







[论文阅读笔记]2019_SIGIR_Neural Graph Collaborative Filtering
论文下载地址: https://doi.org/10.1145/3331184.3331267
发表期刊:SIGIR
Publish time: 2019
作者及单位:
- Xiang Wang National University of Singapore xiangwang@u.nus.edu
- Xiangnan He∗ University of Science and Technology of China xiangnanhe@gmail.com
- Meng Wang Hefei University of Technology eric.mengwang@gmail.com
- Fuli Feng National University of Singapore fulifeng93@gmail.com
- Tat-Seng Chua National University of Singapore dcscts@nus.edu.sg
数据集: 正文中的介绍
- Gowalla
- Yelp2018
- Amazon-Book
代码:
其他:
其他人写的文章
- b站视频–推荐系统论文代码讲解】Neural Graph Collaborative Filtering
- 论文】Neural Graph Collaborative Filtering 论文解读
- 论文笔记:Neural Graph Collaborative Filtering
- 神经图协同过滤(Neural Graph Collaborative Filtering)
- 【论文笔记】Neural Graph Collaborative Filtering — SIGIR2019
简要概括创新点: (1)协同信号collaborative signal就是 e i ⊙ e u e_i \odot e_u ei⊙eu
(2)然后多层(3层),就是multiple embedding propagation layers,得到 high-order connectivity relations
- We highlight the critical importance of explicitly exploiting the collaborative signal in the embedding function of model-based CF methods. (我们强调了在基于模型的CF方法的嵌入功能中明确利用协同信号的关键重要性。)
- We propose NGCF, a new recommendation framework based on graph neural network, which explicitly encodes the collaborative signal in the form of high-order connectivities by performing embedding propagation. (我们提出了一种新的基于图神经网络的推荐框架NGCF,该框架通过嵌入传播将协同信号以高阶连通性的形式显式编码。)
- There are three components in the framework: (该框架包括三个部分)
- (1) an embedding layer that offers and initialization of user embeddings and item embeddings; (嵌入层,提供用户嵌入和项目嵌入的初始化;)
- (2) multiple embedding propagation layers that refine the embeddings by injecting high-order connectivity relations; and (多个嵌入传播层,通过 注入高阶连通关系 来细化嵌入;和)
- (3) the prediction layer that aggregates the refined embeddings from different propagation layers and outputs the affinity score of a user-item pair. (预测层聚合来自不同传播层的细化嵌入,并输出用户项对的亲和力分数。)
- collaborative signal如何体现的
- Distinct from conventional graph convolution networks [4, 18, 29,41] that consider the contribution of e i e_i ei only, here we additionally encode the interaction between e i e_i ei and e u e_u eu into the message being passed via e i ⊙ e u e_i \odot e_u ei⊙eu, (不同于传统的图卷积网络[4, 18,29,41],只考虑 e i e_i ei的贡献,这里,我们另外编码 e i e_i ei 和 e u e_u eu之间的交互作用到通过 e i ⊙ e u e_i \odot e_u ei⊙eu传递的消息中,)
- where ⊙ \odot ⊙ denotes the element-wise product. (表示元素的乘积) 具体实现的关键,什么是协同信号
- 优化策略
- mini-batch Adam
- node dropout
- message dropout
- 数据预筛选 retaining users and items with at least ten interactions. 即保留至少有10个交互的用户和项目。
- For each observed user-item interaction, we treat it as a positive instance, (对于每个观察到的用户项目交互,我们将其视为一个正实例)
- and then conduct the negative sampling strategy to pair it with one negative item that the user did not consume before. (然后执行 负采样策略,将其与用户以前没有消费过的一个负项目配对。)
ABSTRACT
-
(1) Learning vector representations (aka. embeddings) of users and items lies at the core of modern recommender systems. Ranging from early matrix factorization to recently emerged deep learning based methods, existing efforts typically obtain a user’s (or an item’s) embedding by mapping from pre-existing features that describe the user (or the item), such as ID and attributes . (用户和项目的学习向量表示(又名嵌入)是现代推荐系统的核心。从早期的矩阵分解到最近出现的基于深度学习的方法,现有的工作通常 通过映射描述用户(或项目)的现有特征(如ID和属性)来获得用户(或项目)的嵌入。)
