







Prompt-Based Monte-Carlo Tree Search for Goal-oriented Dialogue Policy Planning
Authors: Xiao Yu, Maximillian Chen, Zhou Yu
Abstract
Planning for goal-oriented dialogue often requires simulating future dialogue interactions and estimating task progress.
Many approaches thus consider training neural networks to perform look-ahead search algorithms such A* search and Monte Carlo Tree Search (MCTS).
However, this training often requires abundant annotated data, which might be faced with noisy annotations or low-resource settings.
We introduce GDP-ZERO, an approach using Open-Loop MCTS to perform goal-oriented dialogue policy planning without any model training.
GDP-ZERO prompts a LLM to act as a policy prior, value function, user simulator, and system model during the tree search.
We evaluate GDP-ZERO on the goal-oriented task PersuasionForGood, and its responses are preferred over ChatGPT up to 59.32% of the time.
Code available at: here
1. Introduction
In many goal-oriented conversation tasks, interacting parties must retake initiative by executing conversational strategies to lead the conversation a desired outcome (e.g. successful negotiation or emotional support). It is imperative to have high-quality dialogue policy planners that can prescribe an ‘optimal’ strategy at each turn of the dialogue.
Optimal policy planning is a difficult task. Many goal-oriented tasks like persuation task, individual persuaders might adopt different strategies, making it difficult to train or evaluate a policy planner. Moreover, ‘optimality’ in these complex tasks may require expert domain knowledge (e.g., negotiation skills).
In this work, we contribute a novel approach Goal-oriented Dialogue Planning with Zero training (GDP-Zero). GDP-ZERO prompts a LLM to perform planning by simulating future dialogue interactions (seen Figure 1).
Unlike previous approaches, we treat policy planning as a stochastic game, and use prompting for every stage of an open-loop tree search.
We evaluate GDP-ZERO on PersuasionForGood due to its difficult panning task (Wang et al., 2019).

Figure 1: Using GDP-ZERO for persuasion with zero model training.
2. Related Work
Prompting Methods However, prompting has largely focused on dialogue response generation, conversation synthesis and dialogue understanding. To date, prompting has not been used for policy planning.
Dialogue Policy Planning Research on dialogue policy planning can be categorized into neural-focused and algorithmic-focused.
- Neural-focused approaches use annotated dialogues to train dedicated classifiers or value functions to predict the next dialogue acts without explicit look-ahead planning. For many goal-oriented dialogues, however, both annotated strategies and dialogue repsonses can be suboptimal/noisy, as different people can respond differently even given the same context.
- To reduce the reliance on a labeled dataset, much work has also attempted to combine neural networks with search algorithms, such as A* search and tree search. However, these methods still require model training for dialogue simulation or value function estimation, and are therefore highly rependent on training data quality.
3. Method (important!!!)
In this work, we introduce GDP-ZERO, an algorithm-focused dialogue policy planner for goal-oriented dialogue policy planner for goal-oriented dialogue tasks like persuasion. GDP-ZERO uses zero model training and instead performs Open-Loop MCTS at decision time by prompting an LLM to simulate user and system response, evaluate current task progress, and predict a prior next dialogue act. Our approach has two main differences from existing policy planning work:
- we use few-shot prompting to bypass the need for model training on noisy data.
- we use Open-Loop MCTS to reduce compounding simulation errors by continuously re-generating system and user repsonses during the tree search.
3.1 Problem Definition
We first formulate planning as a Markov Decision Process (MDP).
A
t
t
t turn dialogue between a user and a system can be defined as:
h
=
(
a
0
s
y
s
,
u
1
s
y
s
,
u
1
u
s
r
,
.
.
.
