








 本教程指导如何在PyCharm中新建一个Scrapy项目。首先,通过设置菜单添加Scrapy,等待下载完成后,运行`scrapystartproject`命令初始化项目。接着,配置items.py文件,并创建run.py来运行爬虫。该项目专注于Python的网络爬虫开发,涉及Web数据抓取和处理。
本教程指导如何在PyCharm中新建一个Scrapy项目。首先,通过设置菜单添加Scrapy,等待下载完成后,运行`scrapystartproject`命令初始化项目。接着,配置items.py文件,并创建run.py来运行爬虫。该项目专注于Python的网络爬虫开发,涉及Web数据抓取和处理。
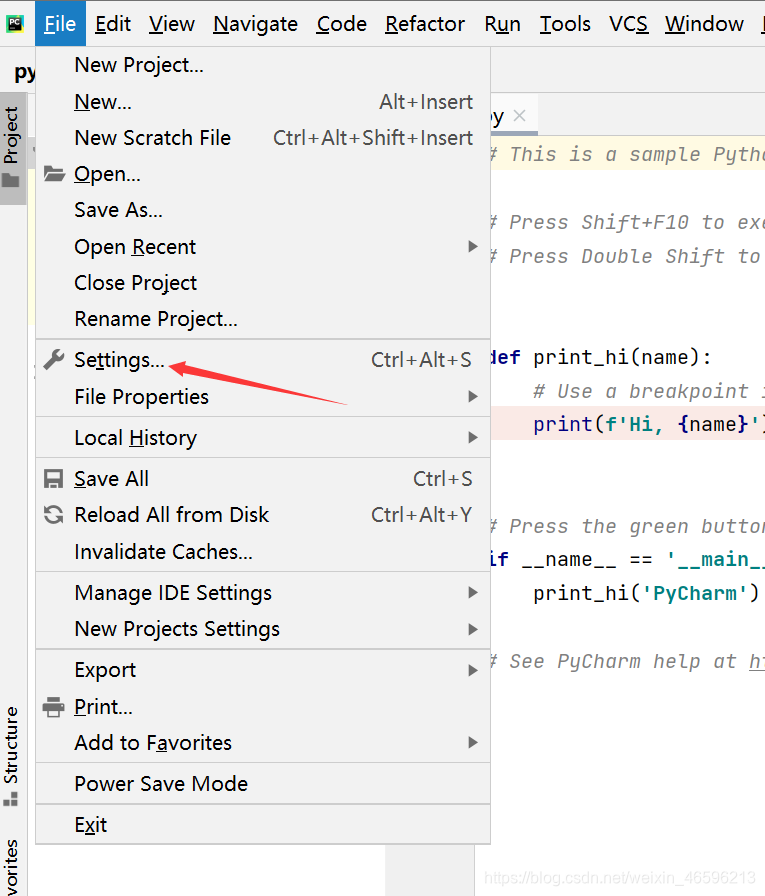
一、新建一个python项目,选择File=》Settings
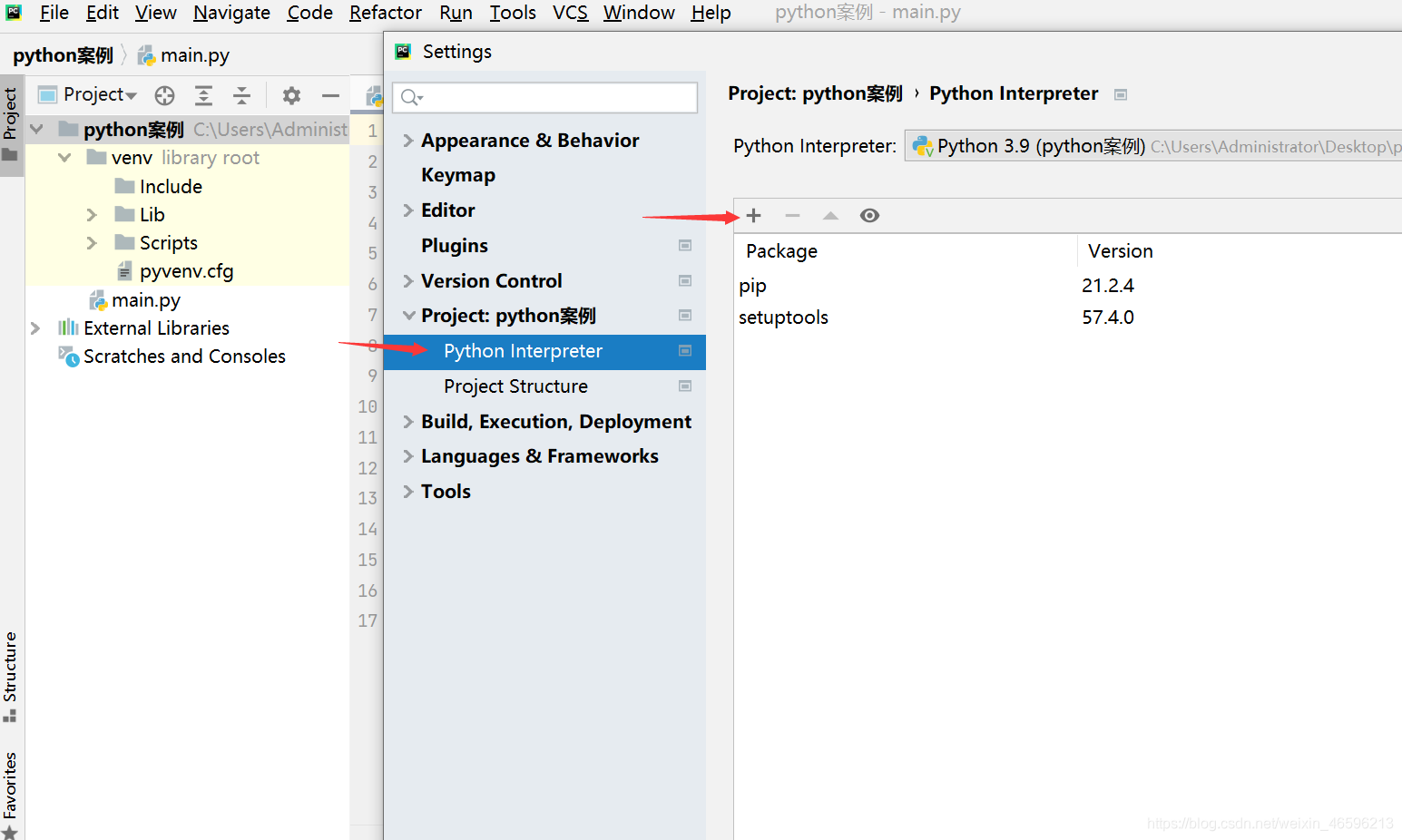
