









Deep Residual Learning for Image Recognition
文章地址:《Deep Residual Learning for Image Recognition》 arXiv.1512.03385
ResNet Github参考:https://github.com/tornadomeet/ResNet

微软亚洲研究院ResNet深度残差网络。
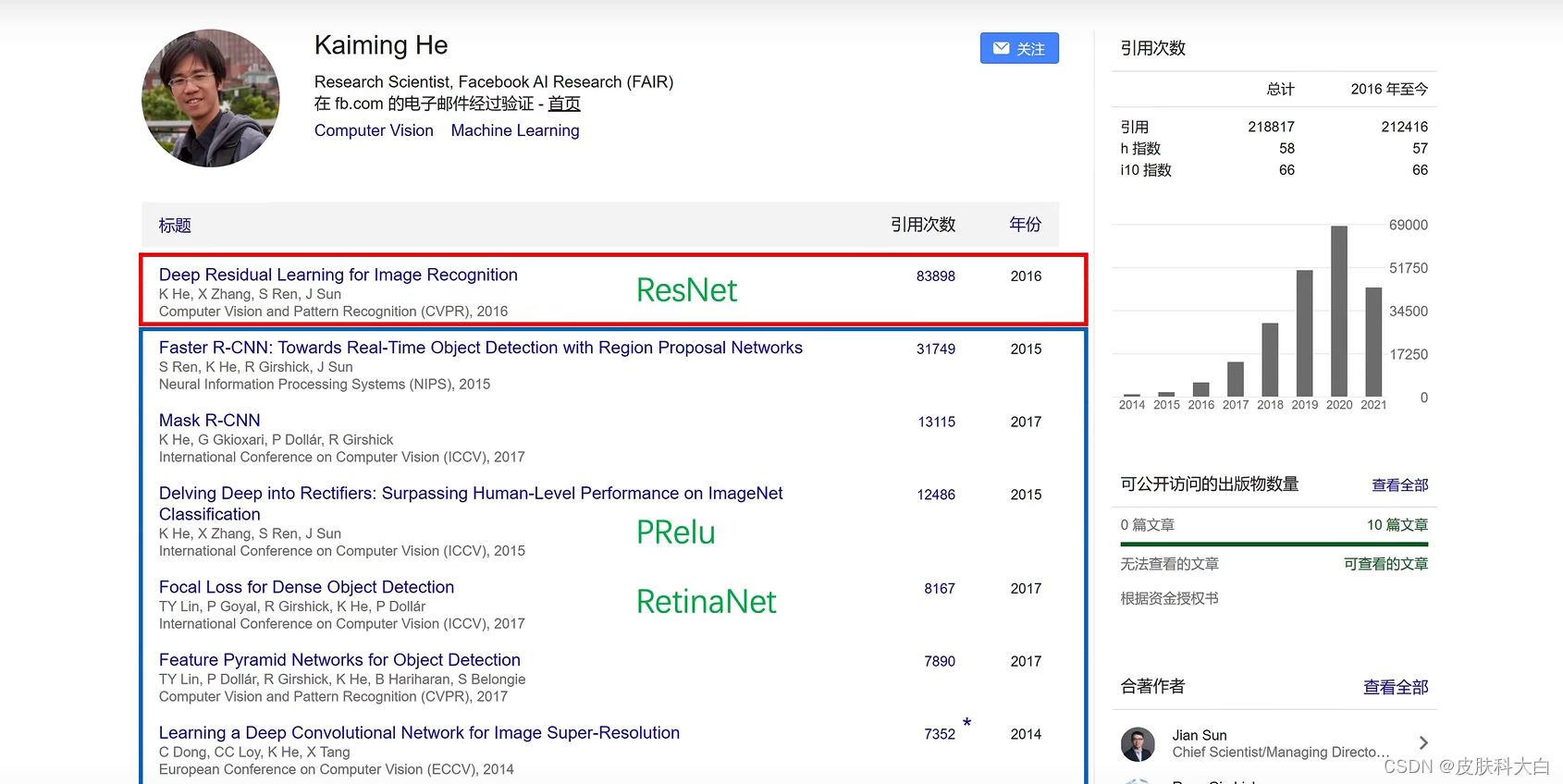
2016年CVPR最佳论文:Deep Residual Learning for Image Recognition。作者:何恺明、张祥雨、任少卿、孙剑。
通过残差模块解决深层网络的退化问题,大大提升神经网络深度,各类计算机视觉任务均从深度模型提取出的特征中获益。
ResNet获得2015年ImageNet图像分类、定位、目标检测竞赛冠军,MS COCO目标检测、图像分割冠军。并在ImageNet图像分类性能上超过人类水平。
这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新的网络结构来解决当网络层数过高之后更深层的网络的效果没有稍浅层网络好的问题,并且做出了适当解释,用ResNet很好的解决了这个问题。
在这里插入图片描述
大佬展示
大会汇报

