







文章目录
前言
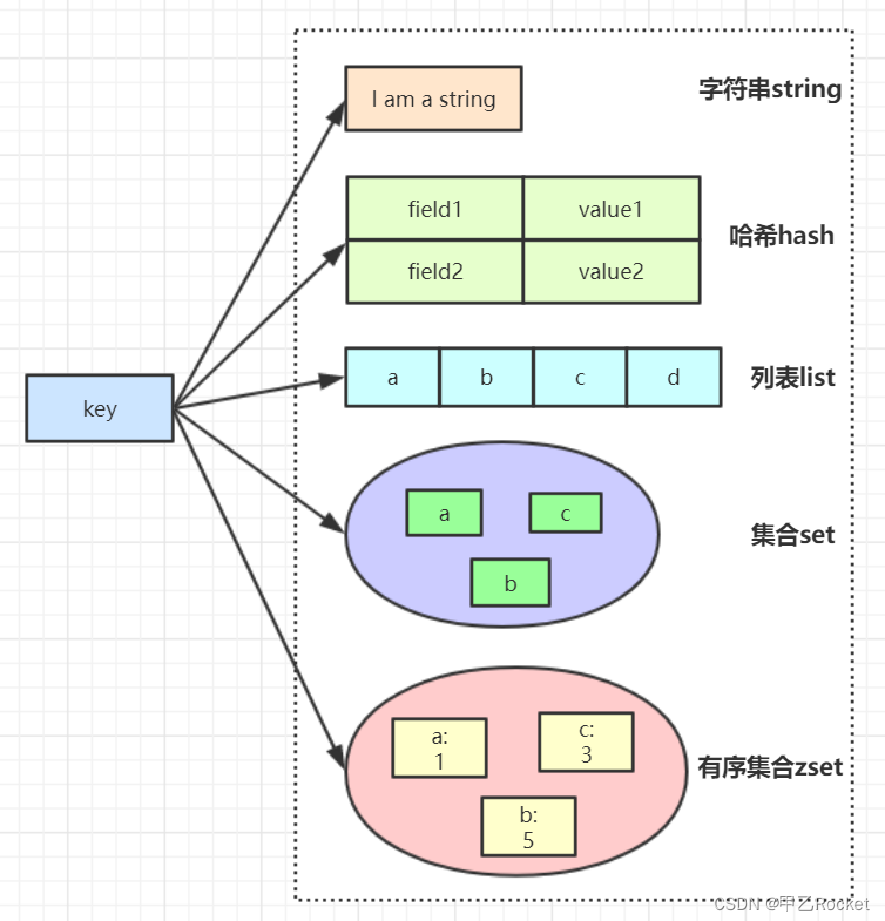
Redis有5个基本数据结构,string、list、hash、set和zset。它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这5个数据结构都吃透了,你就掌握了Redis应用知识的一半了。
我们要好好的熟悉数据结构的的使用,将这些融入到我们日常工作开发中。能解决我们的很多问题
安装
Linux 环境下安装
参照:https://www.cnblogs.com/hunanzp/p/12304622.html
踩的小坑
#启动
./bin/redis-server& ./redis.conf
#进入redis客户端
在redis目录中 src/redis‐cli
提示:以下是本篇文章正文内容,下面案例可供参考
一、String
string是我们在日常开发中使用最多的。
首先我们从string谈起。string表示的是一个可变的字节数组,我们初始化字符串的内容、可以拿到字符串的长度,可以获取string的子串,可以覆盖string的子串内容,可以追加子串。注:计数器的功能很容易被大家忽略
1.常用命令和操作
-
字符串常用操作
SET key value //存入字符串键值对
MSET key value [key value …] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key …] //批量获取字符串键值
DEL key [key …] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒) -
原子加减
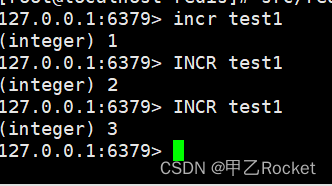
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
对原子加减进来客户端相应的操作
- 1、原子加1
- 2、原子加指定的数值 incrby key +值
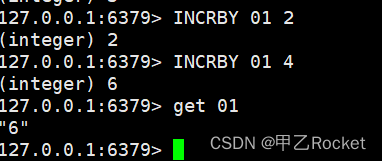
- 3、两个减同理
2.应用场景
- 单值缓存(场景广泛)
set进去你任何想要的值即可 - 对象缓存(建议使用hash的方式【键值对的方式:键-属性,值-属性值】)
避免大key的出现【大key就是,get key的时候,值太大的情况尽量避免】
set key +json字符串 - 分布式锁【底层原理,后序深入学习】
setnx
3.对应业务场景举例