选择“+”号,输入Scrapy
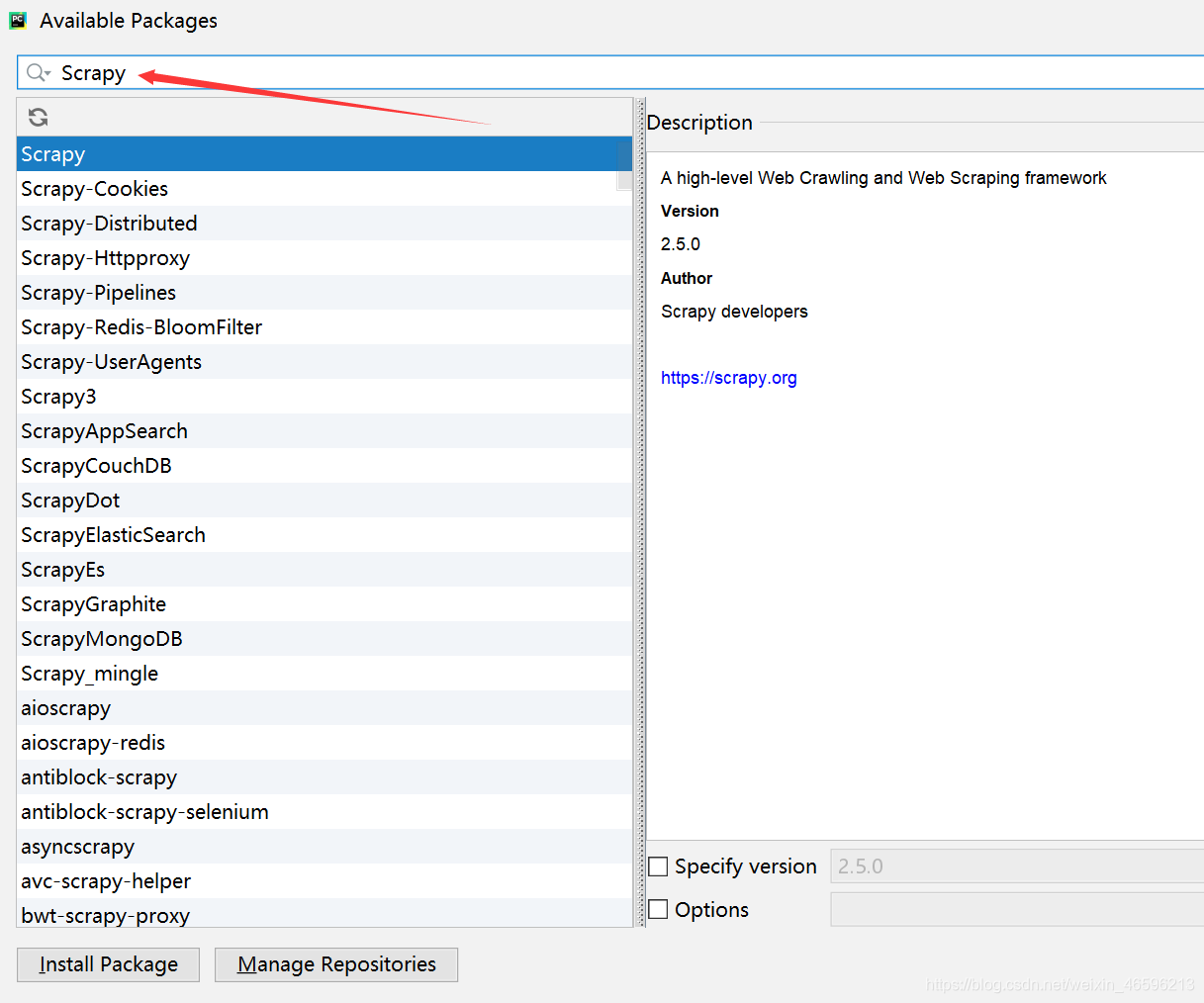 下载
下载
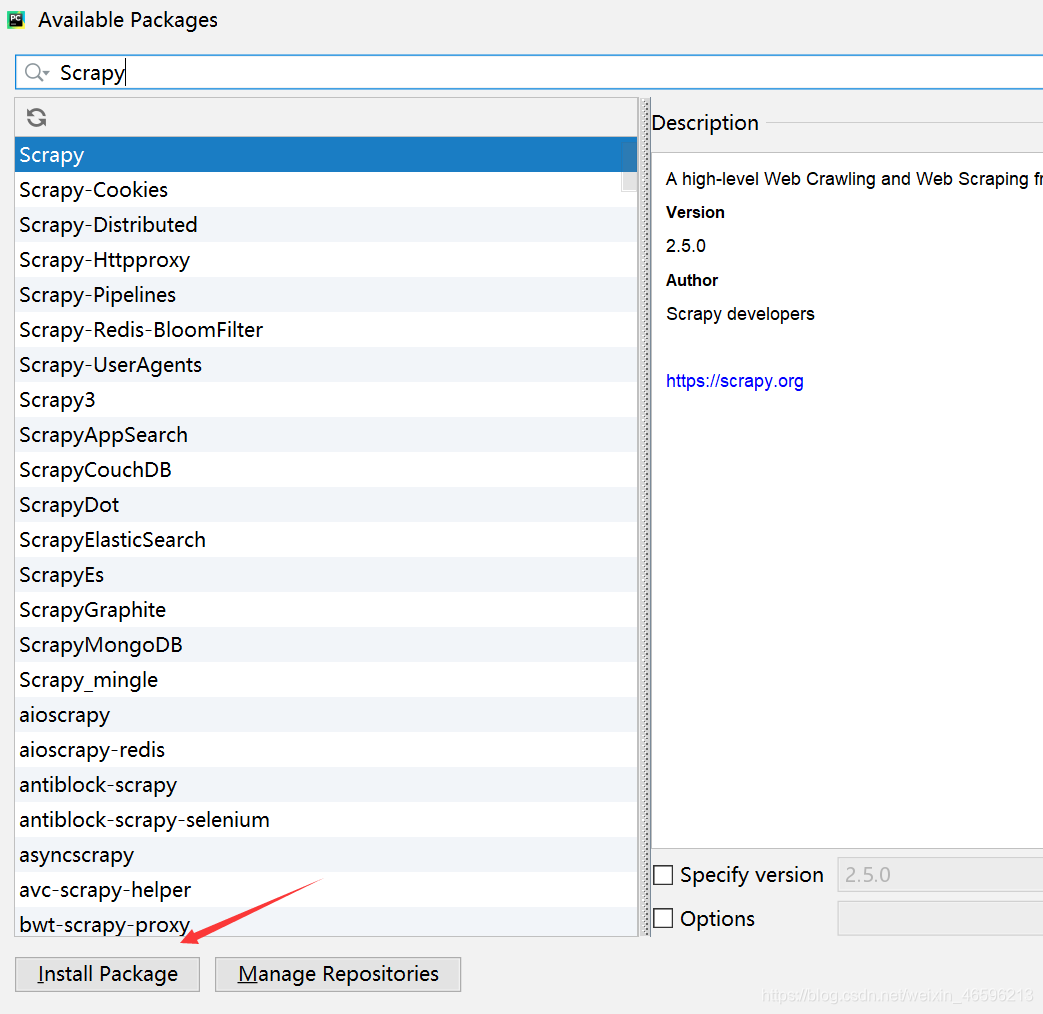
等待下载:
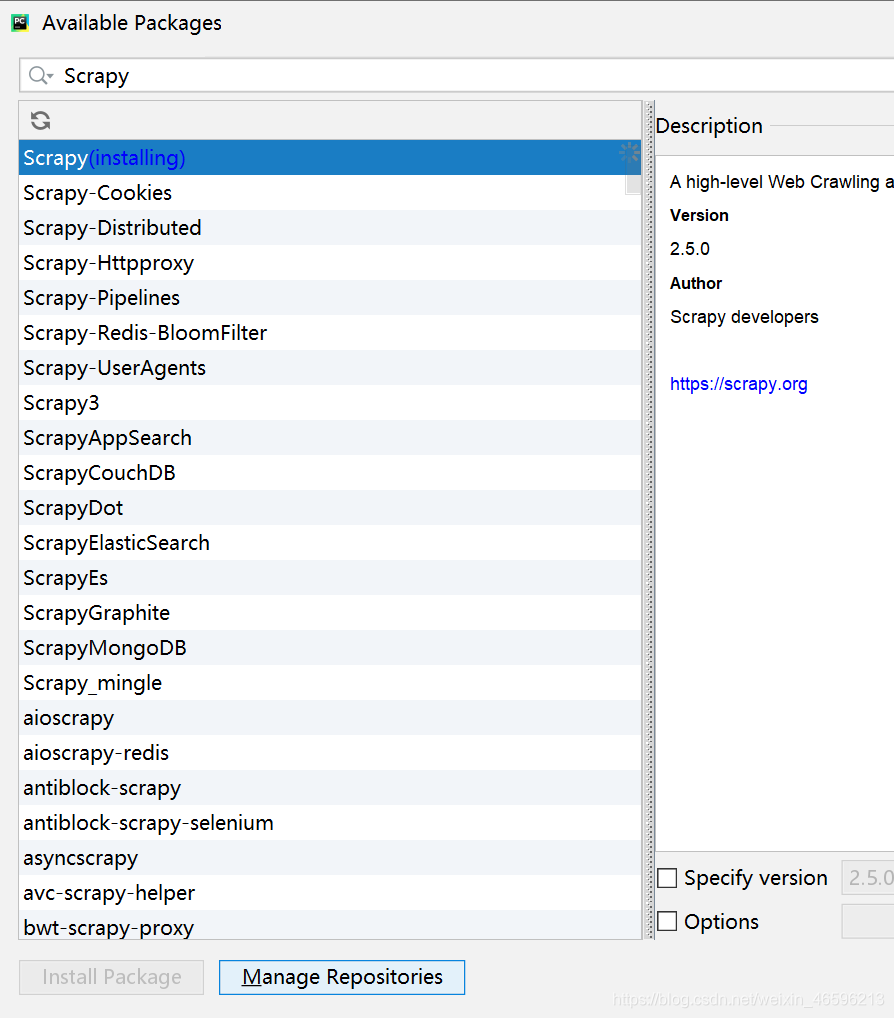