- We argue that an inherent drawback of such methods is that, the collaborative signal, which is latent in user-item interactions, is not encoded in the embedding process. As such, the resultant embeddings may not be sufficient to capture the collaborative filtering effect. (我们认为,这种方法的一个固有缺点是,用户项目交互中 潜在的协同信号 在嵌入过程中没有编码。因此,生成的嵌入可能不足以捕获协同过滤效果。)
-
(2) In this work, we propose to integrate the user-item interactions — more specifically the bipartite graph structure — into the embedding process. (在这项工作中,我们建议将用户项交互——更具体地说是二部图结构——集成到嵌入过程中。)
- We develop a new recommendation framework Neural Graph Collaborative Filtering (NGCF), (我们开发了一个新的推荐框架神经图协同过滤(NGCF),)
- which exploits the user-item graph structure by propagating embeddings on it. (它通过传播嵌入来利用用户项图结构。)
- This leads to the expressive modeling of high-order connectivity in user-item graph, effectively injecting the collaborative signal into the embedding process in an explicit manner. (这导致了用户项图中高阶连通性的表达建模,有效地将协同信号以显式方式注入到嵌入过程中。)
-
We conduct extensive experiments on three public benchmarks, demonstrating significant improvements over several state-of-the-art models like HOP-Rec [39] and Collaborative Memory Network [5]. (我们在三个公共基准上进行了广泛的实验,与HOP Rec[39]和Collaborative Memory Network[5]等几种最先进的模型相比,取得了显著的改进。)
-
(3) Further analysis verifies the importance of embedding propagation for learning better user and item representations, justifying the rationality and effectiveness of NGCF. (进一步的分析验证了嵌入传播对于学习更好的用户和项目表示的重要性,证明了NGCF的合理性和有效性。)
-
(4) Codes are available at https://github.com/ xiangwang1223/neural_graph_collaborative_filtering.
CCS CONCEPTS
• Information systems → Recommender systems.
KEYWORDS
Collaborative Filtering, Recommendation, High-order Connectivity, Embedding Propagation, Graph Neural Network
1 INTRODUCTION
-
(1) Personalized recommendation is ubiquitous, having been applied to many online services such as E-commerce, advertising, and social media. At its core is estimating how likely a user will adopt an item based on the historical interactions like purchases and clicks. (个性化推荐无处不在,已经应用于电子商务、广告和社交媒体等许多在线服务。其核心是根据购买和点击等历史互动来估计用户采纳某个商品的可能性。)
- Collaborative filtering (CF) addresses it by assuming that behaviorally similar users would exhibit similar preference on items. To implement the assumption, a common paradigm is to parameterize users and items for reconstructing historical interactions, and predict user preference based on the parameters [1, 14]. (协同过滤(CF)通过 假设行为相似的用户会对项目表现出相似的偏好来解决这个问题。为了实现这一假设,一个常见的范例是参数化用户和项目以重建历史交互,并根据参数预测用户偏好[1,14]。)
-
(2) Generally speaking, there are two key components in learnable CF models — (一般来说,可学习CF模型有两个关键组件)
- (1) embedding, which transforms users and items to vectorized representations, and (嵌入,将用户和项目转换为矢量化表示,以及)
- (2) interaction modeling, which reconstructs historical interactions based on the embeddings. (交互建模,基于嵌入重建历史交互。)
- For example, matrix factorization (MF) directly embeds user/item ID as an vector and models user-item interaction with inner product [20]; (例如,矩阵分解(MF)直接嵌入用户/项目ID作为向量,并建模用户项目与内积的交互[20];)
