







《中国食物成分表2004》(第二册)是对《中国食物成分表2002》(第一册)的重要补充,是对我国食物成分数据资料的又一次丰富和发展。

个人膳食摄入
# ------Personal Food Intake:FCT trans------
## Loading Food Intake Data
library(haven)
library(dplyr)
nutr3_00 <- read_sas("nutr3_00.sas7bdat")
# 直接保留有多次重复的膳食,加快速度
nrow(nutr3_00)
nutr3_00 <- dplyr::filter(nutr3_00,
IDind %in% unique(base_WAVE_count$Idind))
nrow(nutr3_00)
length(unique(nutr3_00$IDind))
nutr3_00$IDind <- as.character(nutr3_00$IDind)
head(nutr3_00)
names(nutr3_00)
food_intake <- dplyr::select(nutr3_00, hhid, IDind, WAVE, V39, FOODCODE ) %>%
dplyr::filter(. ,WAVE>=2004) # 1997才开始有膳食调查
# rm(list = ls()[-match(c("base","food_intake"),ls())])
table(food_intake$WAVE)
names(food_intake)
# 进行转化测试
## Note: 2 coding systems are used after 1997
# FCT 1991: used in 1997 and 2000
# FCT 2002/2004 (two books combined): used in 2004, 2006, 2009, and 2011.
# 补充前面的0
food_intake$FOODCODE[1:1000]
food_intake$FOODCODE <- as.character(food_intake$FOODCODE)
# # 【补全6位数,匹配不上】
# # # 直接切割掉开头的0
# # \\d{1,1} ==0 TURE stringr::str_sub()
food_intake$foodcode_2 <- stringr::str_pad(
string = food_intake$FOODCODE,width = 6,side = "left",pad = "0")
food_intake$foodcode_2[1:1000]
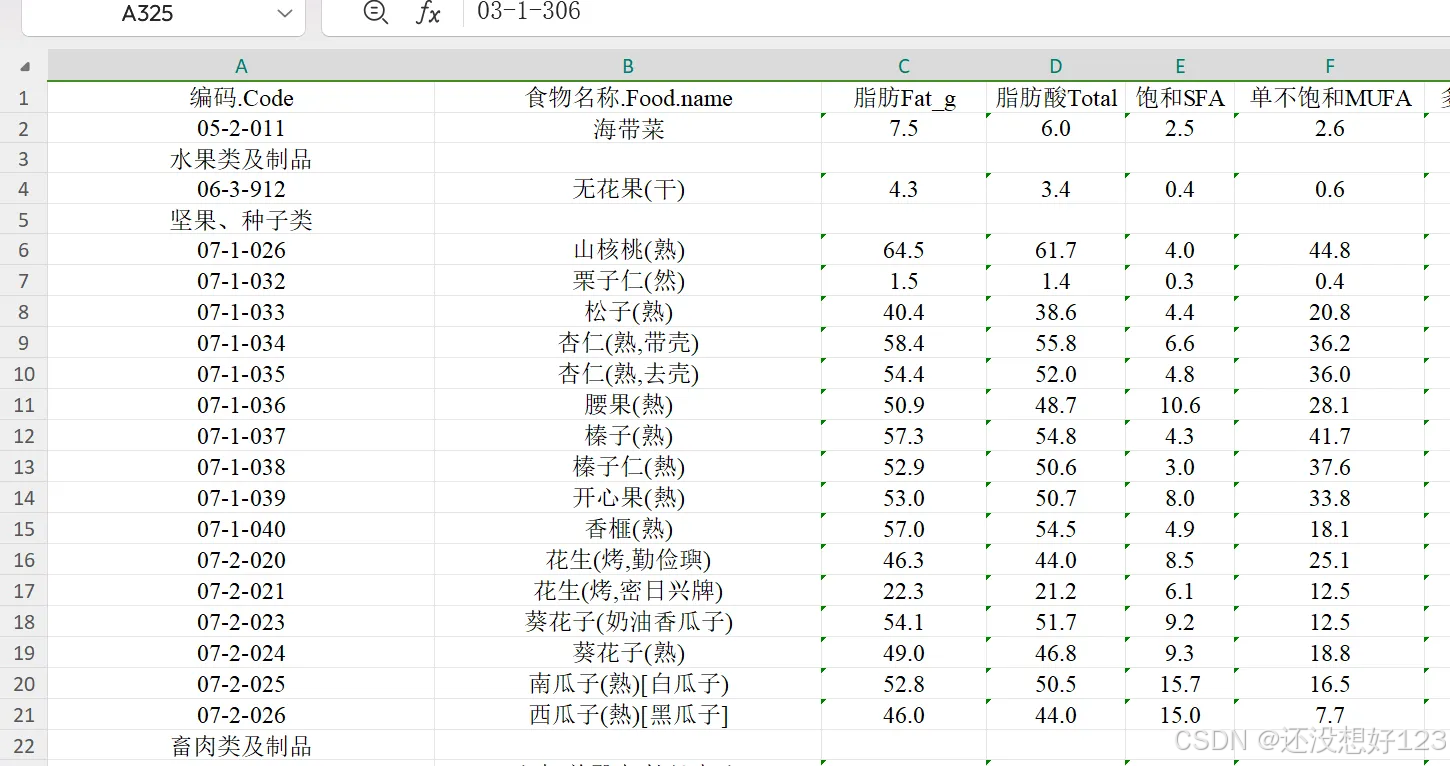
FCT <- openxlsx::read.xlsx("FCT_2002_2004_合并的脂肪酸数据-4.xlsx")
FCT$FCT_foodcode <- gsub(pattern = "-",replacement = "", x = FCT$编码.Code)
names(FCT)
FCT <- dplyr::relocate(FCT, FCT_foodcode,.after = "编码.Code" )
FCT$FCT_foodcode <- FCT$FCT_foodcode
nutr3 <- dplyr::left_join(food_intake, FCT, by=c("foodcode_2"="FCT_foodcode"))
shecha <- dplyr::select(nutr3,FOODCODE,foodcode_2,FOODCODE, 编码.Code)
shecha <- unique(shecha)
openxlsx::write.xlsx(shecha,"SHECHA.xlsx")
nutr3$ID_WAVE <- paste0(nutr3$IDind,"_", nutr3$WAVE)
nutr3$hhid_WAVE <- paste0(nutr3$hhid,"_", nutr3$WAVE)
# nutr3_one <- split(nutr3,list(nutr3$hhid))
#
# nutr3_wave <- purrr::map(nutr3_one,~split(.x,.x[["WAVE"]]))
rm(list = ls()[-match(c("base","nutr3"),ls())])
nutr3$g= nutr3$V39/100
-----个人计算2:每次WAVE的三天平均摄入-----
# -----个人计算2:每次WAVE的三天平均摄入-----
# 直接计算出每次WAVE的三天平均摄入
nutr3 <- readRDS("nutr3.rds")
nutr3$IDind_WAVE <- paste0(nutr3$IDind,"_", nutr3$WAVE)
nutr3$hhid_WAVE <- paste0(nutr3$hhid,"_", nutr3$WAVE)
nutr3 <- tidyr::drop_na(nutr3, 编码.Code)
food_intake_one_list <- split(nutr3, nutr3$ID_WAVE)
qaq=3000
food_intake_one_all_list <- list()
# 有wave多次的,记得再算平均,还要除于3天
for (qaq in seq_along(food_intake_one_list)) {
print(qaq)
food_intake_one_df <- food_intake_one_list[[qaq]]