- 1 缓存各种业务数据,用于下一次使用
set key ==》get - 2 一些计数场景,如一条信息的已读,已阅场景
incr key=msg:msgId (+1)
二、Hash
哈希等价于Java语言的HashMap,在实现结构上它使用二维结构,第一维是数组,第二维是链表,hash的内容key和value存放在链表中,数组里存放的是链表的头指针。通过key查找元素时,先计算key的hashcode,然后用hashcode对数组的长度进行取模定位到链表的表头,再对链表进行遍历获取到相应的value值,链表的作用就是用来将产生了「hash碰撞」的元素串起来。Java语言开发者会感到非常熟悉,因为这样的结构和HashMap是没有区别的。哈希的第一维数组的长度也是2^n。
1.常用命令和操作
- Hash常用操作
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value …] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field …] //批量获取哈希表key中多个field键值
HDEL key field [field …] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
- 对语句进行简单的操作(红框为正确操作)
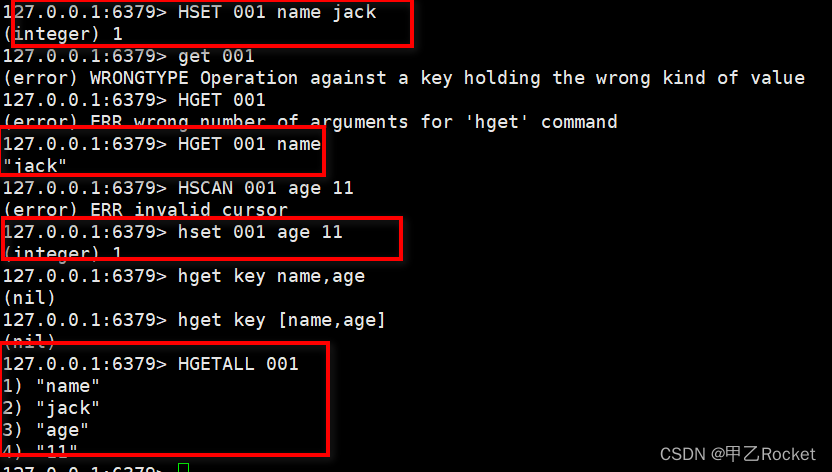
2.应用场景
- 1、对象存储
k是属性名,v是属性值【仅适用于属性少的情况,避免大key的情况发生】 - 2、包含key相约关系的场景,避免对数据库的频繁操作
3.对应业务场景举例
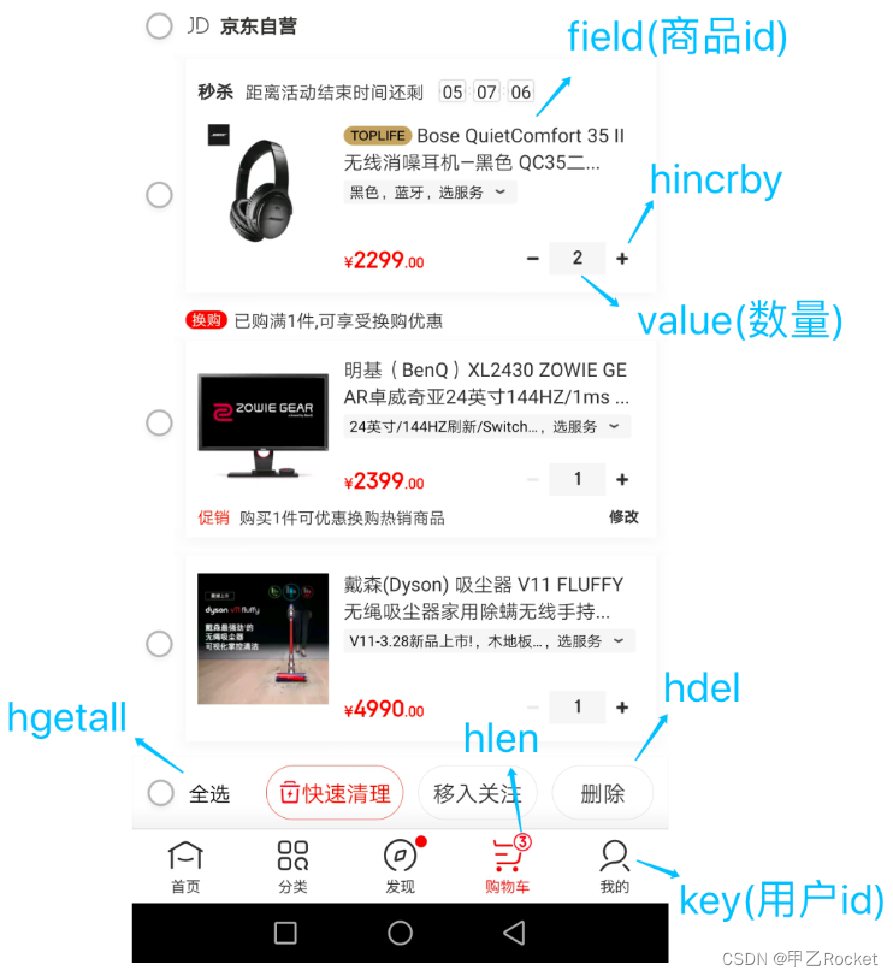
- 1、购物车(因为购物车的加减操作是比较可能是比较频繁的,可考虑引入hash缓存)
总的结构如下:
a:缓存的key是用户id
b:商品id为field
c:商品数量为value
- 2、有时候权限也可以放到缓存中,来支持某些业务
a:key=》 用户id
b:fildId=》权限id
c:value=》是否有权限(0/1)
当权限变动一定要刷缓存
优缺点
-
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间 -
缺点
1)过期功能不能使用在field上,只能用在key上
2)Redis集群架构下不适合大规模使用
三、List