- collaborative deep learning extends the MF embedding function by integrating the deep representations learned from rich side information of items [30]; (协同式深度学习通过整合从项目丰富的侧面信息中学习到的深度表征,扩展了MF嵌入功能[30];)
- neural collaborative filtering models replace the MF interaction function of inner product with nonlinear neural networks [14]; (神经协同过滤模型用非线性神经网络代替内积的MF交互函数[14];)
- and translation-based CF models instead use Euclidean distance metric as the interaction function [28], among others. (基于翻译的CF模型使用欧几里德距离度量作为交互函数[28],等等。)
-
(3) Despite their effectiveness, we argue that these methods are not sufficient to yield satisfactory embeddings for CF. (尽管有效,我们认为这些方法不足以产生满意的CF嵌入。)
- The key reason is that the embedding function lacks an explicit encoding of the crucial collaborative signal, which is latent in user-item interactions to reveal the behavioral similarity between users (or items). (关键原因是嵌入函数缺少对 关键协同信号 的 显式编码,这一信号 隐藏 在用户-项目交互中,以揭示用户(或项目)之间的行为相似性。)
- To be more specific, most existing methods build the embedding function with the descriptive features only (e.g., ID and attributes), without considering the user-item interactions — which are only used to define the objective function for model training [26, 28]. (更具体地说,大多数现有方法只使用描述性特征(例如ID和属性)构建嵌入函数,而不考虑用户项交互——这些交互仅用于定义模型训练的目标函数[26,28]。)
- As a result, when the embeddings are insufficient in capturing CF, the methods have to rely on the interaction function to make up for the deficiency of suboptimal embeddings</font> [14]. (因此,当嵌入不足以捕获CF时,这些方法必须依赖 交互函数 来弥补 次优嵌入 的不足[14]。)
-
(4) While intuitively useful to integrate user-item interactions into the embedding function, it is non-trivial to do it well. (虽然直观上可以将用户项交互集成到嵌入函数中,但做好这项工作并非易事。)
- In particular, the scale of interactions can easily reach millions or even larger in real applications, making it difficult to distill the desired collaborative signal. (特别是,在实际应用中,交互的规模很容易达到数百万甚至更大,因此很难提取所需的协同信号。)
- In this work, we tackle the challenge by exploiting the high-order connectivity from user-item interactions, a natural way that encodes collaborative signal in the interaction graph structure. (在这项工作中,我们通过利用用户项交互的高阶连接性 来应对这一挑战,这是一种在交互图结构中编码 协同信号 的自然方式。)

Running Example. Figure 1 illustrates the concept of high-order connectivity. The user of interest for recommendation is u1, labeled with the double circle in the left subfigure of user-item interaction graph. The right subfigure shows the tree structure that is expanded from u1. (图1说明了高阶连接性的概念。推荐感兴趣的用户是u1,在用户项交互图的左侧子图中用双圈标记。右侧子图显示了从u1展开的树结构)
- The high-order connectivity denotes the path that reaches u1 from any node with the path length l larger than 1. (高阶连接性表示从路径长度l大于1的任何节点到达u1的路径。)
- Such high-order connectivity contains rich semantics that carry collaborative signal. (这种高阶连接性包含丰富的语义,承载着协同信号)
- For example, the path u1← i2← u2 indicates the behavior similarity between u1 and u2, as both users have interacted with i2; (例如,路径u1← i2← u2表示u1和u2之间的行为相似性,因为两个用户都与i2进行过交互)
- the longer path u1← i2← u2← i4 suggests that u1 is likely to adopt i4, since her similar user u2 has consumed i4 before. (更长的路径u1← i2← u2← i4表明u1可能会采用i4,因为她相似的用户u2以前也使用过i4。)
- Moreover, from the holistic view of l = 3, item i4 is more likely to be of interest to u1 than item i5, since there are two paths connecting <i4,u1>, while only one path connects <i5,u1>. (此外,从l=3的整体观点来看,项目i4比项目i5更有可能引起u1的兴趣,因为有两条路径连接<i4,u1>,而只有一条路径连接<i5,u1>。</i5,u1></i4,u1>)