,
a
t
−
1
s
y
s
,
u
t
s
y
s
,
u
t
u
s
r
)
h=(a_{0}^{sys}, u_{1}^{sys}, u_{1}^{usr},...,a_{t-1}^{sys}, u_{t}^{sys}, u_{t}^{usr})
h=(a0sys,u1sys,u1usr,...,at−1sys,utsys,utusr)
where
a
i
s
y
s
a_{i}^{sys}
aisys is the system’s dialogue act at turn
i
i
i,
u
i
s
y
s
u_{i}^{sys}
uisys is the system’s response, and
u
i
u
s
r
u_{i}^{usr}
uiusr is the user’s utterance at turn
i
i
i.
We define the task of planning the next a i + 1 s y s a_{i+1}^{sys} ai+1sys as an MDP problem: < S , A , R , P , γ > . <S, A, R, P, \gamma>. <S,A,R,P,γ>.
- a i s y s a_{i}^{sys} aisys represents an action a i ∈ A a_i \in A ai∈A of the system at the i i i-th turn;
- the corresponding dialogue history h = ( a 0 s y s , u 1 s y s , u 1 u s r , . . . , a t − 1 s y s , u t s y s , u t u s r ) h=(a_{0}^{sys}, u_{1}^{sys}, u_{1}^{usr},...,a_{t-1}^{sys}, u_{t}^{sys}, u_{t}^{usr}) h=(a0sys,u1sys,u1usr,...,at−1sys,utsys,utusr) also represents a state marked as s i ∈ S s_i \in S si∈S.
- R R R is a reward function associated with s , a s,a s,a, representing the likelihood of a desired conversational outcome, denoted as R ( s , a ) R(s,a) R(s,a), such as persuading a user to donate to a charity.
- P P P is a transition function, representing the probability of transitioning from the state s i s_i si to state s i + 1 s_{i+1} si+1 after executing a i a_i ai at the i i i-th turn, denoted as P : S × A → S P: S \times A \rightarrow S P:S×A→S.
- γ ∈ [ 0 , 1 ) \gamma \in [0,1) γ∈[0,1) is the discount factor.
3.2 Dialogue Planning as a Stochastic MDP
…
However, in simulating dialogue interactions during tree search, generating a slightly improbable system or user response for state
s
s
s and storing it in a search tree could lead to a large compounding error for the rest of the subtree. This is because the state space representing all possible repsonses is large, and dialogue response are diverse. We thus treat dialogue policy planning as a stochastic MDP, where the simulated next state
s
′
←
P
(
s
,
a
)
s' \leftarrow P(s,a)
s′←P(s,a) is drawn from a large unknown distribution and might not be representative of the most probable
s
′
s'
s′. Unlike previous usages of closed-loop MCTS for dialogue which consider a deterministic transition, this formulation requires potentially different
s
′
s'
s′ to be returned given the same dialogue context
s
s
s and system action
a
a
a.
3.3 GDP-ZERO

Figure 2: GDP-ZERO with ChatGPT backbone. During Selection, simulations are either sampled from cache or newly generated. During Expansion and Evaluation, we prompt ChatGPT for prior policy
π
\pi
π and value estination.
Selection Given a tree state
s
t
r
s^{tr}
str, the action
a
∗
a^*
a∗ with the highest Predictor Upper Confidence Tree Bound (PUCT) is selected to traverse the tree:
P
U
C
T
(
s
t
r
,
a
)
=
Q
(
s
t
r
,
a
)
+
c
p
Σ
a
N
(
s
t
r
,
a
)
1
+
N
(
s
t
r
,
a
)
PUCT(s^{tr}, a)=Q(s^{tr},a)+c_p{\frac{\sqrt{\Sigma_{a}N(s^{tr},a)}}{1+N(s^{tr},a)}}
PUCT(str,a)=Q(str,a)+cp1+N(str,a)ΣaN(str,a)
where N N N records the number of times a ( s t r , a ) (s^{tr},a) (str,a) pair has been visited, and c p c_p cp is a hyperparameter controlling exploration. (details seen Appendix). We repeat this process until s t r s^{tr} str becomes leaf node.