Redis将列表数据结构命名为list而不是array,是因为列表的存储结构用的是链表而不是数组,而且链表还是双向链表。因为它是链表,所以随机定位性能较弱,首尾插入删除性能较优。如果list的列表长度很长,使用时我们一定要关注链表相关操作的时间复杂度。
1.常用命令和操作
里面有一些左插入和右插入的操作,这些操作完全可以类比我们数据结构中的栈和队列相关的操作,也可以把栈和队列相关的问题移植到我们对应的业务架构上使用
LPUSH key value [value …] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value …] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key …] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key …] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
-
常用数据结构
Stack(栈) = LPUSH + LPOP
Queue(队列)= LPUSH + RPOP
Blocking MQ(阻塞队列)= LPUSH + BRPOP -
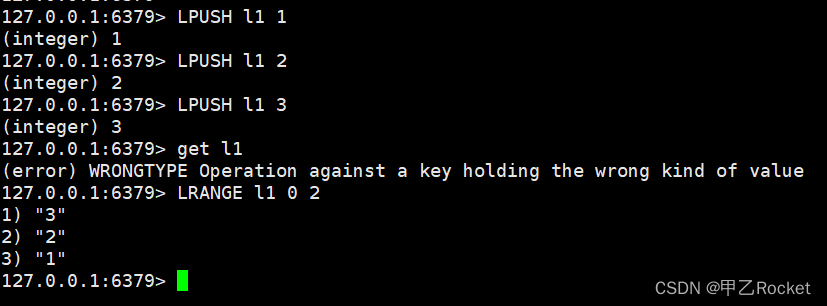
简单操作
从左边插入,下标位置越后插入的在前面。RPUSH 反之
2.应用场景
- 1、对与列表化场景;如商品列表,文章列表等
- 2、消息流的场景
3.对应的业务场景举例
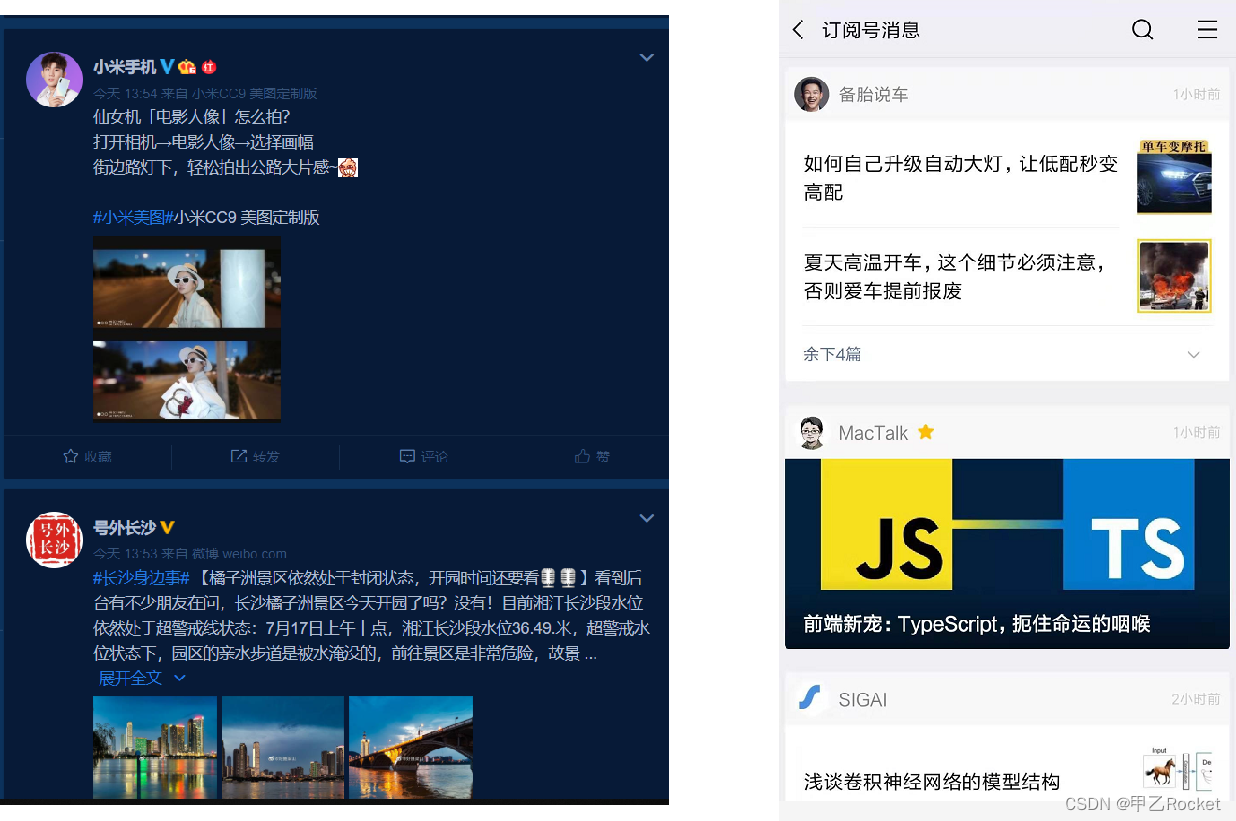
- 1、微博和公众这样的消息流
比如:A用户,订阅了1,2,3,4个博主
那么当1,2,3,4发博文的时候,我们可以按照先后的顺序,数据的生产者可以通过Lpush命令从左边插入数据
- 2 博客文章列表
文章列表或者数据分页展示的应用。比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用redis的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。首页这些我们可以定时更新等
四、Set
java程序员都知道HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
1.常用的命令和操作
Set常用操作
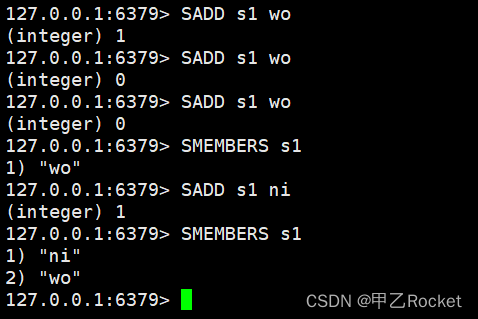
SADD key member [member …] //往集合key中存入元素,元素存在则忽略,