Present Work. We propose to model the high-order connectivity information in the embedding function. (我们建议在嵌入函数中对高阶连通性信息进行建模。)
-
Instead of expanding the interaction graph as a tree which is complex to implement, we design a neural network method to propagate embeddings recursively on the graph. (我们设计了一种神经网络方法来递归地在图上传播嵌入,而不是将交互图扩展为一棵复杂的树。)
-
This is inspired by the recent developments of graph neural networks [8, 31, 37], which can be seen as constructing information flows in the embedding space. (这是受最近发展的图神经网络[8,31,37]的启发,它可以被视为在 嵌入空间 中构造 信息流 。)
-
Specifically, we devise an embedding propagation layer, which refines a user’s (or an item’s) embedding by aggregating the embeddings of the interacted items (or users). (具体来说,我们设计了一个 嵌入传播层 ,通过聚合交互项(或用户)的嵌入来细化用户(或项目)的嵌入。)
-
By stacking multiple embedding propagation layers, we can enforce the embeddings to capture the collaborative signal in high-order connectivities. (通过叠加多个嵌入传播层,我们可以强制嵌入 以高阶连通性 捕获 协同信号。)
-
Taking Figure 1 as an example, stacking two layers captures the behavior similarity of u1← i2← u2, stacking three layers captures the potential recommendations of u1← i2← u2← i4, and the strength of the information flow (which is estimated by the trainable weights between layers) determines the recommendation priority of i4and i5. (以图1为例,将两个层叠加在一起可以捕捉到u1的行为相似性← i2← u2,堆叠三层,捕捉u1的潜在建议← i2← u2← i4和信息流的强度(由层之间的可训练权重估计)决定i4和i5的推荐优先级。)
-
We conduct extensive experiments on three public benchmarks to verify the rationality and effectiveness of our Neural Graph Collaborative Filtering (NGCF) method. (我们在三个公共基准上进行了大量实验,以验证我们的神经图协同过滤(NGCF)方法的合理性和有效性。)
-
(5) Lastly, it is worth mentioning that although the high-order connectivity information has been considered in a very recent method named HOP-Rec [39], it is only exploited to enrich the training data. (最后,值得一提的是,尽管最近一种名为HOP Rec[39]的方法考虑了高阶连接性信息,但它仅用于丰富训练数据。)
-
Specifically, the prediction model of HOP-Rec remains to be MF, while it is trained by optimizing a loss that is augmented with high-order connectivities. (具体地说,HOP-Rec的预测模型仍然是MF,而它是通过优化一个由高阶连通性增强的损失来训练的。)
-
Distinct from HOP-Rec, we contribute a new technique to integrate high-order connectivities into the prediction model, which empirically yields better embeddings than HOP-Rec for CF. (与HOP-Rec不同的是,我们提出了一种新技术, 将高阶连通性集成到预测模型中 ,从经验上看,该技术比HOP-Rec对CF的嵌入效果更好。)
-
(6) To summarize, this work makes the following main contributions: (总而言之,这项工作的主要贡献如下:)
- We highlight the critical importance of explicitly exploiting the collaborative signal in the embedding function of model-based CF methods. (我们强调了在基于模型的CF方法的嵌入功能中明确利用协同信号的关键重要性。)
- We propose NGCF, a new recommendation framework based on graph neural network, which explicitly encodes the collaborative signal in the form of high-order connectivities by performing embedding propagation. (我们提出了一种新的基于图神经网络的推荐框架NGCF,该框架通过嵌入传播将协同信号以高阶连通性的形式显式编码。)
-
We conduct empirical studies on three million-size datasets. Extensive results demonstrate the state-of-the-art performance of
NGCF and its effectiveness in improving the embedding quality with neural embedding propagation. (我们对300万个数据集进行了实证研究。大量的实验结果证明了NGCF的最新性能及其通过神经嵌入传播提高嵌入质量的有效性。)

