







Automatic Interactive Evaluation for Large Language Models with State Aware Patient Simulator
Authors: Yusheng Liao, Yutong Meng, Yuhao Wang, Hongcheng Liu, Yanfeng Wang, Yu Wang**
Abstract
“ yet the LLMs’ application within the medical field reamains insufficiently explored.”
“ Previous works mainly focus on the performance of medical knowledge with examination, which is far from the realistic scenarios, falling short in assessing the abilities of LLMs on clinical tasks.”
“ In the quest to enhance the application of Large Language Models (LLMs) in healthcare, this paper introduces the Automated Interactive Evaluation (AEI) framework and the State-Aware Patient Simulator (SAPS).”
"Unlike priot methods that rely on static medical knowledge assessments, AIE and SAPS provide a dynamic, realistic platform for assessing LLMs through mutli-turn doctor-patient simulations. This approach offers a closer approximation to real clinical scenarios and allows for a detailed analysis of LLM bahaviors in response to complex patient interactions. "
“ Our extensive experimental validation demonstrates the effectiveness of the AIE framework, with outcoms that align well with human evaluations, underscoring its potential to revolutionize medical LLM testing for improved healthcare delivery.”
1. Introduction
“LLMs, such as ChatGPT OpenAI (2022) and GPT-4 OpenAI (2023) …”
“Their impact in the medical domain has not been equally profound Tian et al. (2024); Thirunavukarasu et al. (2023); Yang et al. (2023). ”
“ Although previous works have developed several specific LLMs for the medical domain Han et al. (2023); Wang et al. (2023); Yunxiang et al. (2023); Xiong et al. (2023), practical applications in clinical settings remain scarce, with notable exceptions such as Med-PaLM 2 Singhal et al. (2023). ”
“ This challenge is primarily due to the misalignment between existing evaluation methods and the specific demands of clinical scenarios Zhou et al. (2023); Minssen et al. (2023); Tu et al. (2024), hindering the deployment of medical LLMs for effective healthcare consultations.”
“ Notably, while established benchmarks focus on medical knowledge performance through examinations Jin et al. (2019); Pal et al. (2022); Jin et al. (2020), they inadequately assess LLMs on crucial clinical tasks like pre-consultation and diagnostic assistance Yang et al. (2023).”
“ Additionally, benchmarks for complex clinical tasks either limit models to constrained action space Wei et al. (2018); Chen et al. (2022) or simplify dynamic interactions into static question-answering formats Zhao et al. (2022); Liu et al. (2022), thus failing to replicate the complexities of actual clinical interactions. ”
“ To bridge the gap between testing and clinical requirements, some studies have employed numerous human participants to role-play as patients interacting with LLMs in real-time, simulating clinical scenarios to assess the capabilities of the LLMs Tu et al. (2024). However, this approach incurs high costs and lacks scalability, limiting its practical application in the widespread development and testing of medical models. Therefore, it is imperative to develop a low-cost yet efficient method for automatically evaluating the clinical capabilities of LLMs in the medical domain. ”
“ To address these gaps, in this paper, we propose a novel evaluation approach, Automatic Interactive Evaluation (AIE), as detailed in Fig. 1. This method leverages the role-playing capability of LLMs to act as a patient simulator Shanahan et al. (2023), engaging in dynamic multi-turn interactions with the doctor LLMs under the evaluation. ”