若key不存在则新建
SREM key member [member …] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
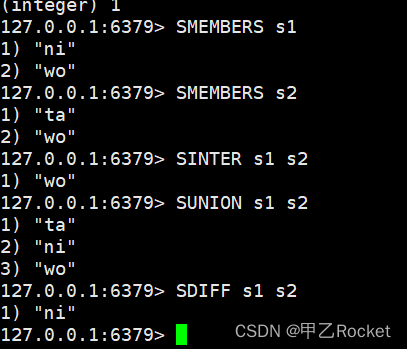
Set运算操作容易被忽略的交并补
SINTER key [key …] //交集运算
SINTERSTORE destination key [key …] //将交集结果存入新集合destination中
SUNION key [key …] //并集运算
SUNIONSTORE destination key [key …] //将并集结果存入新集合destination中
SDIFF key [key …] //差集运算
SDIFFSTORE destination key [key …] //将差集结果存入新集合destination中
- 简单操作set
可以看到和java中的set是一样的,也是去重的
运算操作
2.应用场景
- 1、最正常的操作就是香去重,保证唯一性的场景
- 2、有集合运行的也可以使用(注意这里是去重的)
3.对应的业务场景举例
- 1 点赞场景(点赞的用户是唯一的,并要可以取消点赞)
微信微博点赞,收藏,标签
- 点赞
SADD like:{消息ID} {用户ID} - 取消点赞
SREM like:{消息ID} {用户ID} - 检查用户是否点过赞
SISMEMBER like:{消息ID} {用户ID} - 获取点赞的用户列表
SMEMBERS like:{消息ID} - 获取点赞用户数
SCARD like:{消息ID}
- 2、标签:比如我们博客网站常常使用到的兴趣标签,把一个个有着相同爱好,关注类似内容的用户利用一个标签把他们进行归并。【增强用户之间的关联,为我们的大数据做铺垫】
=》
以商品标签筛选为例子
安卓set=》一堆手机集合
8gset=》一堆手机集合
我现在既8g又安卓,交集即可

- 3、共同好友功能,共同喜好,或者可以引申到二度好友之类的扩展应用。【增强用户之间的关联,为我们的大数据做铺垫】
每一个用户维护一个set集合,然后通过集合运算得到结果
共同=》交集
可能认识的人=》差集
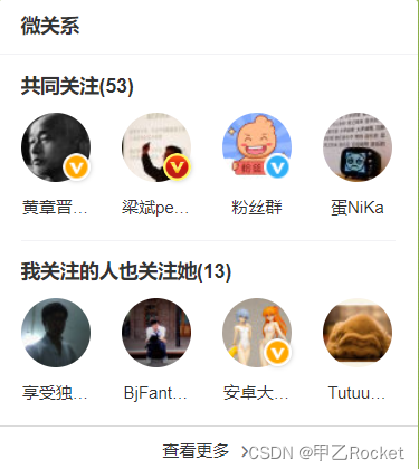
- 4、统计网站的独立IP。利用set集合当中元素不唯一性,可以快速实时统计访问网站的独立IP。
五、Zset
1.常用的命令的操作
ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