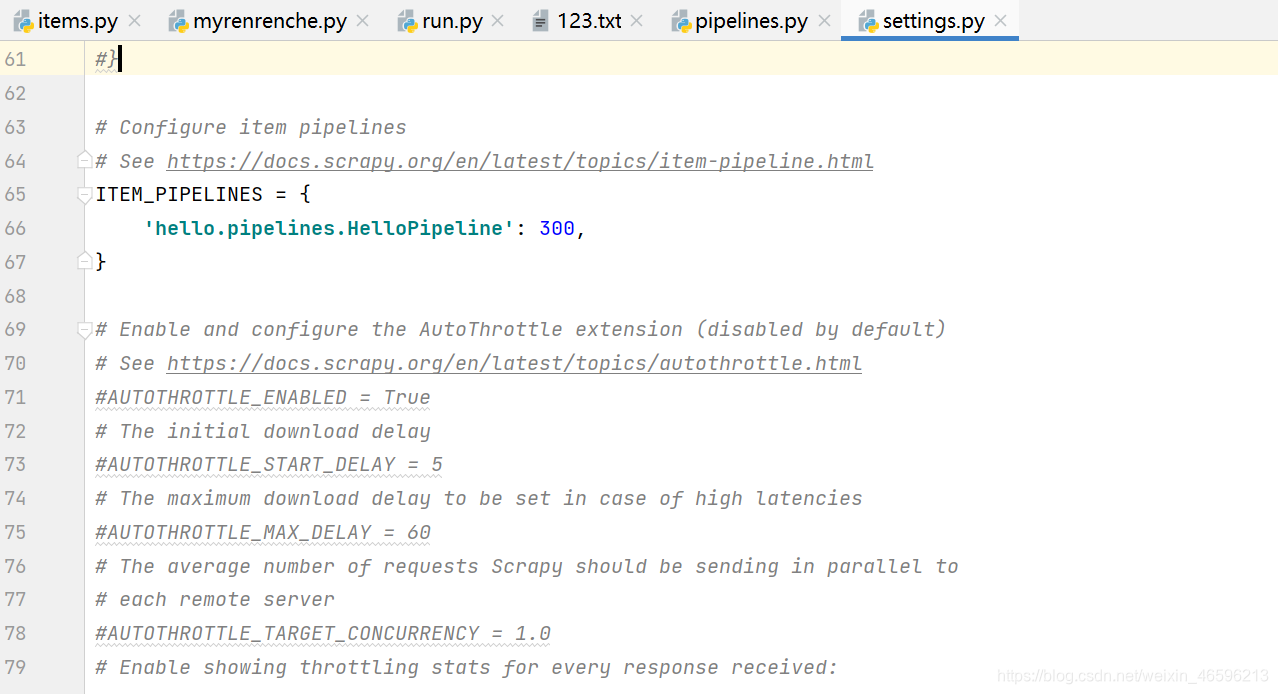
下载成功后,输入scrapy startproject 名字
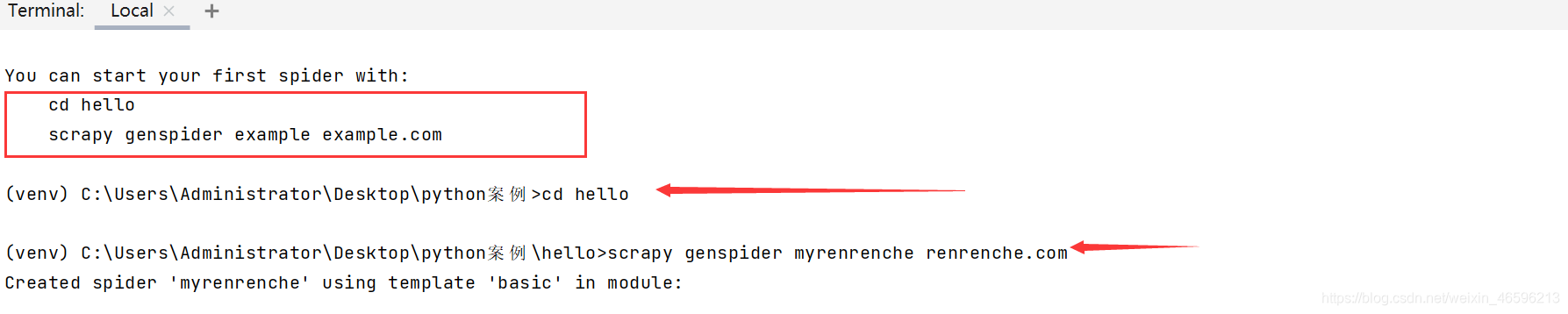
 接下来就按照它給的提示输入指令:
接下来就按照它給的提示输入指令:
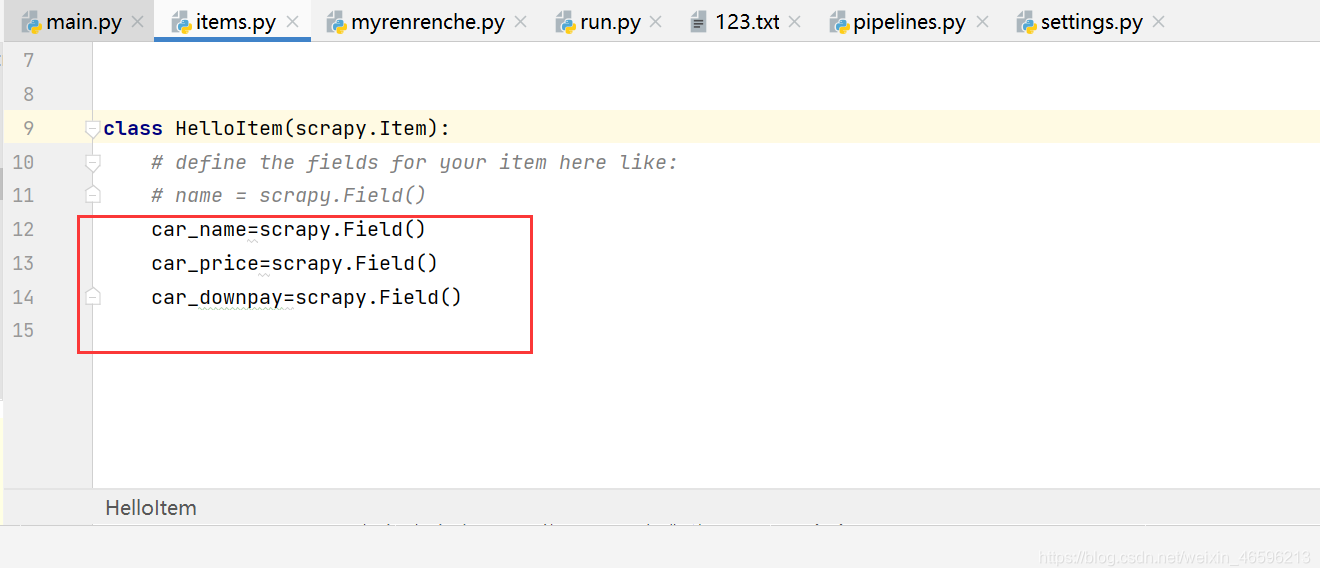
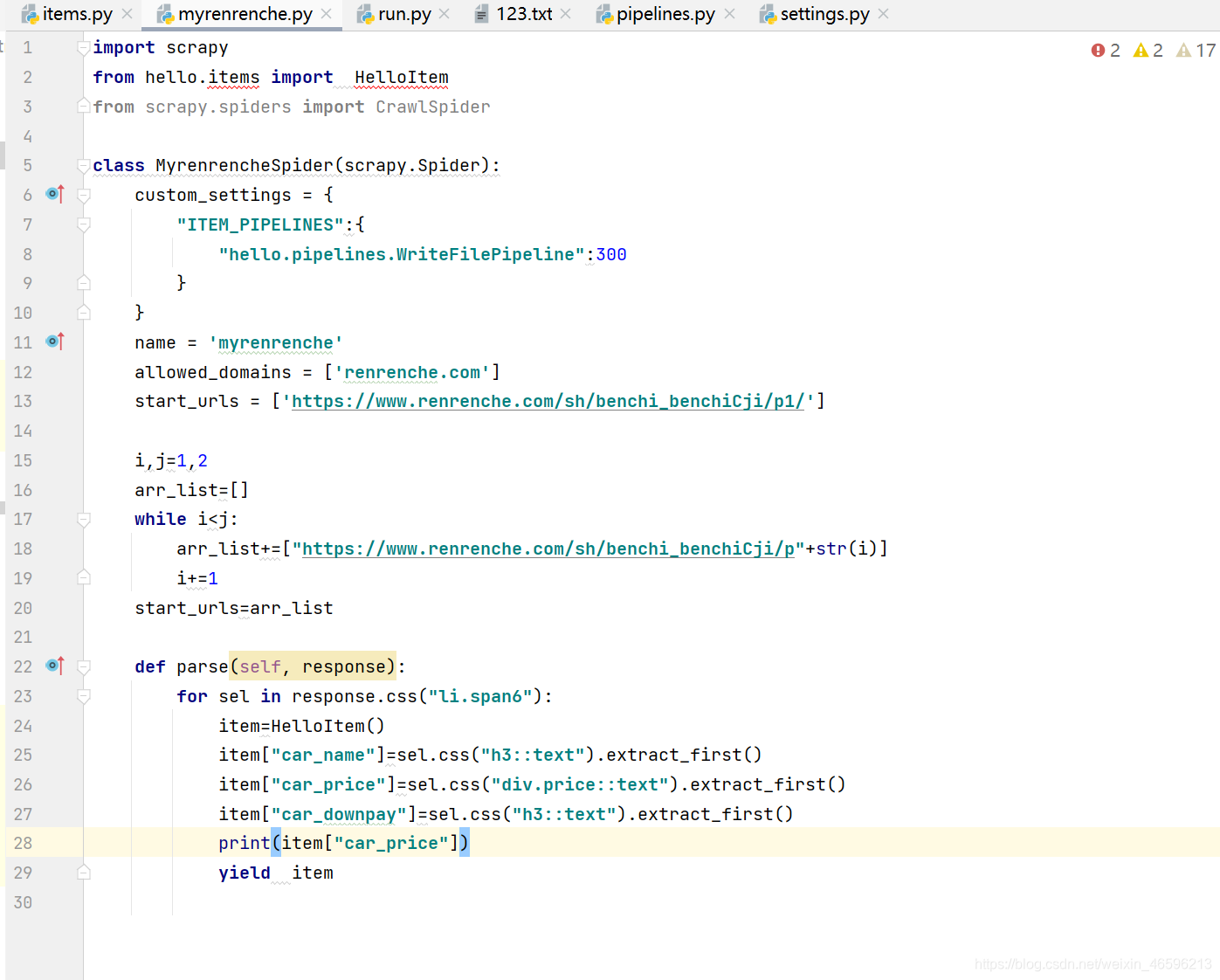
去到items.py文件中,