(图2:NGCF模型架构的图示(箭头线表示信息流)。user u1(左)和item i4(右)的表示通过多个嵌入传播层进行细化,这些层的输出被连接起来以进行最终预测。)
2 METHODOLOGY
- (1) We now present the proposed NGCF model, the architecture of which is illustrated in Figure 2. (我们现在展示了拟议的NGCF模型,其架构如图2所示。)
- There are three components in the framework: (该框架包括三个部分)
- (1) an embedding layer that offers and initialization of user embeddings and item embeddings; (嵌入层,提供用户嵌入和项目嵌入的初始化;)
- (2) multiple embedding propagation layers that refine the embeddings by injecting high-order connectivity relations; and (多个嵌入传播层,通过 注入高阶连通关系 来细化嵌入;和)
- (3) the prediction layer that aggregates the refined embeddings from different propagation layers and outputs the affinity score of a user-item pair. (预测层聚合来自不同传播层的细化嵌入,并输出用户项对的亲和力分数。)
- Finally, we discuss the time complexity of NGCF and the connections with existing methods. (最后,我们讨论了NGCF的时间复杂性以及与现有方法的联系。)
2.1 Embedding Layer ( 嵌入层)
- (1) Following mainstream recommender models [1,14,26], we describe a user u (an item i) with an embedding vector
e
u
∈
R
d
(
e
i
∈
R
d
)
e_u \in R^d(e_i \in R^d)
eu∈Rd(ei∈Rd), (遵循 主流推荐模型 [1,14,26],我们描述了一个用户u(一个项目i),其嵌入向量为
e
u
∈
R
d
(
e
i
∈
R
d
)
e_u \in R^d(e_i \in R^d)
eu∈Rd(ei∈Rd),)
- where d denotes the embedding size. (其中d表示嵌入大小。)
- (2) This can be seen as building a parameter matrix as an embedding look-up table: (这可以被看作是构建一个 参数矩阵 作为一个 嵌入查找表 )

- (3) It is worth noting that this embedding table serves as an initial state for user embeddings and item embeddings, to be optimized in an end-to-end fashion. (值得注意的是,此 嵌入表 作为用户嵌入和项嵌入的 初始状态 ,以端到端的方式进行优化。)
- In traditional recommender models like MF and neural collaborative filtering [14], these ID embeddings are directly fed into an interaction layer (or operator) to achieve the prediction score. (在传统的推荐模型(如MF和神经协同过滤[14])中,这些ID嵌入直接输入到交互层(或操作符)中,以获得预测分数。)
- In contrast, in our NGCF framework, we refine the embeddings by propagating them on the user-item interaction graph. This leads to more effective embeddings for recommendation, since the embedding refinement step explicitly injects collaborative signal into embeddings. (相比之下,在我们的NGCF框架中,我们通过在 用户项目交互图 上传播来细化嵌入。这将导致更有效的推荐嵌入,因为嵌入优化步骤将 协同信号 显式地 注入到 嵌入 中。)
2.2 Embedding Propagation Layers (Embedding传播层)
- Next we build upon the message-passing architecture of GNNs [8, 37] in order to capture CF signal along the graph structure and refine the embeddings of users and items. (接下来,我们基于 GNNs的消息传递体系结构[8,37],沿着图形结构捕获 CF信号 ,并优化用户和项目的嵌入。)
- We first illustrate the design of one-layer propagation, and then generalize it to multiple successive layers. (我们首先说明了单层传播的设计,然后将其推广到多个连续层。)
2.2.1 First-order Propagation.
- (1) Intuitively, the interacted items provide direct evidence on a user’s preference [16, 38]; (交互项目提供了用户偏好的直接证据[16,38];)
- analogously, the users that consume an item can be treated as the item’s features and used to measure the collaborative similarity of two items. (类似地,消费某个项目的用户可以被视为该项目的特征,并用于衡量两个项目的协同相似性。)
- We build upon this basis to perform embedding propagation between the connected users and items, formulating the process with two major operations: (在此基础上,我们在连接的用户和项目之间执行嵌入传播,并通过两个主要操作制定流程:)
- message construction (消息构造)
- and message aggregation (消息聚合)