names(food_intake_one_df)
naaa=nrow(food_intake_one_df)+1
# WAVE_n=length(unique(food_intake_one_df$WAVE))
WAVE <- unique(food_intake_one_df$WAVE)
#
names(food_intake_one_df)
# 需要注意后面百分比的,要提前/先算成g
food_intake_one_df[,i] <- (food_intake_one_df[,i]/100 )*food_intake_one_df$脂肪酸Total
# 前面已经是g的,合并后面已经是g的了
food_intake_one_df[,i] <- food_intake_one_df[,i]*food_intake_one_df$g
food_intake_one_df[naaa, i]=sum(food_intake_one_df[,i],na.rm = T)
food_intake_one_df$WAVE[naaa] <- WAVE
food_intake_one_df$hhid[naaa] <- food_intake_one_df$hhid[1]
# # 单独处理这一次ID_WAVE的
food_intake_one_df <- dplyr::slice_tail(food_intake_one_df, n = 1)
names(food_intake_one_df)
# 单独的除3天的
food_intake_one_df[1, i]=food_intake_one_df[,i] / 3
food_intake_one_all_list[[qaq]] <- food_intake_one_df
}
food_intake_one_all_df <- do.call(rbind,food_intake_one_all_list)
rownames(food_intake_one_all_df) <- NULL
names(food_intake_one_all_df)
summary(food_intake_one_all_df$脂肪Fat.g)
food_intake_one_all_df <- dplyr::select(
food_intake_one_all_df, -c( "g" , "V39" , "FOODCODE", "foodcode_2",
"编码.Code" , "食物名称.Food.name"))
food_intake_one_all_df <- readRDS("food_intake_one_all_df.rds")
summary(food_intake_one_all_df$脂肪酸Total)
food_intake_one_all_df <- dplyr::arrange(food_intake_one_all_df,IDind,WAVE)
# -----提取个人有多次的膳食数据-----
person_nWAVE <- split(food_intake_one_all_df, food_intake_one_all_df$IDind)
WAVE_count <- purrr::map_df(person_nWAVE,.f = ~table(.x$WAVE))
WAVE_count$IDind <- names(person_nWAVE)
names(WAVE_count)
WAVE_count_id <- dplyr::select(WAVE_count, IDind)
WAVE_count_sum <- dplyr::select(WAVE_count, "2004", "2006", "2009", "2011")
# # 【统计非NA的个数】
WAVE_count_sum$nWAVE <- NA
for (i in 1:nrow(WAVE_count_sum)) {
if(is.na(WAVE_count$"2004"[i])){ a_a1 =0} else{a_a1 =1}
if(is.na(WAVE_count$"2006"[i])) {a_a2 =0 }else{a_a2 =1}
if(is.na(WAVE_count$"2009"[i])) {a_a3 =0 }else{a_a3 =1}
if(is.na(WAVE_count$"2011"[i])) {a_a4 =0 }else{a_a4 =1}
WAVE_count_sum$nWAVE[i] <- sum(c(a_a1, a_a2, a_a3, a_a4),na.rm = T)
}
WAVE_count <- cbind(WAVE_count_id,WAVE_count_sum)
saveRDS(WAVE_count, "person_nWAVE.rds")
WAVE_count <- readRDS("person_nWAVE.rds")
# 保障有两次随访的
WAVE_count <- subset(WAVE_count,WAVE_count$nWAVE>1)
food_intake_one_all_df <- subset(food_intake_one_all_df,
food_intake_one_all_df$IDind %in% unique(WAVE_count$IDind)
)
food_intake_one <- food_intake_one_all_df
# -----个人最后提取的-----
# saveRDS(food_intake_one,"food_intake_one.rds")
food_intake_one <- readRDS("food_intake_one.rds")
