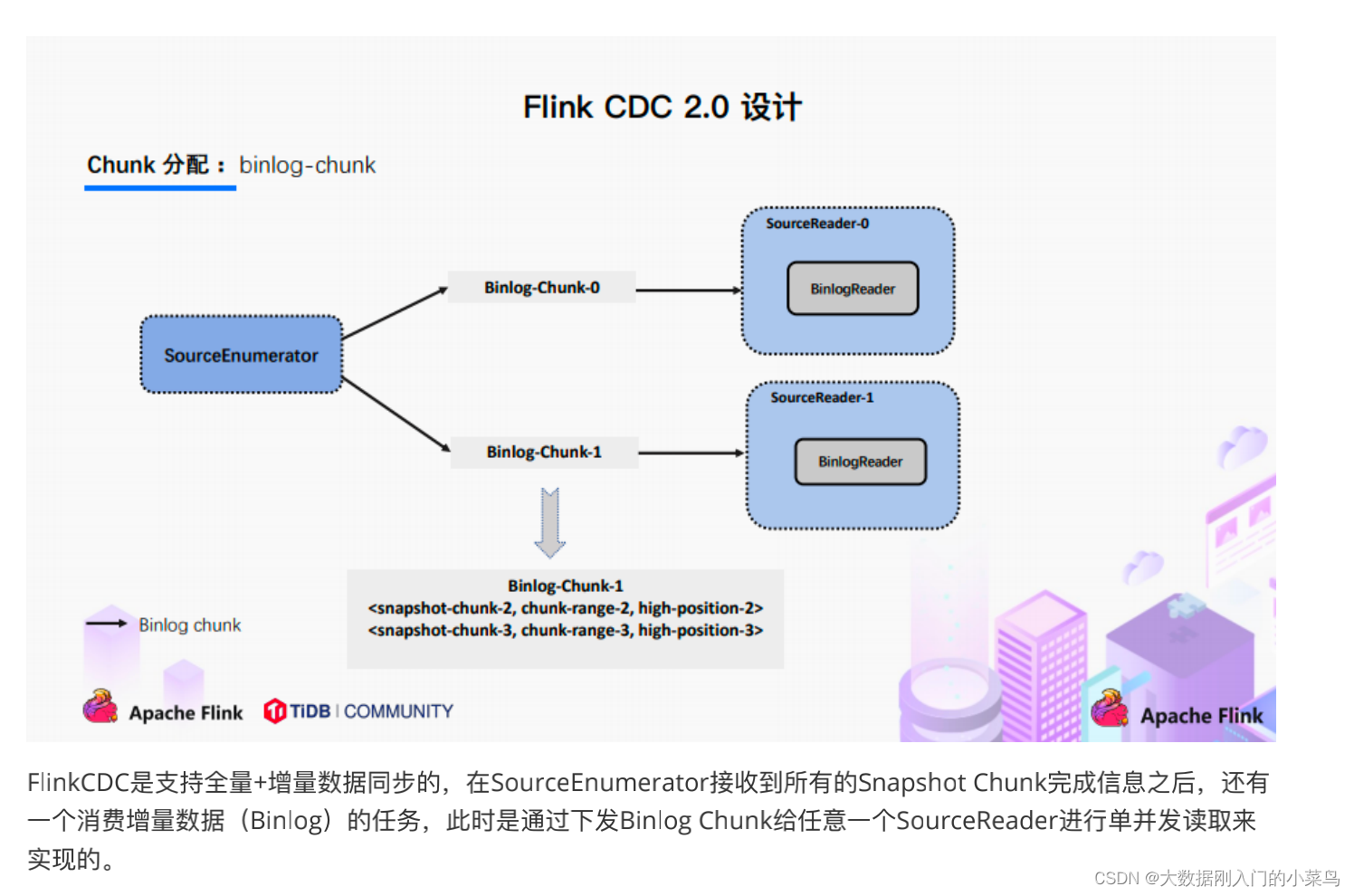
5.Chunk分配;







/**
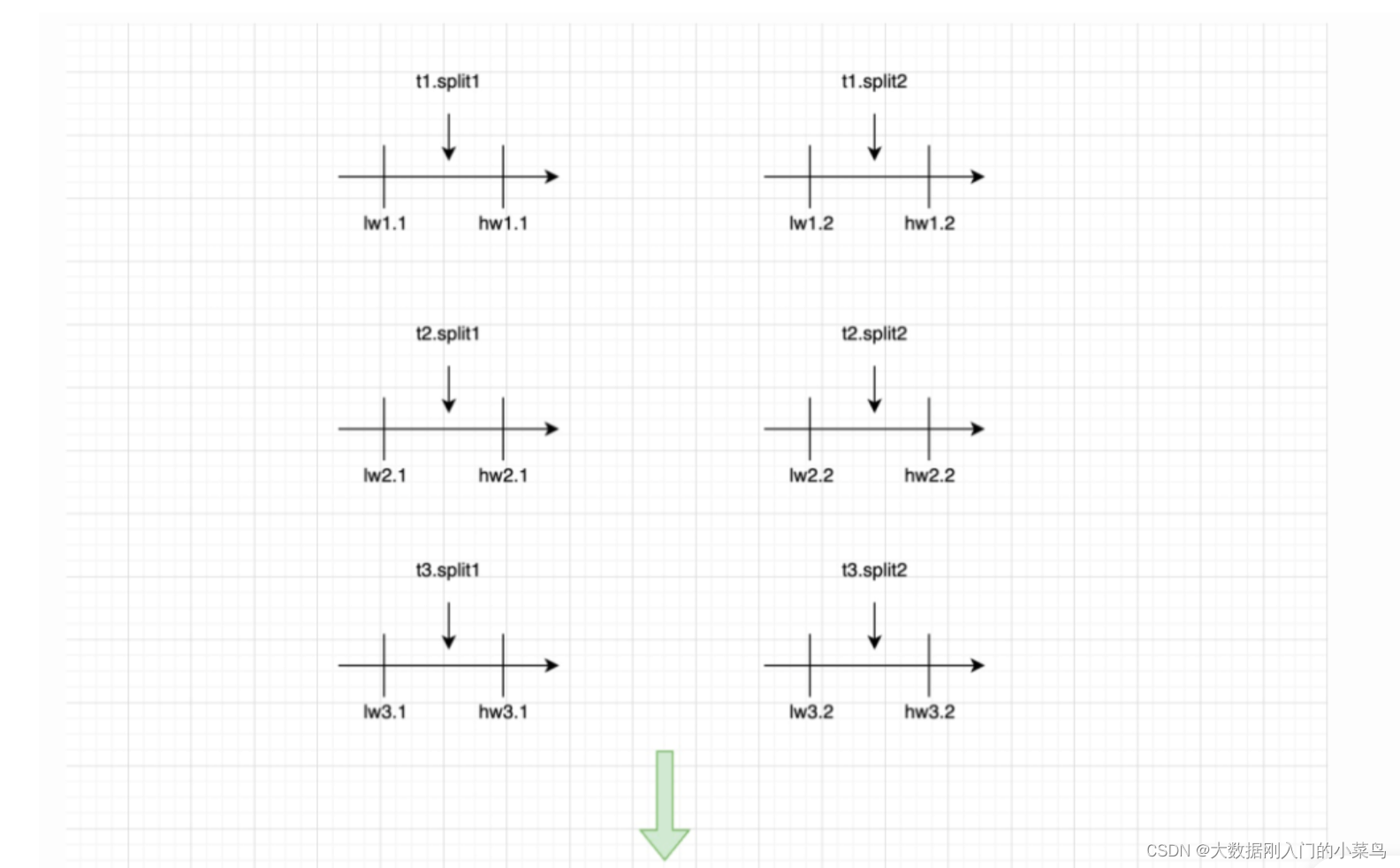
* 此过程 SourceRecord 上兵法执行,互不影响,假设一个任务同步三张表t1 /t2 / t3 被切分为 6 个切片,由于并发执行,其高低水位在binlog 上的位置的一种可能是
* @param lowWatermarkEvent
* @param highWatermarkEvent
* @param snapshotRecords
* @param binlogRecords
* @return
*/
private static List<SourceRecord> upsertBinlog(
SourceRecord lowWatermarkEvent,
SourceRecord highWatermarkEvent,
Map<Struct, SourceRecord> snapshotRecords,
List<SourceRecord> binlogRecords) {
// upsert binlog events to snapshot events of split
if (!binlogRecords.isEmpty()) {
for (SourceRecord binlog : binlogRecords) {
Struct key = (Struct) binlog.key();
Struct value = (Struct) binlog.value();
if (value != null) {
Envelope.Operation operation =
Envelope.Operation.forCode(
value.getString(Envelope.FieldName.OPERATION));
switch (operation) {
case CREATE:
case UPDATE:
Envelope envelope = Envelope.fromSchema(binlog.valueSchema());
Struct source = value.getStruct(Envelope.FieldName.SOURCE);
Struct after = value.getStruct(Envelope.FieldName.AFTER);
Instant fetchTs =
Instant.ofEpochMilli(
