







不论是向量化模型还是大语言模型,都存在输入长度的限制。对于超过限制的文本,模型会进行截断,造成语义缺失。分块可以确保每个文本片段都在模型的处理范围内,避免重要信息的丢失。
文本分块的核心原则
高质量分块的核心原则是:一个分块应当表示一个完整且语义相关的上下文信息。
这意味着:
- 分块过小:会导致语义信息被割裂,检索时可能错过真正相关的内容
- 分块过大:一个块内可能包含多个不相关的上下文信息,增加检索噪声
实际应用中,合理的分块大小通常在几百到一千多个token之间,但具体应根据文档特性和应用场景灵活调整。
主流分块策略详解
1. 递归文本分块
递归文本分块是最常用的分块策略,其核心思想是根据特定的分隔符(段落、句子、单词等)对文档进行递归分割。
工作原理:
- 指定目标块大小(如200个token,不要超过embedding尺寸)
- 定义由粗到细的分隔符列表(段落 > 句子 > 单词 > 字符)
- 先使用最粗的分隔符(如段落标记)拆分文本
- 检查拆分结果,如果某块大小超过目标值,则使用下一级更细的分隔符继续拆分
- 重复此过程,直到所有块都不超过目标大小
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 创建递归文本分块器
text_splitter = RecursiveCharacterTextSplitter(
# 设置块大小
chunk_size=500,
# 设置块间重叠部分
chunk_overlap=50,
# 按优先级定义分隔符
separators=["\n\n", "\n", "。", ",", " ", ""]
)
# 进行分块
chunks = text_splitter.split_text(long_text)
chunk_overlap 重叠设置:
分块时通常会设置一定的重叠区域(overlap),可以保持上下文连贯性,避免关键信息在块边界处断裂

separators 分隔符设置:
不同类型的文档可能需要特定的分隔符设置:
- 中文文档:应增加中文标点符号(如"。“、”,")作为分隔符
- Markdown文档:可使用标题标记(#、##)、代码块标记(```)等作为分隔符
2. 基于语义的分块策略
递归文本分块基于预定义规则工作,虽然简单高效,但可能无法准确捕捉语义变化。
基于语义的分块策略则直接分析文本内容,根据语义相似度判断分块位置。
基于Embedding的语义分块
这种方法利用向量表示捕捉语义变化,可分为四个步骤:
- 将文档拆分为句子级别的基本单位
- 设定滑动窗口(如包含3个句子)
- 计算相邻窗口文本的embedding相似度
- 当相似度低于设定阈值时,在该位置进行分块
from langchain.text_splitter import SentenceTransformersTokenTextSplitter
# 创建基于语义的分块器
semantic_splitter = SentenceTransformersTokenTextSplitter(
model_name="all-MiniLM-L6-v2", # 指定embedding模型
# 选择阈值策略
threshold_strategy="percentile", # 百分位策略
threshold=0.95, # 95%分位数作为阈值
window_size=3 # 滑动窗口大小
)
# 分块
semantic_chunks = semantic_splitter.split_text(long_text)
阈值选择策略包括:
- 百分位策略:对所有相似度值排序,选择特定百分位的值作为阈值
- 标准差策略:基于相似度的统计分布确定阈值
- 四分位策略:使用四分位数统计确定阈值
基于模型的端到端语义分块
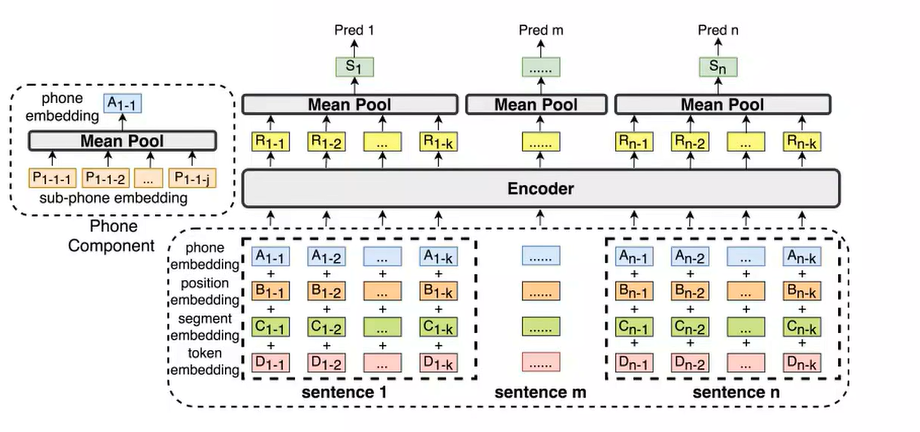
更先进的方法是使用专门训练的神经网络模型,直接判断每个句子是否应作为分块点。这种方法无需手动设置阈值,而是由模型端到端地完成分块决策。
以阿里达摩院开发的语义分块模型为例,其工作流程为:
- 将文本窗口中的N个句子输入模型
- 模型为每个句子生成表示向量
- 通过二分类层直接判断每个句子是否为分块点
from modelscope.pipelines import pipeline
# 加载语义分块模型
semantic_segmentation = pipeline(
'text-semantic-segmentation',
model='damo/nlp_bert_semantic-segmentation_chinese-base'
)
# 进行分块
result = semantic_segmentation(long_text)
segments = result['text']
这种方法的优势在于模型已经学习了语义变化的复杂模式,无需手动调整参数。但需注意模型的泛化能力,应在特定领域文档上进行验证。


















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