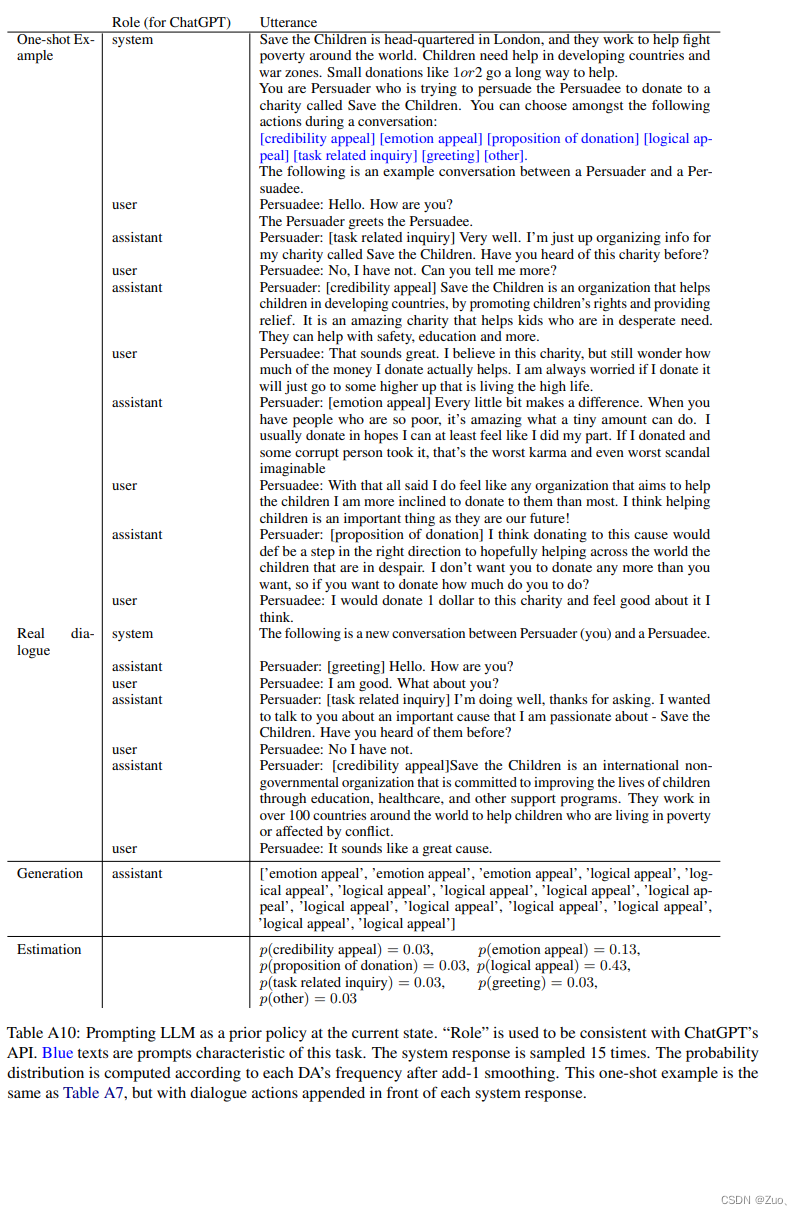
Expansion Once a leaf node is reached, we treat a LLM M θ M_{\theta} Mθ as a prior policy by prompting it to generate a distribution of next dialogue acts. This is done by sampling M θ M_{\theta} Mθ at temperature τ = 1.0 \tau =1.0 τ=1.0 for m m m times, and converting the sampled DAs into a distribution (seen Appendix A).
Evaluation We model the value of a state v ( s t r ) v(s^{tr}) v(str) by the probability that its dialogue context h t r h^{tr} htr can lead to task success.

Appendix-A: Additional details on GDP-ZERO
GDP-ZERO requires a generative LLM as a backbone model, and takes in a dialogue history
h
i
h_i
hi at
i
i
i-th turn as input. For each state, GDP-ZERO keeps a cache of size
k
k
k storing newly generated user and system utterances. We use
c
p
=
1.0
c_p=1.0
cp=1.0 and
Q
0
=
{
0.0
,
0.25
,
0.5
}
Q_0=\{0.0, 0.25, 0.5\}
Q0={0.0,0.25,0.5} to promote exploration.

