







1、多表操作
现实生活中,(班级)实体与(学生)实体之间肯定是有关系的,那么我们在设计表的时候,就应该体现出(班级)表与(学生)表之间的这种关系!
简称:关系型数据库(Relation DBMS)
1.1 常见的表关系
一对一
公民和身份证号、公司和注册地、老公与老婆的关系(合法夫妻)一个公民只能有一个身份证号,一个身份证号对应一个公民
一对多(多对一)
班级和学生、部门和员工一个班级下面有多名同学,多名同学属于某一个班级
多对多
老师和学生、学生和课程一名老师可以教导多名学生,一名学生可以被多个老师教导
1.1.1 一对一
一对一关系在实际开发中用的并不多,因为可以把关联字段设计在同一张表...

1.1.2 一对多(多对一)

1.1.3 多对多

2、多表查询|连接查询
2.1 连接查询的分类
根据表的连接方式来划分,包括:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接(左连接)
右外连接(右连接)
全连接(在MySQL中失效,使用full join关键字)
2.2 笛卡尔积现象
在表的连接查询方面有一种现象被称为:笛卡尔积现象。(笛卡尔乘积现象)
案例:找出每一个员工的部门名称,要求显示员工名和部门名。
select ename,dname from emp,dept;笛卡尔积现象:当两张表进行连接查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积。
怎么避免笛卡尔积现象?当然是加条件进行过滤。
思考:避免了笛卡尔积现象,会减少记录的匹配次数吗?
不会,次数还是56次。只不过显示的是有效记录。
2.3 内连接
必须表与表之间的关系一一对应
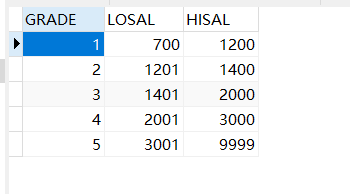
2.3.0 数据准备
emp表:员工表

dept表:部门表

salgrade表:工资登记表
2.3.1 内连接之等值连接
最大特点是:条件是等量关系。
案例:查询每个员工的部门名称,要求显示员工名和部门名。
select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno;// inner可以省略的,带着inner目的是可读性好一些。
select
e.ename,d.dname
from
emp e
inner join
dept d
on
e.deptno = d.deptno;2.3.2 内连接之非等值连接
最大的特点是:连接条件中的关系是非等量关系。
案例:找出每个员工的工资等级,要求显示员工名、工资、工资等级。
select
e.ename,e.sal,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal;
// inner可以省略
select
e.ename,e.sal,s.grade
from
emp e
inner join
salgrade s
on
e.sal between s.losal and s.hisal;2.3.3 自连接
最大的特点是:一张表看做两张表。自己连接自己。
案例:找出每个员工的上级领导,要求显示员工名和对应的领导名。
select
a.ename as '员工名',b.ename as '领导名'
from
emp a
inner join
emp b
on
a.mgr = b.empno;2.4 外连接
什么是外连接,和内连接有什么区别?
内连接:
假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接。AB两张表没有主副之分,两张表是平等的。
外连接:
假设A和B表进行连接,使用外连接的话,AB两张表中有一张表是主表,一张表是副表,主要查询主表中的数据,捎带着查询副表,当副表中的数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。
左连接有右连接的写法,右连接也会有对应的左连接的写法。
案例:找出每个员工的上级领导?(所有员工必须全部查询出来。)
内连接:
select
a.ename '员工', b.ename '领导'
from
emp a
join
emp b
on
a.mgr = b.empno;外连接:(左外连接/左连接)
select
a.ename '员工', b.ename '领导'
from
emp a
left join
emp b
on
a.mgr = b.empno;
// outer是可以省略的。
select
a.ename '员工', b.ename '领导'
from
emp a
left outer join
emp b
on
a.mgr = b.empno;外连接:(右外连接/右连接)
select
a.ename '员工', b.ename '领导'
from
emp b
right join
emp a
on
a.mgr = b.empno;
// outer可以省略。
select
a.ename '员工', b.ename '领导'
from
emp b
right outer join
emp a
on
a.mgr = b.empno;外连接最重要的特点是:主表的数据无条件的全部查询出来。
案例:找出哪个部门没有员工?
select
d.*
from
emp e
right join
dept d
on
e.deptno = d.deptno
where
e.empno is null;2.5 三表之间的连接查询
案例:找出每一个员工的部门名称以及工资等级。
....
A
join
B
join
C
on
...
表示:A表和B表先进行表连接,连接之后A表继续和C表进行连接。
select
e.ename,d.dname,s.grade
from
emp e
join
dept d
on
e.deptno = d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal;案例:找出每一个员工的部门名称、工资等级、以及上级领导。
select
e.ename '员工',d.dname,s.grade,e1.ename '领导'
from
emp e
join
dept d
on
e.deptno = d.deptno
join
salgrade s
on
e.sal between s.losal and s.hisal
left join
emp e1
on
e.mgr = e1.empno;3、子查询
什么是子查询?
select语句当中嵌套select语句,被嵌套的select语句是子查询。
-- 子查询可以出现在哪里?
select
..(select).
from
..(select).
where
..(select).3.1 where子句中使用子查询
案例:找出高于平均薪资的员工信息。
select * from emp where sal > avg(sal); //错误的写法,where后面不能直接使用分组函数。第一步:找出平均薪资
select avg(sal) from emp;第二步:where过滤
select * from emp where sal > 2073.214286;第一步和第二步合并:
select * from emp where sal > (select avg(sal) from emp);3.2 from后面嵌套子查询
案例:找出每个部门平均薪水的等级。
第一步:找出每个部门平均薪水(按照部门编号分组,求sal的平均值)
select deptno,avg(sal) as avgsal from emp group by deptno;第二步:将以上的查询结果当做临时表t,让t表和salgrade s表连接,
条件是:t.avgsal between s.losal and s.hisal
select
t.*,s.grade
from
(select deptno,avg(sal) as avgsal from emp group by deptno) t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;案例:找出每个部门平均的薪水等级。
第一步:找出每个员工的薪水等级。
select e.ename,e.sal,e.deptno,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal;第二步:基于以上结果,继续按照deptno分组,求grade平均值。
select
e.deptno,avg(s.grade)
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal
group by
e.deptno;3.3 在select后面嵌套子查询。
案例:找出每个员工所在的部门名称,要求显示员工名和部门名。
select
e.ename,d.dname
from
emp e
join
dept d
on
e.deptno = d.deptno;select
e.ename,(select d.dname from dept d where e.deptno = d.deptno) as dname
from
emp e;3.4 子查询中in和exists的使用
案例:查询部门为RESEARCH或者SALES的所有员工信息
select * from emp where deptno in (select deptno from dept where dname = 'RESEARCH' or dname = 'SALES');注意:not in在查询结果包含null值时会出现问题。
所以使用exists替换。
select * from emp where exists (select * from dept where dname = 'RESEARCH' or dname = 'SALES');














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