------家庭Food Intake------
# ------家庭Food Intake------
# 【提取一份最全的】
library(haven)
library(dplyr)
nutr1 <- read_sas("nutr1_00.sas7bdat")
# V15 INITIAL AMT ON HAND (MEASURE VARIES) 最开始的重量
# V21 FINAL AMT REMAINING (MEASURE VARIES) 最后的重量
# V22 3-DAY TOTAL CONSUMED (MEASURE VARIES)
# V23 TOTAL CONSUMPTION (AMT/PERSON/DAY) # 平均每人每天的, 【没有数据】
summary(nutr1$V23)
names(nutr1)
# 家庭吃了总的 jtcd
nutr1 <- dplyr::select(nutr1, jtcd = V22, V23, "FOODCODE", "WAVE","hhid" ) %>%
filter(., WAVE>=2004)
# 检查重量异常的
table(is.na(nutr1$jtcd))
nutr1$jtcd <- ifelse( is.na(nutr1$jtcd)| nutr1$jtcd <= 0 ,
yes = 0,
no = nutr1$jtcd
)
nutr1$FOODCODE[1:10]
nutr1$FOODCODE_2 <- stringr::str_pad(
string = nutr1$FOODCODE,width = 6,side = "left",pad = "0")
FCT <- openxlsx::read.xlsx("../CFC/FCT_2002_2004_合并的脂肪酸数据-4.xlsx")
names(FCT)
FCT$FOODCODE <- gsub(pattern = "-",replacement = "",x = FCT$编码.Code)
str(FCT)
# 核对编码
unique(FCT$FOODCODE) %in% nutr1$FOODCODE
df_home <- dplyr::left_join(nutr1, FCT, by=c("FOODCODE_2"="FOODCODE"))
df_home <- tidyr::drop_na(df_home ,"编码.Code")
table(is.na(df_home$V23))
df_home$hhid_WAVE <- paste0(df_home$hhid, "_", df_home$WAVE)
ids <- dplyr::select(food_intake_one,IDind, hhid, WAVE,hhid_WAVE,IDind_WAVE )
ids$hhid_WAVE <- paste0(ids$hhid,"_",ids$WAVE)
# 先筛出来匹配结局和个人的WAVE与ID
df_home <- dplyr::filter(
df_home,
hhid_WAVE %in% unique(ids$hhid_WAVE))
length(unique(food_intake_one$hhid))
saveRDS(df_home,"df_home.rds")
# 几个人吃
nutr2 <- read_sas("nutr2_00.sas7bdat")
# V35 TOTAL # OF "PERSON-DAYS" FOR THE 3 DAYS
names(nutr2)
nutr2 <- dplyr::select(nutr2, IDind, "HHID", "WAVE",
personDays=V35,
day1_mor = V30_36)
nutr2_one_prop <- do.call(rbind, nutr2_list)
rownames(nutr2_one_prop) <- NULL
names(nutr2_one_prop)
nutr2_one_prop <- dplyr::select(nutr2_one_prop,"IDind" ,"HHID","WAVE", "hhid_WAVE" ,"jun" )
saveRDS(nutr2_one_prop,"nutr2_one_prop.rds")
# ------家庭吃的换个人------
df_home_list <- split(df_home, df_home$hhid_WAVE)
df_home_all <- list()
qaq=1
for (qaq in seq_along(df_home_list)) {
print(qaq)
df_home_list_one <- df_home_list[[qaq]]
df_home_list_one$jtcd <- df_home_list_one$jtcd /100
names(df_home_list_one)
# 需要注意后面百分比的,要提前/先算成g
for (i in 15:52) {
df_home_list_one[,i] <- df_home_list_one[,i]*df_home_list_one$脂肪酸Total /100
}
# 前面已经是g的,合并后面已经是g的了
for (i in 9:52) {
df_home_list_one[,i] <- df_home_list_one[,i]*df_home_list_one$jtcd
}
# 把同一脂肪酸加起来
naaa=nrow(df_home_list_one)+1
for (i in 9:52) {