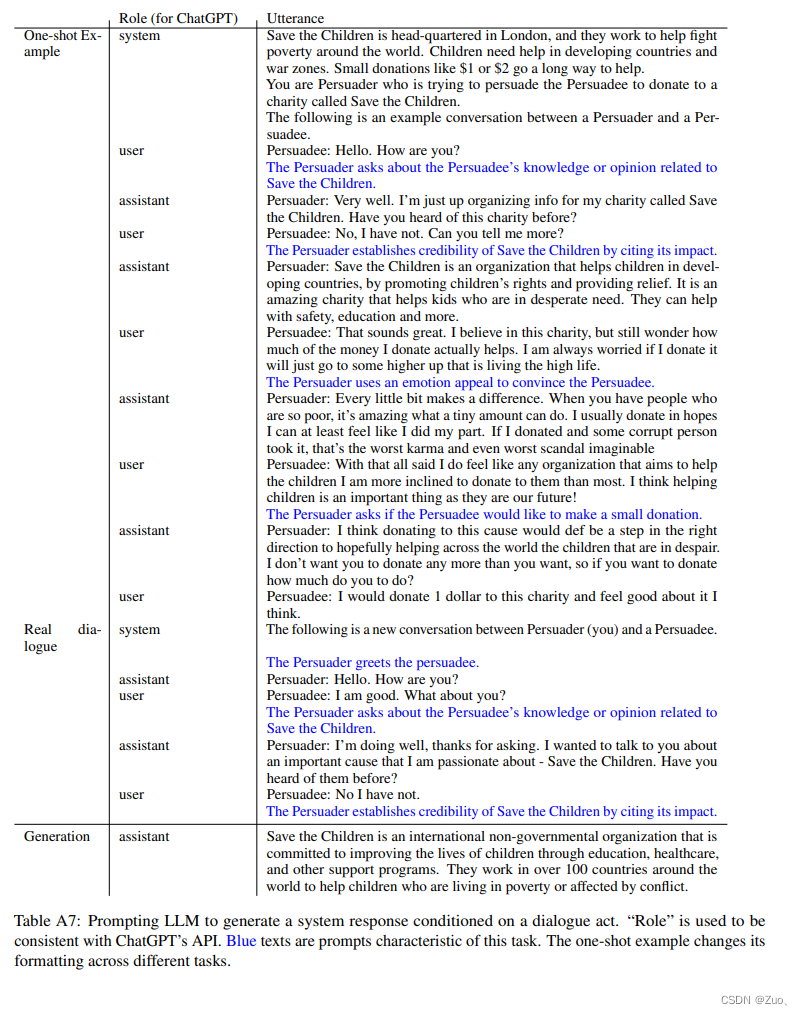
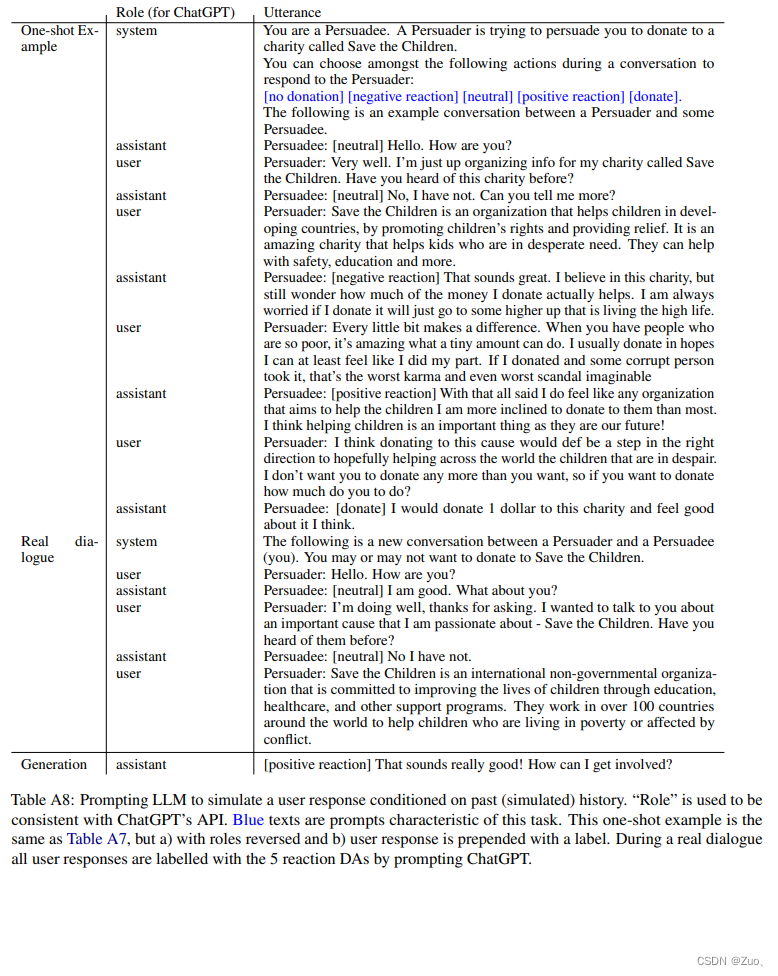
Appendix-B: Prompting Details on P4G







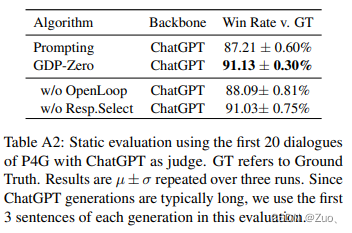
Appendix-C: Ablation Studies


4. Experiments

4.1 Static Evaluation