Fig. 1: Overview of the Automatic Interactive Evaluation framework. a. State Aware Patient Simulator (SAPS). SAPS structure includes a state tracker for classifying doctor behaviors, a memory bank for information retrieval, and a response generator for creating replies.Sentences with a dark background represent the parts that are activated within SAPS. b. Conversation history between SAPS and Doctor LLM. The diaglogue with a black border represents the latest round of diaglogue. d. Evaluated doctor LLM and its prompts. e. Diagnosis. After the consultation diaglogue, the doctor model must diagnose based on the information gathered during the conversation. ‘Conversation’ indicates the diaglogue history.
“ The concept of doctor LLMs refers to LLMs tested for their diagnostic interaction capabilities within the AIE framework. These doctor LLMs must gather extensive patient information through diaglogue, leading to a diagnosis or recommendation. AIE seeks to simulate clinical scenarios more accurately, presenting a complex challenge that surpasses previous methodologies and offers a deeper assessment of LLM capabilitie within a practical healthcare context. this is the first evaluation to interactively validate the consultation ability of LLMs through such a patient simulator.”
" Additionally, inspired by task-oriented diaglogue systems Wen et al. (2016), we develop a unique construct for the patient simulator named the State Aware Patient Simulator (SAPS). This construct includes three main components: a state tracker, a memory bank, and a response generator, which collectively enable the simulation of patient-doctor interactions.
- At each diaglogue turn, the state tracker categorizes the doctor LLM’s action into predefined types, allowing SAPS to retrieve relevant information from the memory bank and generate appropriate repsonses.
- Importantly, we defined 10 categories of actions based on their nature and effectiveness, as observed in preliminary experiments.
The empirical evaluation of AIE involves a two-step process. Initially, the effectiveness of SAPS is validated against a simulated patient test set derived from actual hospital cases. Subsequently, the evaluation metrics, developed based on human and patient preferences and aligned with standards such as the UK General Medical Council Patient Questionaire (GM-CPQ) and principles from the concensus on patient-centered communication (PCCBP) King & Hoppe (2013) .
2. Results
2.1 Overview
In this section,
- we first analyze the performance of the SAPS in multi-turn interactions to ensure its effective engagement with doctor LLMs.
- Subsequently, the SAPS and doctor LLMS’ diagnostic diaglogues are evaluated and scored using three types of methods: human evaluation and two forms of automatic evaluation, including GPT-4 evaluation Liu et al. (2023) and automated metric avaluation. We then analyze the correlation among the results of these three methods to validate the appropriateness of indicators.
- Finally, the performance of the doctor LLMs in multi-turn diagnostic diaglogues is examined on the publicly available bencmarks to demonstrate the scalability of the AIE framework.
2.2 Datasets
We have developed two test sets. The first set aims to validate effectiveness of the SAPS framework, while the second is for the AIE framework.
2.2.1 Patient Simulator Test Sets
We randomly select 50 real hospital cases to represent patient information.
We use GPT-4 to simulate the roels of both doctor and patient, creating 10 rounds of dialogue for each case.
Depending on the dialogue context, GPT-4 can generate question-answer pairs based on
preset doctor LLM action types. [what’s meaning?]
Human reviewers then refine the answer and action type for each question.
This process produces 4000 test questions in total. These can evaluate how patient simulators react to different actions across various context lengths and effectively measure their interactive performance in consultation dialogues.
2.2.2 Doctor LLMs Test Sets
We establish two datasets to evaluate doctor LLMs using real cases and public datasets.
The first dataset, HospitalCases, includes 50 real hospital cases that do not overlap with the patient simulator test set. Each case comprises patient information, examination results, and diagnoses.
We utilize GPT-4 to generate four similar yet distinct diseases as distractors, which are formatted as multiple-choice questions.
The second dataset, MedicalExam , encompasses 150 cases chosen from five public clinical examination datasets, including MedQA Jin et al. (2022), MedMCQA Pal et al. (2022), MMLU Hendrycks et al. (2021), SelfExam Kung et al. (2023), and QMAX. These cases feature extensive patient information and diagnosis-related questions.
2.3 Results of Patient Simulators

Fig. 2: Results on the patient simulator test set. We employ the six predefined patient metrics to evaluate the performance of different models and humans. a. Change of metrics over dialogue turns. The bars and the lines in each plot describe the average scores and the relationship between the metrics and the number of dialogue turns, respectively. b. Correlation between patient models and humans. Corr means the value of the correlation factor. c. Confusion matrix for state tracking between patient agent and humans.
2.4 Comparative Evaluation on HospitalCases

