







一、问题本质:雪花算法为何害怕时钟回退?
雪花算法(Snowflake)通过41 位时间戳 + 10 位工作节点 + 12 位序列号生成 64 位 ID,核心依赖时间戳单调递增。当服务器因 NTP 同步、硬件故障等原因出现时钟回退(如时间从 16:00:00 回退到 15:59:59),会导致以下问题:
1、时间戳变小
新生成的时间戳小于上一次的时间戳,可能与历史 ID 的时间戳重叠
2、序列号重复
同一工作节点在相同时间戳内序列号循环(12 位序列号最大值 4095)
若不处理,可能导致ID 重复生成,破坏幂等性设计的根基(如重复领券、订单重复提交)。
二、雪花算法时钟回退的三大场景
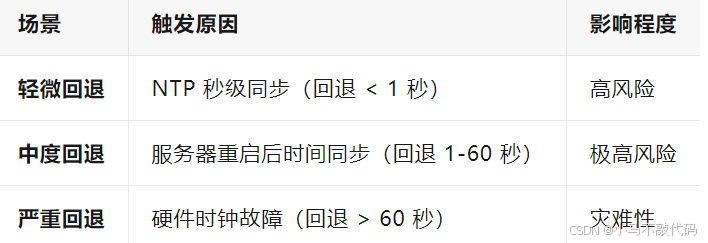
案例:某电商服务器因 NTP 配置错误,凌晨 3 点回退 5 分钟,导致 3 万 + 订单 ID 重复,最终引发库存超卖和用户投诉。
三、解决方案一:时钟回退检测与补偿机制
1. 基础防御:时间戳校验与自旋等待
在生成 ID 时,若检测到当前时间戳小于上一次生成时间戳,进入补偿逻辑:
public synchronized long generateId() {
long currentTime = System.currentTimeMillis();
if (currentTime < lastTimestamp) { // 检测到时钟回退
// 方案1:等待至回退时间结束(适用于轻微回退)
long waitTime = lastTimestamp - currentTime;
try {
Thread.sleep(waitTime);
} catch (InterruptedException e) {
throw new IdGenerateException("Clock backtrack error");
}
currentTime = System.currentTimeMillis();
if (currentTime < lastTimestamp) { // 等待后仍回退,抛出异常
throw new IdGenerateException("Clock backtrack over 10ms");
}
}
// 正常生成ID逻辑...
return combineTimestampWorkerSequence(currentTime);
}
2. 进阶方案:时间窗口容错
为工作节点维护一个容错时间窗口(如 5 分钟),记录历史时间戳区间。当回退时间在窗口内时,通过调整序列号生成策略避免重复;若回退超过窗口,则直接拒绝生成 ID 并报警。
四、解决方案二:序列号空间扩展与冲突处理
1. 动态序列号调整
当检测到时间戳回退但未超过容错窗口时,通过以下方式调整序列号:
回退时间戳在当前窗口内
重置序列号为历史最大序列号 + 1(需存储工作节点的历史序列号)
回退时间戳跨窗口
扩展序列号位数(牺牲部分工作节点数),例如将 10 位工作节点压缩为 9 位,增加 1 位序列号空间
2. 冲突检测与重试
在 ID 生成后,通过 Redis 或数据库进行唯一性预校验(仅在高风险场景启用):
// 预校验ID唯一性(幂等性增强)
public boolean preCheckIdUniqueness(long id) {
String key = "id:lock:" + id;
try (Jedis jedis = jedisPool.getResource()) {
return jedis.setnx(key, "1", "NX", "EX", 10) == 1;
}
}
五、工业级改进:Google UUIDv6 与时间戳重构
1. UUIDv6 的启示
Google 提出的 UUIDv6 方案将时间戳放在高位,并采用单调递增时钟计数器替代雪花算法的序列号,从设计上避免时钟回退问题:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix timestamp (高位) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| clock sequence (避免回退) | node ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
2. 雪花算法改良版(支持时钟回退)
public class ImprovedSnowflake {
private long lastTimestamp = -1L;
private long sequence = 0L;
private final long workerId;
// 新增:回退时间记录表(存储时间戳→最大序列号)
private final ConcurrentHashMap<Long, Long> backtrackMap = new ConcurrentHashMap<>();
public ImprovedSnowflake(long workerId) {
this.workerId = workerId;
}
public synchronized long generateId() {
long currentTime = System.currentTimeMillis();
if (currentTime < lastTimestamp) { // 处理时钟回退
Long lastSeq = backtrackMap.get(currentTime);
sequence = (lastSeq == null) ? 0 : lastSeq + 1;
backtrackMap.put(currentTime, sequence);
} else {
sequence = (currentTime == lastTimestamp) ? (sequence + 1) & 0xFFF : 0;
}
lastTimestamp = currentTime;
return (currentTime << 22) | (workerId << 12) | sequence;
}
}
六、最佳实践:多维度保障 ID 唯一性
算法层
选择支持时钟回退的 ID 生成算法(如改良雪花算法、UUIDv6)
校验层
在业务层对关键 ID(如订单号、交易 ID)进行唯一性校验(通过数据库唯一索引或 Redis 预占)
监控层
实时监控 ID 生成器的时钟偏移量,设置预警阈值(如连续 10 次回退触发熔断)
补偿层
针对已生成的重复 ID,通过业务状态机(如订单状态为 “处理中” 时拒绝重复提交)进行容错
结语
时钟回退是分布式系统中不可忽视的隐性风险,直接考验 ID 生成机制的鲁棒性。通过在雪花算法中加入回退检测、序列号动态调整、唯一性预校验等机制,可将 ID 重复概率降低至万亿分之一以下,为幂等性设计提供坚实保障。


















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