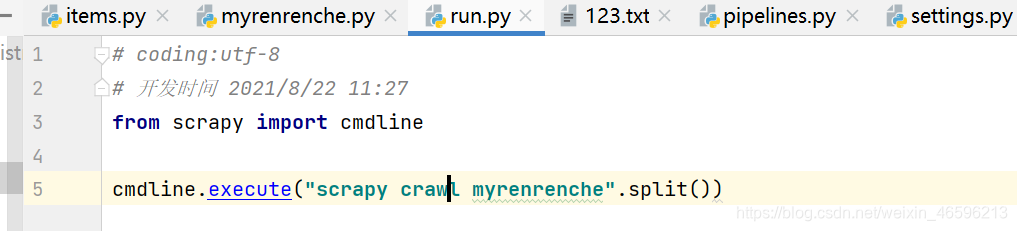
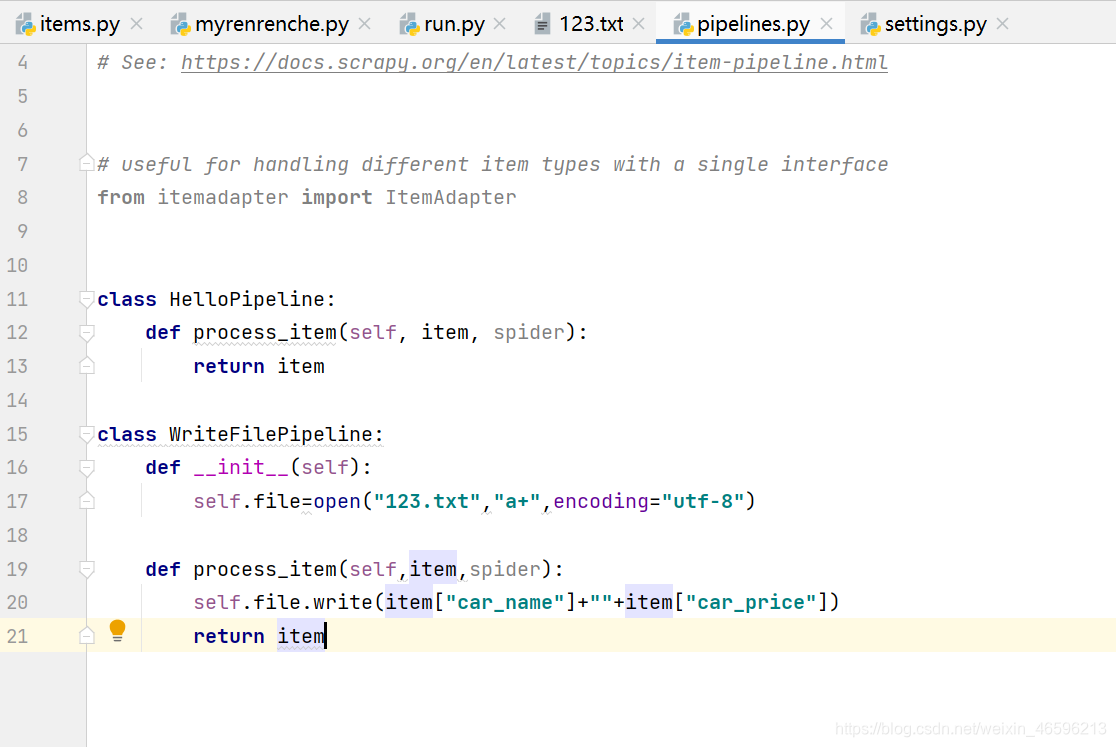
添加一个run.py文件:
一、新建一个python项目,选择File=》Settings
选择“+”号,输入Scrapy
下载
等待下载:
下载成功后,输入scrapy startproject 名字
接下来就按照它給的提示输入指令:
去到items.py文件中,
添加一个run.py文件:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 3962
3962