(Long) source.get(Envelope.FieldName.TIMESTAMP));
SourceRecord record =
new SourceRecord(
binlog.sourcePartition(),
binlog.sourceOffset(),
binlog.topic(),
binlog.kafkaPartition(),
binlog.keySchema(),
binlog.key(),
binlog.valueSchema(),
envelope.read(after, source, fetchTs));
snapshotRecords.put(key, record);
break;
case DELETE:
snapshotRecords.remove(key);
break;
case READ:
throw new IllegalStateException(
String.format(
"Binlog record shouldn't use READ operation, the record is %s.",
binlog));
}
}
}
}
final List<SourceRecord> normalizedRecords = new ArrayList<>();
normalizedRecords.add(lowWatermarkEvent);
normalizedRecords.addAll(formatMessageTimestamp(snapshotRecords.values()));
normalizedRecords.add(highWatermarkEvent);
return normalizedRecords;
}



private MySqlBinlogSplit createBinlogSplit() {
final List<MySqlSchemaLessSnapshotSplit> assignedSnapshotSplit =
snapshotSplitAssigner.getAssignedSplits().values().stream()
.sorted(Comparator.comparing(MySqlSplit::splitId))
.collect(Collectors.toList());
Map<String, BinlogOffset> splitFinishedOffsets =
snapshotSplitAssigner.getSplitFinishedOffsets();