深度网络本质上以端到端的多层方式集成了低/中/高级特征和分类器,并且可以通过堆叠更多的层数(增加深度)来丰富特征的“级别”。研究也表明,网络的深度对模型性能是至关重要的,这就导致出现的网络越来越深。
可是随着深度加深,网络在训练时会遇到著名的“梯度消失”和“梯度爆炸”问题,它们从训练一开始就阻止收敛。但是,这些问题已经通过归一初始化(normalized initialization)和中间归一化(intermediate normalization)在很大程度上解决了这一问题,它使得数十层的网络在反向传播的随机梯度下降(SGD)上能够收敛。
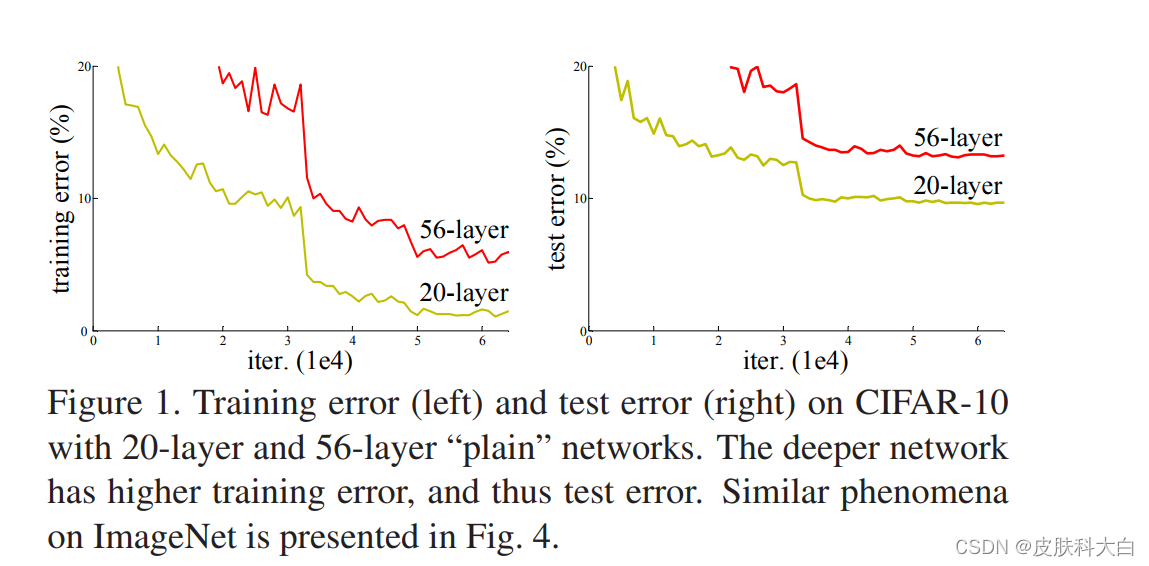
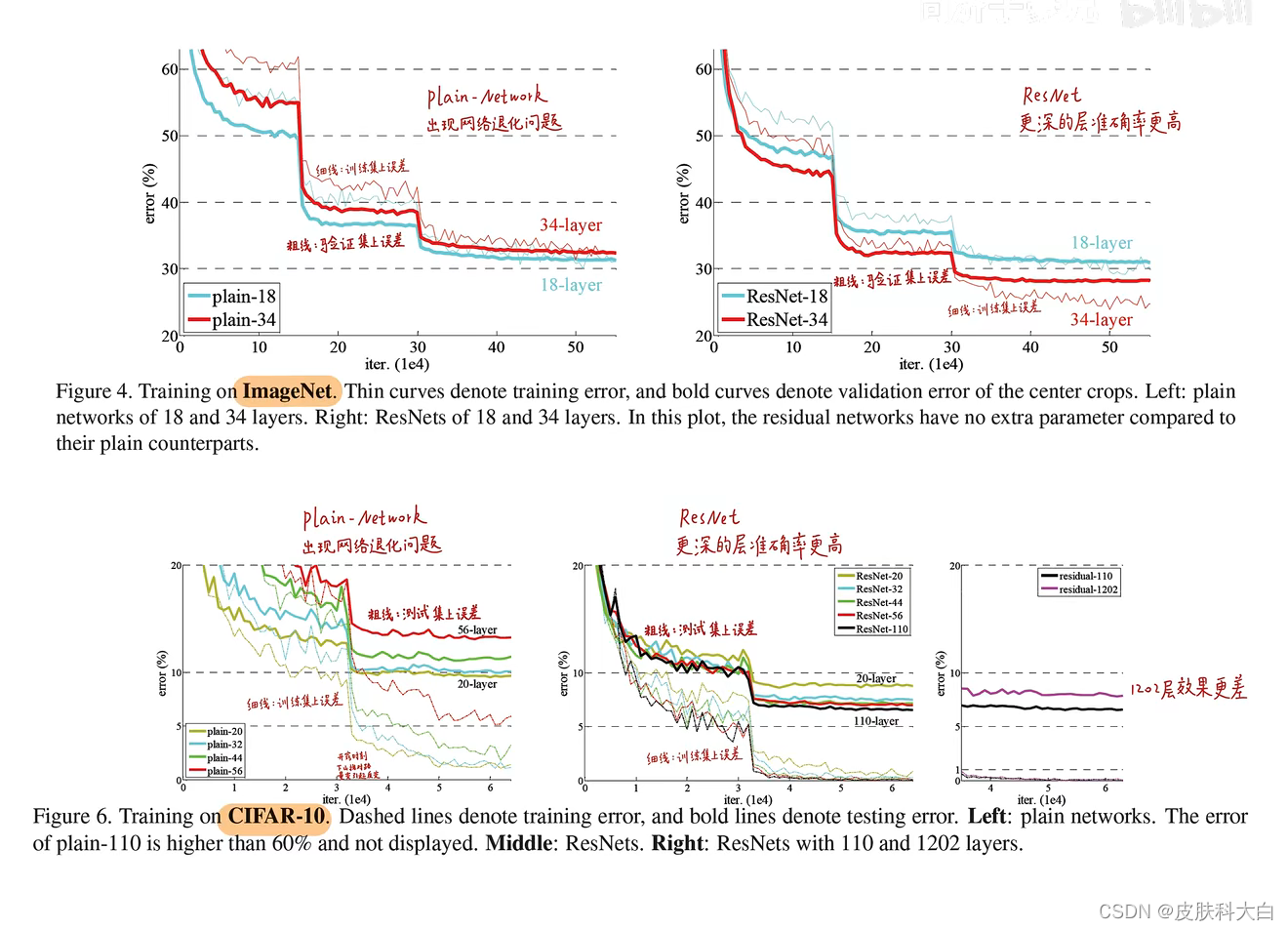
但是,随着网络层数的加深,暴露出一个对于训练精度来说,被称为“退化“的问题:随着网络深度增加,在训练集上的精度达到饱和,然后迅速下降。显然,这种现象不是过拟合造成的,因为过拟合会使得训练集上的精度极高。如果此时向一个深度适当的模型添加更多层的话会带来更高的训练误差,如下图所示:
然而当开始考虑更深层的网络的收敛问题时,退化问题就暴露了:随着神经网络深度的增加,精确度开始饱和(这是不足为奇的),然后会迅速的变差。出人意料的,这样一种退化,并不是过拟合导致的,并且增加更多的层匹配深度模型,会导致更多的训练误差,
背景知识:
残差
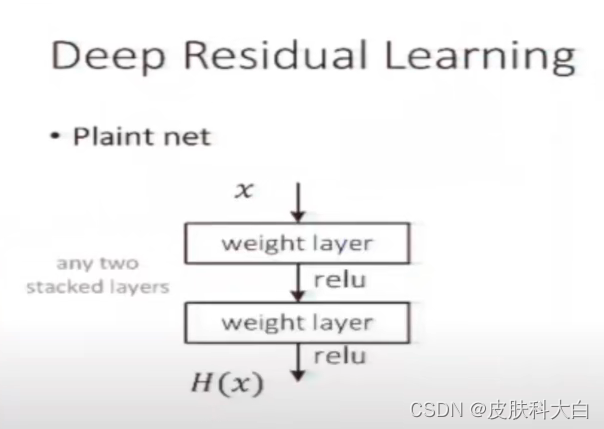
