







在当前主流的分布式架构中,各种各样的集群技术几乎成了任何想要提升系统稳定性和处理能力的团队的必备技能。虽然各种中间件和系统都有让人看似眼花缭乱的集群实现方案,但其背后仍然逃不过一些核心的技术概念,我会结合几个我比较熟悉的中间件,简单聊一下我对集群的理解:
集群的类型
按照搭建集群的目标来划分,大致可以划分为三类集群
高可用集群
高可用性集群的主要目的是使集群的整体服务尽可能可用,在集群中任意一个节点失效的情况下,该节点上的所有任务会自动转移到其他正常的节点上。此过程并不影响整个集群的运行,能够有效的避免单点故障。高可用集群要求节点间可以进行任务和状态的迁移。我们通常所说的双机热备,也就是某种意义上的高可用集群。
负载均衡集群
负载均衡集群的主要是通过一个或多个负载均衡器,基于一定的算法将客户端集中的访问请求负载压力尽可能平均地分摊在集群中的各个节点进行处理,实现访问请求在各节点之间动态分配,以提升集群整体的吞吐量和性能,避免单个节点的网络,硬件资源等成为性能瓶颈,实现服务的横向扩展。这个例子就很多了,比如通过nginx反向代理多个后端的web服务器实例,实现多实例间的负载均衡。
高性能集群
主要用于大型任务的并行计算,将一个复杂问题拆分为多个可以并行执行的任务在多个节点同时进行计算,主要用于大数据领域,比如hadoop的mapreduce,flink,spark等等。
常用中间件的集群实现
Kafka集群
kafka的集群基于副本机制来实现了高可用,然后通过多broker,多分区来实现消息生产和消费的负载均衡,整个集群的架构图如下:
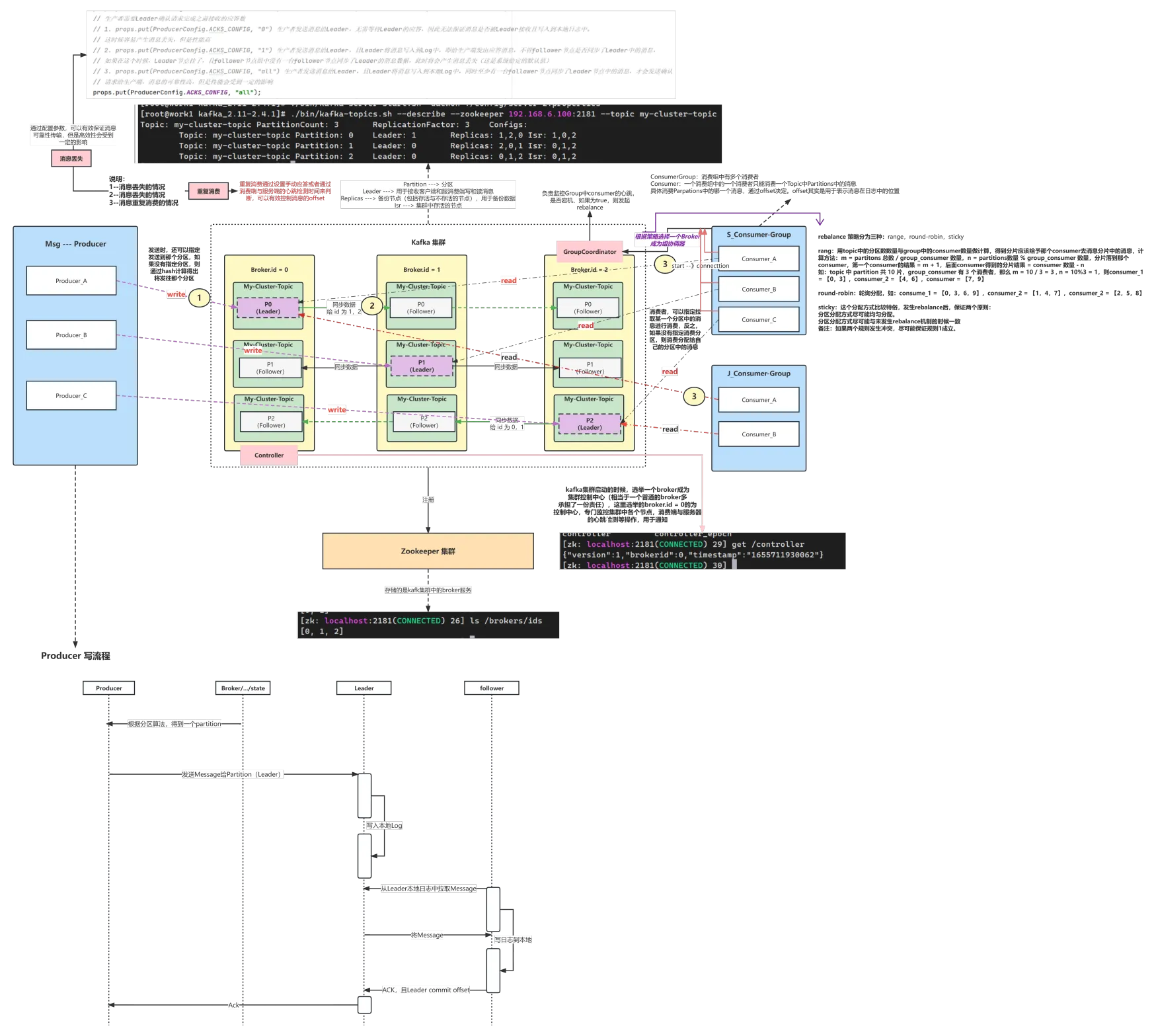
| 核心概念 | 作用 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Partition | 分区,物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的,一个分区可以简单的看作一个日志文件 |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 消费者组,每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息Partition |
Clickhouse集群
clickhouse集群有两个重要的概念:分片(shard)和 副本(replica),分片与分片间存储了不同的数据,而副本与副本之间数据是一致的(最终一致),一个分片可以有多个副本。从这里就可以看出它是通过分片实现负载均衡,而对分片创建副本来实现分片的高可用。一个典型的clickhouse集群主要由六个节点组成,分别为3个分片以及每个分片一个副本,:

这六个节点构成集群的配置如下:
<remote_servers>
<!-- User-specified clusters -->
<replicated>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chi-clickhouse-replicated-0-0</host>
<port>9000</port>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