final List<FinishedSnapshotSplitInfo> finishedSnapshotSplitInfos = new ArrayList<>();
BinlogOffset minBinlogOffset = null;
for (MySqlSchemaLessSnapshotSplit split : assignedSnapshotSplit) {
// find the min binlog offset
BinlogOffset binlogOffset = splitFinishedOffsets.get(split.splitId());
if (minBinlogOffset == null || binlogOffset.isBefore(minBinlogOffset)) {
minBinlogOffset = binlogOffset;
}
finishedSnapshotSplitInfos.add(
new FinishedSnapshotSplitInfo(
split.getTableId(),
split.splitId(),
split.getSplitStart(),
split.getSplitEnd(),
binlogOffset));
}
// the finishedSnapshotSplitInfos is too large for transmission, divide it to groups and
// then transfer them
boolean divideMetaToGroups = finishedSnapshotSplitInfos.size() > splitMetaGroupSize;
return new MySqlBinlogSplit(
BINLOG_SPLIT_ID,
minBinlogOffset == null ? BinlogOffset.INITIAL_OFFSET : minBinlogOffset,
BinlogOffset.NO_STOPPING_OFFSET,
divideMetaToGroups ? new ArrayList<>() : finishedSnapshotSplitInfos,
new HashMap<>(),
finishedSnapshotSplitInfos.size());
}



















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