2.2.1.1 Message Construction.
-
(1) For a connected user-item pair ( u , i ) (u,i) (u,i), we define the message from i i i to u u u as: (对于连接的用户项对 ( u , i ) (u,i) (u,i),我们将从 i i i到 u u u的消息定义为:)

- where m u ← i m_{u←i} mu←i is the message embedding (i.e., the information to be propagated). (是消息嵌入(即要传播的信息)。)
- f (·) is the message encoding function, which takes embeddings e i e_i ei and e u e_u eu as input, and uses the coefficient p u i p_{ui} pui to control the decay factor on each propagation on edge (u,i). (f (·)是 消息编码函数 ,它以嵌入 e i e_i ei和 e u e_u eu作为输入,并使用系数 p u i p_{ui} pui来控制边(u,i)上每次传播的 衰减因子。)
-
(2) In this work, we implement f (·) as: (在这项工作中,我们将f(·)实现为:)

- where W 1 , W 2 ∈ R d ′ × d W_1,W_2 \in R^{d^′ \times d} W1,W2∈Rd′×d are the trainable weight matrices to distill useful information for propagation, (是可训练的权重矩阵,用于提取传播的有用信息,)
- and d ′ d^′ d′ is the transformation size. (是转换大小。)
-
(3) Distinct from conventional graph convolution networks [4, 18, 29,41] that consider the contribution of e i e_i ei only, here we additionally encode the interaction between e i e_i ei and e u e_u eu into the message being passed via e i ⊙ e u e_i \odot e_u ei⊙eu, (不同于传统的图卷积网络[4, 18,29,41],只考虑 e i e_i ei的贡献,这里,我们另外编码 e i e_i ei 和 e u e_u eu之间的交互作用到通过 e i ⊙ e u e_i \odot e_u ei⊙eu传递的消息中,)
- where ⊙ \odot ⊙ denotes the element-wise product. (表示元素的乘积)
-
This makes the message dependent on the affinity between e i e_i ei and e u e_u eu, e.g., passing more messages from the similar items. (这使得消息依赖于 e i e_i ei和 e u e_u eu之间的亲和关系,例如,从类似项目传递更多消息 。)
-
This not only increases the model representation ability, but also boosts the performance for recommendation (evidences in our experiments Section 4.4.2). (这不仅提高了模型表示能力,还提高了推荐性能(我们的实验第4.4.2节中有证据)。)
-
(4) Following the graph convolutional network [18], we set p u i p_{ui} pui as the graph Laplacian norm 1 / ∣ N u ∣ ∣ N i ∣ 1/ \sqrt{|N_u||N_i|} 1/∣Nu∣∣Ni∣, (按照图卷积网络[18],我们设置 p u i p_{ui} pui作为 图的拉普拉斯范数 )
- where N u N_u Nu and N i N_i Ni denote the first-hop neighbors of user u and item i. (其中 N u N_u Nu和 N i N_i Ni表示用户u和项目i的第一跳邻居。)
-
From the viewpoint of representation learning, p u i p_{ui} pui reflects how much the historical item contributes the user preference. (从表征学习的角度来看, p u i p_{ui} pui反映历史项目对用户偏好的贡献程度。)
-
From the viewpoint of message passing, p u i p_{ui} pui can be interpreted as a discount factor, considering the messages being propagated should decay with the path length. (从消息传递的角度来看, p u i p_{ui} pui可以解释为折扣因子,考虑到 正在传播的消息应该随路径长度衰减。)
2.2.1.2 Message Aggregation. (消息聚合)
- (1) In this stage, we aggregate the messages propagated from u’s neighborhood to refine u’s representation. Specifically, we define the aggregation function as: (在这个阶段,我们聚集从u的邻域传播的消息,以改进u的表示。具体而言,我们将聚合函数定义为:)

- where e u ( 1 ) e^{(1)}_u eu(1) denotes the representation of user u obtained after the first embedding propagation layer. (表示在第一个嵌入传播层之后获得的用户u的表示)
- The activation function of LeakyReLU [23] allows messages to encode both positive and small negative signals. (LeakyReLU[23]的激活功能允许消息对正信号和小负信号进行编码。)
- (2) Note that in addition to the messages propagated from neighbors N u N_u Nu, we take the self-connection of u into consideration: m u ← u = W 1 e u m_{u←u} = W_1 e_u mu←u=W1eu, which retains the information of original features ( W 1 W_1 W1 is the weight matrix shared with the one used in Equation (3)). (注意,除了从邻居 N u N_u Nu传播的消息外,我们还考虑了u的自连接: m u ← u = W 1 e u m_{u←u} = W_1 e_u mu←u=W1eu,保留原始特征的信息( W 1 W_1 W1是权重矩阵,与等式(3)中使用的权重矩阵共享))