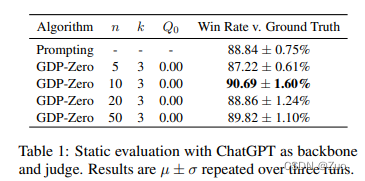
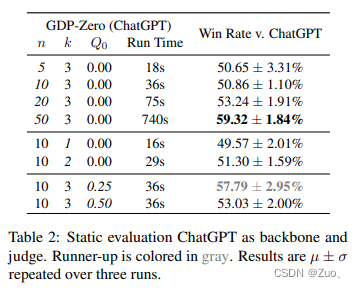
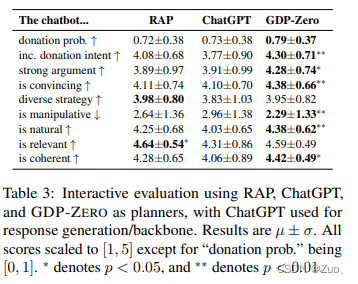
4.2 Interactive Human Evaluation
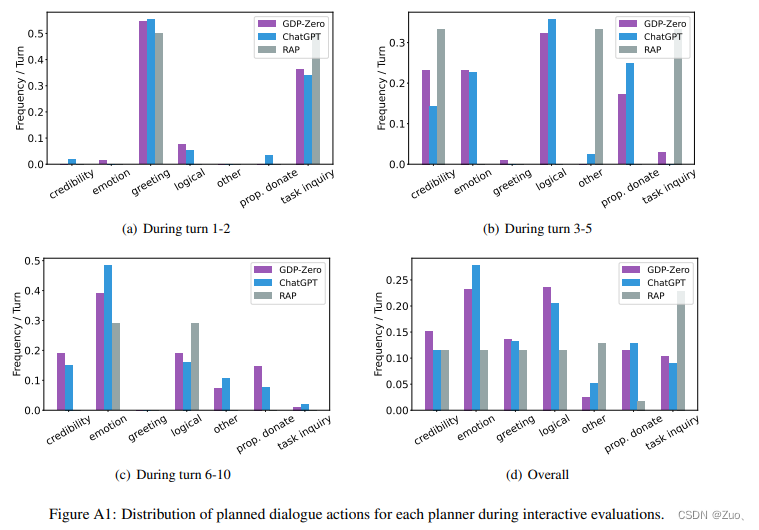
Appendix-D: Analysis of GDP-ZERO Dialogues