那么如果换一种思路来构建神经网络:假设浅层网络已经可以得到一个不错的结果了,接下来新增加的层啥也不干,只是拟合一个identity mapping(恒等映射),输出就拟合输入,这样构建的深层网络至少不应该比它对应的浅层training error要高,但是实验无情地表明:这样不能得到(与浅层网络)一样好的结果,甚至还会比它差。
一个更深的模型不应当产生比它的浅层版本更高的训练错误率
为了解决退化问题,作者在该论文中提出了一种叫做“深度残差学习框架”(Deep residual learning framework)的网络。在该结构中,每个堆叠层(Stacked layer)拟合残差映射(Residual mapping),而不是直接拟合整个building block期望的基础映射(Underlying mapping)(将当前栈的输入与后面栈的输入之间的映射称为 underlying mapping)。形式上,
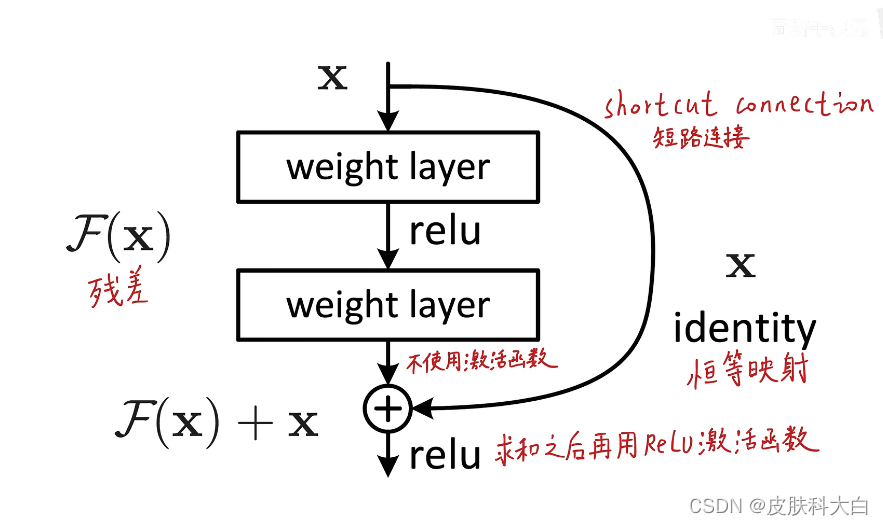
如果用H(x)来表示整个building block的映射(底层映射为 H(x)),那么building block中堆叠的非线性层(即building block中由若干卷积层组成的支路Stacked layer。另一条支路是线性层,表示成恒等映射或投影)拟合的就是另一个映射:F(x)=H(x)-x(我们让堆叠的非线性层来拟合另一个映射: F(x):=H(x)−x),所以原映射就变成F(x)+x(整个building block表示的映射依然是H(x),但是拟合的是非线性堆叠层表示的残差映射F (x),没有像以前那样直接对H (x)进行拟合)。