df_home_list_one[naaa, i]=sum(df_home_list_one[,i],na.rm = T)
}
# 家庭吃总的
df_home_list_one <- dplyr::slice_tail(df_home_list_one,n = 1)
df_home_all[[qaq]] <- df_home_list_one
}
df_home_all <- do.call(rbind, df_home_all)
rownames(df_home_all) <- NULL
nutr2_one_prop <- dplyr::left_join(nutr2_one_prop, df_home_all,by = "hhid_WAVE")
names(nutr2_one_prop)
# ---------【这里再改位置】----------
for (i in 14:55) {
# 还需要再除于3天
nutr2_one_prop[,i] <- nutr2_one_prop[,i]*nutr2_one_prop$jun / 3
}
nutr2_home_person_eat <- nutr2_one_prop
nutr2_home_person_eat$fenlei <- "home"
-----个人膳食与家庭膳食合并-----
rm(list = ls())
# 个人吃的已平均3天 ,分 WAVE
food_intake_one <- readRDS("food_intake_one.rds")
food_intake_one$IDind_WAVE <- paste0(
food_intake_one$IDind, "_", food_intake_one$WAVE)
food_intake_one <- split(food_intake_one,food_intake_one$IDind_WAVE)
# 家庭吃的已平均个人3天, 分WAVE
nutr2_home_person_eat <- readRDS("nutr2_home_person_eat.rds")
names(nutr2_home_person_eat)
nutr2_home_person_eat$IDind_WAVE <- paste0(
nutr2_home_person_eat$IDind, "_", nutr2_home_person_eat$WAVE.x)
qaq= 2
person_home_all <- list()
for (qaq in seq_along(food_intake_one)) {
print(qaq)
person_1 <- food_intake_one[[qaq]]
person_1$IDind <- as.character( person_1$IDind )
#
all_1 <- dplyr::full_join(person_1,home_1)
# 合计
names(all_1)
naaa=nrow(all_1)+1
for (i in 4:47) {
# # 单独处理这一次ID_WAVE的
all_1 <- dplyr::slice_tail(all_1, n = 1)
names(all_1)
all_2 <- dplyr::select(all_1, -c(
"HHID", "WAVE.x","jun","jtcd","V23" ,"FOODCODE" , "WAVE.y", "year",
"FOODCODE_2" ,"编码.Code", "食物名称.Food.name","fenlei","A18:04",
"ID_WAVE","hhid_WAVE"
))
all_2 <- dplyr::relocate(all_2,"IDind_WAVE",.after = "WAVE" )
person_home_all[[qaq]] <- all_2
}
person_home_all_2 <- do.call(rbind, person_home_all)
rownames(person_home_all_2) <- NULL
summary(person_home_all_2$脂肪Fat.g)
# saveRDS(person_home_all_2,"person_home_all_2.rds")
# openxlsx::write.xlsx(person_home_all_2,"person_home_all_2.xlsx")
# ------合并宏量营养素-------
library(dplyr)
person_home_all_2 <- readRDS("person_home_all_2.rds")
names(person_home_all_2)
Macronutrients=haven::read_sas(
'c12diet.sas7bdat') %>%
filter(wave>=2004)
Macronutrients$IDind_WAVE <- paste0(Macronutrients$IDind,"_",Macronutrients$wave)
Macronutrients <- dplyr::select(
Macronutrients, IDind_WAVE, "d3kcal" ,
"d3carbo" , "d3fat" , "d3protn")
person_home_all_2 <- dplyr::left_join(person_home_all_2,Macronutrients,by ="IDind_WAVE" )
FFQ=person_home_all_2

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