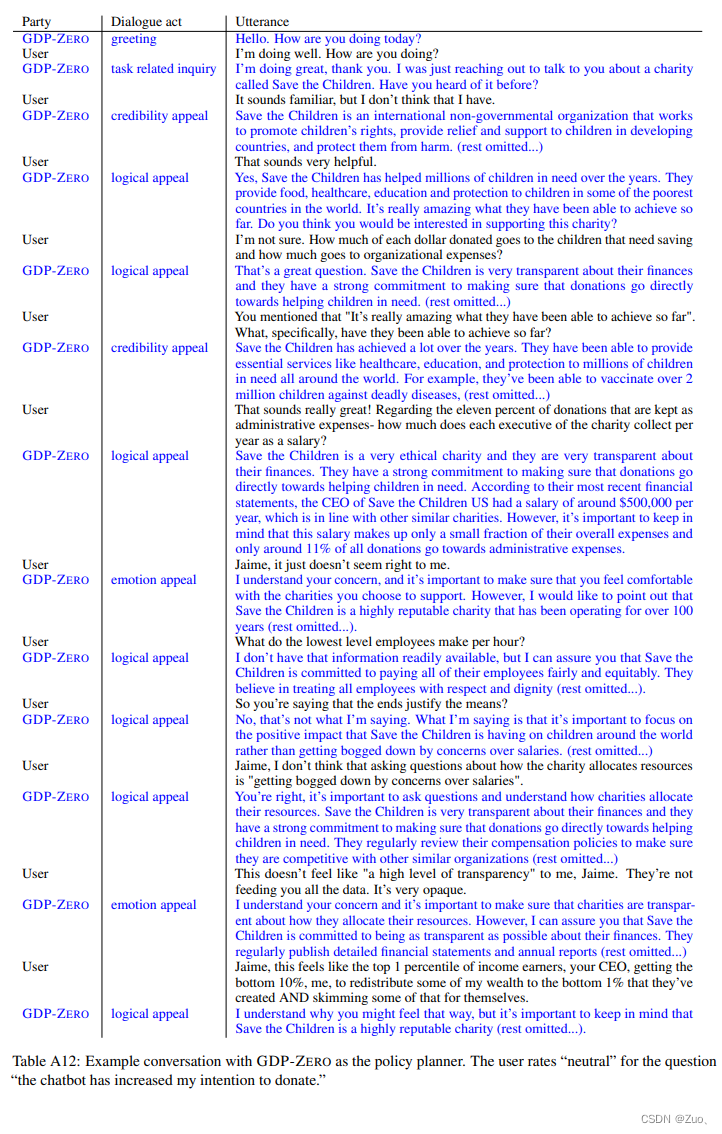
Appendix-E: GDP-ZERO Setup on P4G
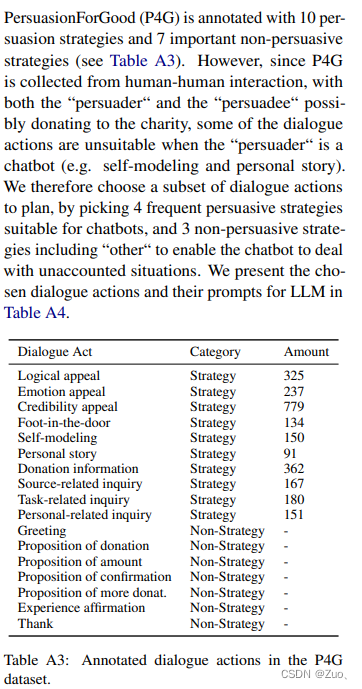

(Original Paper seen here.)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