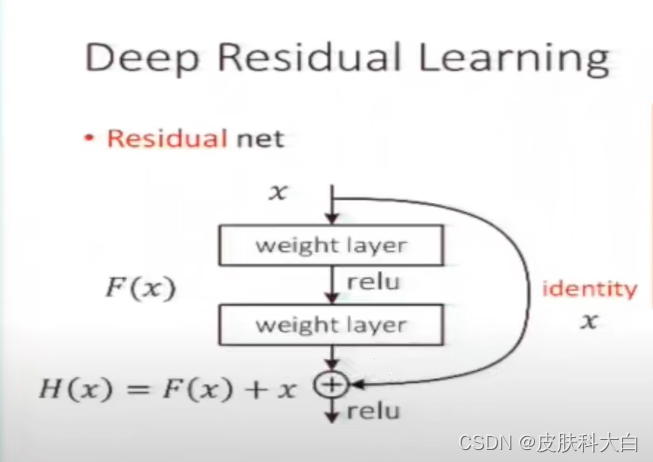
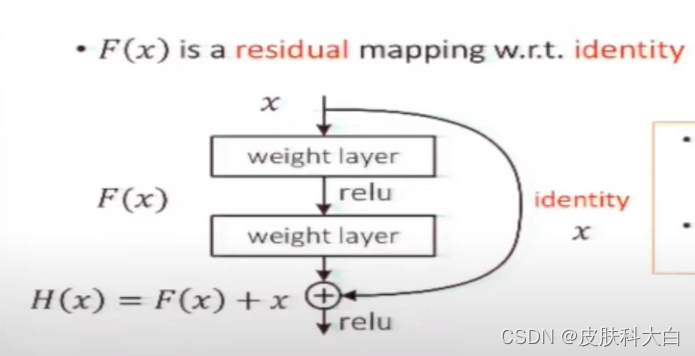
事实证明,优化残差映射比优化原来的原始未参考的映射(unreferenced mapping)容易很多。
F(x)+x 可以上图所示的附带“shortcut connections”的前馈神经网络实现。“shortcut connections”就是图中跨一层或更多层的连线,用来执行恒等映射(Identity mapping)。可见,identity shortcut connections不给模型额外添加参数和计算量。此外,整个网络依然能够端到端地使用反向传播算法训练,也可以很容易地使用公共库(如Caffe)实现,且无需修改求解器(solvers,应该是说SGD、RMSProp等训练方法)。
2.Methods
Residual Learning
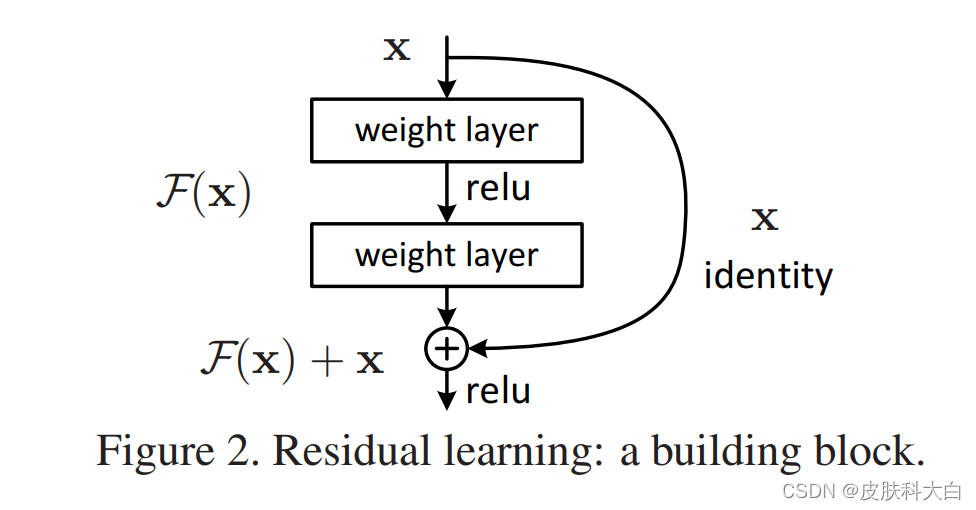
让我们思考一下H(X) 作为由几个堆叠层来拟合的基础映射(underlying mapping),其中x代表输入至这几层的第一层的参数,假如多个线性层可以逐渐逼近复杂的函数,那么它也可以逐渐逼近残差函数,例如H(X) - X(假设输入和输出是相同维度的)。