Zset集合操作
ZUNIONSTORE destkey numkeys key [key …] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
- 简单操作(解释就是:将a在key为key:001的集合中+1)
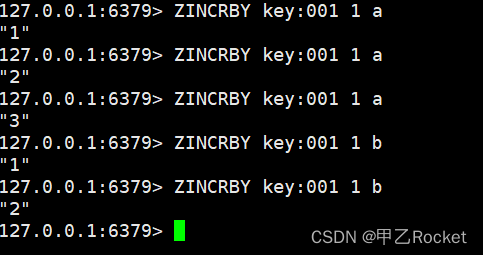
2、应用场景
- 1、延时队列
zset 会按 score 进行排序,如果 score 代表想要执行时间的时间戳。在某个时间将它插入 zset 集合中,它变会按照时间戳大小进行排序,也就是对执行时间前后进行排序。
- 2、排行榜
经常浏览技术社区的话,应该对 “1小时最热门” 这类榜单不陌生。如何实现呢?如果记录在数据库中,不太容易对实时统计数据做区分。我们以当前小时的时间戳作为 zset 的 key,把贴子ID 作为 member ,点击数评论数等作为 score,当 score 发生变化时更新 score。利用 ZREVRANGE 或者 ZRANGE 查到对应数量的记录。
- 3、 限流
滑动窗口是限流常见的一种策略。如果我们把一个用户的 ID 作为 key 来定义一个 zset ,member 或者 score 可以都为访问时的时间戳。我们只需统计某个 key 下在指定时间戳区间内的个数,就能得到这个用户滑动窗口内访问频次,与最大通过次数比较,来决定是否允许通过。
3.对应的业务场景举例
Zset集合操作实现排行榜
1)点击新闻
ZINCRBY hotNews:20190819 1 守护香港
2)展示当日排行前十
ZREVRANGE hotNews:20190819 0 9 WITHSCORES
3)七日搜索榜单计算
ZUNIONSTORE hotNews:20190813-20190819 7
hotNews:20190813 hotNews:20190814… hotNews:20190819
4)展示七日排行前十
ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
总结
这一章的重点是了解一些基础的数据结构,然后尽量在工作中进行多元化的使用,不要搞来搞去就是string。其实我们可以使用更多的数据结构来帮我们实现复杂的业务。
后面的话,我们其实还有一些更加高阶的一些数据结构,帮我们完成一些特定的场景
如官方文档所示,还有很多
















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