Fig. 3: Success rate without tie in comparative evaluation of doctor LLMs. The first and second rows show the results of the human evaluation from the perspective of the doctor and patient, respectively. The third and fourth rows show the results of the GPT-4 evaluation from the perspective of the doctor and patient.
“ To avoid the instability caused by absolute scoring, we employ comparative evaluation to assess the consultation dialogues. Specifically, the dialogues of different doctor LLMs for the same case are compared pairwise to determine the more effective LLMs. We hire three medical students and normal people to play the role of doctor and patient, respectively, and choose their preference from the perspective of each metric. Additionally, we also employ various prompts to enable GPT-4 to conduct automatic evaluations from the perspectives of both the doctor and patient. ”
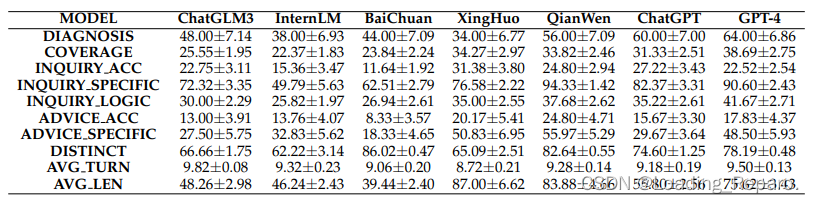
2.5 Automatic Metrics Evaluation on HospitalCases
Table 1: Results of the automatic metrics on HospitalCases. The results are shown in the formation ‘
m
e
a
n
±
s
t
a
n
d
a
r
d
mean \pm standard
mean±standard
e
r
r
o
r
error
error’.
2.6 Metrics Correlation Analysis

Fig. 4: Analysis of the correlation between automated metrics, GPT-4, and human assessment indicators. All indicators’ correlations are tested. Considering the automated metrics are continuous, and GPT-4 and human assessments are ordinal, the Spearman correlation coefficient is used to calculate the correlation between different indicators. a. assesses correlation across all test data. b. the average human correlation coefficient between automated metrics and GPT-4 assessments. c-e. explore correlations within specific subsets: c. both models in the comparison are closed-source, d. both models in the comparison are open-source, e. one model is open-source and the other is closed-source.
2.7 Correlation Analysis among Different Subsets
[Details seen in the original paper in this section]
Seen Fig. 4.
2.8 Automatic Evaluation on MedicalExam
Table 2: Results of the automatic metrics on MedicalExam. The results are shown in the formation ‘
m
e
a
n
±
s
t
a
n
d
a
r
d
mean \pm standard
mean±standard
e
r
r
o
r
error
error.’


Fig. 5: Analysis of the evaluated doctor LLMs on MedicalExam datasets. a. The average win rate of each metric within the GPT-4 evaluation. We use the best results as the maximum value for each metric in the radar chart. b. Comparison of the diagnostic score between the Multiple-Choice Question Evaluation (MCQE) and AIE among five subsets. c. The proportion of the action categories within each turn. d. The coverage and diagnostic scores depend on different consultation conversation lengths. The red lines connecting circular red dots represent diagnostic scores, while the blue box plots indicate coverage scores.
2.9 Evaluation Format Analysis
Seen Fig. 5
2.10 Turn Analysis
Seen Fig. 5
3. Discussion [Seen in paper later]
4. Methods [important!!!]
4.1 Evaluated Large Language Models
In general, most existing LLMs can be divided into the genral LLMs and the domain LLMs, which specifically refer to the medical LLMs in this paper. Preliminary experiments have shown that the instruction-following ability of many medical LLMs is compromised, causing them to fail multi-turn consultation tasks requiring complex instructions.
As such, we are selecting genral LLMs with strong instruction-following capbabilities and bilingualism to maintain fairness in experimental comparison.
For the closed-source models, ChatGPT OpenAI (2022), GPT-4 OpenAI (2023), Xinghuo, and Qianwen Bai et al. (2023) are selected. For the open-source models, Internlm-20b Team (2023) , Baichuan-13b Yang et al. (2023), and ChatGLM3-6b Du et al. (2022) are selected.
- Specifically, we use the version gpt-3.5-turbo-1106 for ChatGPT and gpt-4-1106-preview for GPT-4.
- For Xinghuo, we use the version of generalv3.
- For QianWen, we use the version of qwen_max.
- For the closed-source models, we use the ChatGLM3-6B available at: ChatGLM3-6b; Baichuan-13B-Chat available at: BaiChuan-13b; and InternLM2-Chat-20B available at: InternLM-20b.
4.2 State Aware Patient Simulator
During the consultation conversation, the patient agent is required to provide tailored repsonses according to different types of questions.
However, directly prompting LLMs makes it difficult to control the behavior of the patient simulator precisely.
To enhance the precision of patient simulators in consultation dialogues, we introduce a State Aware Patient Simulator (SAPS).
SAPS consists of three integral components:
- a state tracker that identifies and classifies the current action state of the doctor LLMs.
- a memory bank that stores various information and selects the appropriate memory according to the state.
- a response generator that produces contextually relevant replies.
4.2.1 States definition and response requirements
Our appoach categorizes the types of actions performed by doctors during medical consultations from two key perspectives:
- The first perspective classifies the actions into distinct categories that cover the array of interactions that a doctor might have during a patient consultation.
- The second perspective evaluates the effectiveness of these actions, concentrating on whether they successfully gather pertinent information and offer suitable advice.
Consequently, we predefine 10 categories of states and their corresponding requirements in the consultation conversation as follows:





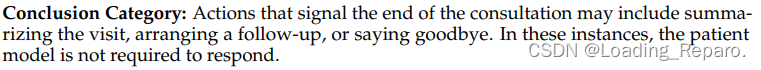
4.2.2 State tracker
The state tracker plays a role in categorizing the actions of doctor LLMs into a predefined type. The prediction process can be divided into three steps:
-
The first step is to classify the current action into five main categories (mentioned above 4.2.1), excluding the initial category.
-
SAPS classifies the action with the use of prompt as follows:
In the process of medical consultation, a doctor’s questions can be classified into five types: (A) Inquiry: The doctor asks the patient for medical and disease-related symptom information. Generally, questions with a ’?’ that do not belong to categories (C) or (D) are included in this category. (B) Advice: The doctor suggests that the patient visit a hospital for consultation, undergo examinations, or provide certain treatment plans. Questions containing the keyword ’suggestion’ belong to this category. (C) Demand: The doctor asks the patient to perform certain actions for observation, cooperation, or sensation. Actions include but are not limited to opening the mouth, lying on the side, standing, pressing, etc. (D) Other Topics: The doctor’s questions do not pertain to the medical consultation context and are unrelated to medical diseases. This includes, but is not limited to, hobbies, movies, food, etc. (E) Conclusion: The doctor has completed the consultation and does not require a response from the patient. ~Based on the descriptions of the above question types, please choose the most appropriate category for the following <Doctor_Question>: <Doctor_Question>: {{{question}}} <Question_Type>: {Type}(" To induce the LLMs to generate valid repsonses, we take advantage of the logit_bias technique Nori et al. (2023) to enforce the model only genrate the category index. ")
-
-
If the current action falls into the categories of inquiry or advice, the second step of classification is to determine whether the action is specific or ambiguous. For inquiries and advice, different prompts are used to facilitate this distinction.
-
For the inquires category, the prompt is shown below:
<Definition>: [Specific]: <Question> has a certain specific direction. When asking about symptoms, it should at least inquire about specific body parts, symptoms, sensations, or situations. When asking about examination results, it should mention specific body parts, specific examination items, or abnormal situations. Note that if it's about specific medical conditions, like medical history, family history, chronic illnesses, surgical history, etc., they are always considered as [Specific]. Specifically, if the <Question> contains demonstrative like "these" or "this", then it is related to the above and should belong to the [Specific]. [Ambiguous]: <Question> such as "Where do you feel uncomfortable?" or "Where does it feel strange?" without any specific information direction are considered as [Ambiguous]. <Question>: {question} Based on the <Definition>, determine whether the doctor's <Question> asks for [Specific] medical information from the patient or gives [Specific] advice. If so, directly output [Specific]. If not, output [Ambiguous]. -
For the advice catgory, the prompt is shown below:
<Definition>: [Specific]: <Advice> contains specific types of examinations or test (including but not limited to X-rays, MRI, biopsy, etc.), specific treatment plans (including but not limited to specific surgical treatments, exercises, diets, etc.), specific types of medication, etc. [Ambiguous]: <Advice> broadly given without any specific examination/test, threatment plans, doctor's orders, excercises, diets, and medication types are considered [Ambiguous]. As long as any of the above information appears, <Advice> does not fall into this category. <Advice>: {question} Based on the <Definition>, determine whether the doctor's <Advice> ask for [Specific] medical information from the patient or gives [Specific] advice. If so, directly output [Specific]. If not, output [Ambiguous].
-
-
If the action isdetermined to be specific, the next step is to assess whether there is a corresponding answer within the patient information. Similarly, we also prepare two types of prompts for the inquiry and advice:
-
For Inquiry:
<Definition>: [Relevant Information]: <Patient_Information> contains information asked in <Question>, including descriptions of having or not having the symptom, as long as there's relevant content. [No Relevant Information]: <Patient_Information> does not contain the information asked in <Question>, and there's not relevant content in the information. <Patient_information>: {patient_info} <Question>: {question} Based on the <Definition>, determine whether <Patient_Information> contains relevant information asked in <Question>. If [Relevant Information] is present, directly output the relevant text statement, ensuring not to include irrelevant content. If [No Relevant Information], then directly output [No Relevant Information]. -
For Advice:
<Definition>: [Relevant Information]: <Patient_Information> contains results of the examinations or treatment plans suggested in <Advice>m including anyresults related to the suggested examination items and treatment plans. [No Relevant Information]: <Patient_Information> does not contain results of the examinations or treatment plans suggested in <Advice>, including no mention of relevant examination items and treatment plans or no corresponding results. <Patient_information>: {patient_info} <Advice>: {question} Based on the <Definition>, determine whether <Patient_Information> contains relevant information about the measures suggested in <Advice>. If [Relevant Information] is present, directly output the relevant text statement, ensuring not to include irrelevant content. If [No Relevant Information], then directly output [No Relevant Information].
-
In conclusion, the predicted categories at each turn can be identified as:
S
i
^
=
ϕ
S
T
r
a
k
e
r
(
D
i
,
M
l
o
n
g
)
\hat{S_{i}}=\phi{_{STraker}}(D_{i},\mathbf{M_{long}})
Si^=ϕSTraker(Di,Mlong)
where D i D_i Di indicates the doctor’s output of the i i i turn and ϕ S T r a k e r \phi{_{STraker}} ϕSTraker is the LLMs.
4.2.3 Memory bank
Upon identifying the current action type of the doctor LLM through the state tracker, SAPS can selectively access different parts of the memory bank.
-
Long-term Memory:
This component stores the patient information M l o n g \mathbf{M_{long}} Mlong and remains consistent during the interaction. the details contained in long-term memory, such as medical history, personal health data, and possibly previous experiences with healthcare, are crucial to play the patient’s role, which enables the SAPS to provide consistent and accurate information during the consultation process.
In each turn, the long-term memory will extract the corresponding information relevant to the doctor’s actions only when their types belong to the effective inquiry and effective advice categories. The extracted process of the long-term memory in i-th turn can be denoted as:

-
Working Memory:
The working memory M w o r k \mathbf{M_{work}} Mworkwork is pivotal for the adaptive responses of the SAPS to different actions of doctor LLMs. It stores the requirements for responding to each type of action defined in Section 4.2.1, enabling the SAPS to react appropriately to the evolving context of the consultation. Therefore, the working memory of the i-th turn can be denoted as:

-
Short-term Memory:
This part retains the history of the consultation dialogue between the doctor LLM and the SAPS. It will continually with the flow of the conversation.

4.2.4 Respsonse generator
The memory information extracted from the memory bank in i i i-th turn can be noted as m i = { m l o n g , i , m w o r k , i , m s h o r t , i } \mathbf{m_i}=\{ \mathbf{m_{long,i}}, \mathbf{m_{work,i}}, \mathbf{m_{short,i}} \} mi={mlong,i,mwork,i,mshort,i} and the prompt for the response generator will be organized as the context in the predefined formatt as below:
<Patient_Information>:
{long_term_memory}
<Requirements>:
{working_memory}
The following is a conversation between a doctor and a patient. The patient will respond to the latest round of the doctor's question in the first person according to the <Requirements>. Note that do not output any text content in <Requirements>!
<Dialog>:
{short_term_memory}
[Doctor]:
{doctor_question}
4.3 Medical LLMs Evaluation Pipeline
Seen in paper.
4.4 Evaluation Metrics (click here to see original paper.)
4.4.1 Patient Simulator Evaluation Metrics(important)
Seen in paper.
4.4.2 Doctor LLMs Automatics Evaluation Metrics(important)
Seen in paper.
4.4.3 Doctor LLMs Human Evaluation Metrics(important)
Seen in paper.
4.5 Data
MedQA: click here
MedMCQA: click here
MMLU: click here
SelfExam: click here
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