所以,我们让这些层来拟合F(X) = H(X) - X而不是单独的H(X)。那么原始函数就变成了F(X) + X。即使两种函数都可以拟合,但是,学习的难易程度是不一样的。
关于退化问题的反直觉现象(图1,左)是上述表述的动机。正如在介绍中所讨论的,如果添加的层可以构建为恒等映射,那么更深层次的模型的训练错误应该不大于更浅层次的对应模型。退化问题表明,求解器可能在拟合多层非线性恒等映射的问题上有困难。利用残差学习重构,如果恒等映射是最优的,求解器可以简单地将多个非线性层的权值向零逼近以达到恒等映射。
但在现实中不可能得到理想的恒等映射(即多层非线性层的权重不是0),不过没关系,残差学习或许能帮我们解决这个问题(就是说,虽然得不到理想的恒等映射,但是接近恒等映射的映射也行啊,足以缓解退化问题)。Fig.7中的实验结果就证明了这一点:学习到的残差函数通常响应很小(权重很小),说明近似的“恒等映射”给模型提供了合理的预处理。

参考:http://www.jianshu.com/p/f71ba99157c7
https://www.bilibili.com/video/BV1vb4y1k7BV?spm_id_from=333.337.search-card.all.clic

接下来的大菜,子豪师兄


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