- Analogously, we can obtain the representation e i ( 1 ) e^{(1)}_i ei(1) for item i by propagating information from its connected users. (类似地,我们可以通过从项目i的连接用户传播信息来获得项目i的表示 e i ( 1 ) e^{(1)}_i ei(1)。)
- To summarize, the advantage of the embedding propagation layer lies in explicitly exploiting the first-order connectivity information to relate user and item representations. (总之,嵌入传播层的优势在于 显式 地利用 一阶连接性 信息来关联用户和项目表示。)
2.2.2 High-order Propagation. (高阶传播)
-
(1) With the representations augmented by first-order connectivity modeling, we can stack more embedding propagation layers to explore the high-order connectivity information. (通过一阶连通性模型对这些表示进行扩充, 我们可以堆叠更多的嵌入传播层来探索高阶连通性信息 。)
-
Such high-order connectivities are crucial to encode the collaborative signal to estimate the relevance score between a user and item. (这种高阶关联性对于编码协同信号以估计用户和项目之间的相关性分数至关重要。)
-
(2) By stacking l l l embedding propagation layers, a user (and an item) is capable of receiving the messages propagated from its l l l-hop neighbors. (通过堆叠 l l l嵌入传播层,用户(和项目)能够接收从其 l l l-hop邻居传播的消息。)
-
As Figure 2 displays, in the l l l-th step, the representation of useru is recursively formulated as: (如图2所示,在第 l l l步中,user u的表示形式递归地表示为)

-
(3) where in the messages being propagated are defined as follows, (其中,正在传播的消息定义如下:,)

- where W 1 ( l ) , W 2 ( l ) , ∈ R d l × d l − 1 W^{(l)}_1, W^{(l)}_2, \in R^{d_l \times d_{l−1}} W1(l),W2(l),∈Rdl×dl−1 are the trainable transformation matrices, (是可训练的变换矩阵,)
- and d l d_l dl is the transformation size; (是变换的大小;)
- e i ( l − 1 ) e^{(l−1)}_i ei(l−1) is the item representation generated from the previous message-passing steps, memorizing the messages from its ( l − 1 ) (l-1) (l−1)-hop neighbors. (是从前面的消息传递步骤生成的项表示,用于存储来自其 ( l − 1 ) (l-1) (l−1)-hop邻居的消息。)
- It further contributes to the representation of useru at layer l l l. (它进一步有助于用户u在层 l l l的表示。)
- Analogously, we can obtain the representation for item i at the layer l l l. (类似地,我们可以在 l l l层获得项目i的表示。)
-
(4) As Figure 3 shows, the collaborative signal like u1← i2←u2← i4can be captured in the embedding propagation process. (如图3所示,像u1← i2←u2← I4这样的协同信号可以在嵌入传播过程中捕获。)
-
Furthermore, the message from i4 is explicitly encoded in e u 1 ( 3 ) e^{(3)}_{u1} eu1(3) (indicated by the red line). (此外,来自i4的消息被显式地编码为 e u 1 ( 3 ) e^{(3)}_{u1} eu1(3)(由红线指示)。)
-
As such, stacking multiple embedding propagation layers seamlessly injects collaborative signal into the representation learning process. (因此,堆叠多个嵌入传播层可以无缝地将协同信号注入表示学习过程。)

Propagation Rule in Matrix Form. To offer a holistic view of embedding propagation and facilitate batch implementation, we provide the matrix form of the layer-wise propagation rule (equivalent to Equations (5) and (6)): (为了提供嵌入传播的整体视图并促进批量实现, 我们提供了逐层传播规则的矩阵形式 )
![]()
-
where E ( l ) ∈ R ( N + M ) × d l E^{(l)} \in R^{(N+M) \times d_l} E(l)∈R(N+M)×dl are the representations for users and items obtained after l l l steps of embedding propagation. (是在嵌入传播的 l l l步后获得的用户和项目的表示。)
-
E ( 0 ) E^{(0)} E(0) is set as E at the initial message-passing iteration, (在初始消息传递迭代时设置为E)
- that is e u ( 0 ) = e u e^{(0)}_u = e_u eu(0)=eu and e i ( 0 ) = e i e^{(0)}_i = e_i ei(0)=ei;
- and I I I denote an identity matrix. (表示一个单位矩阵。)
-
L \mathcal{L} L represents the Laplacian matrix for the user-item graph, which is formulated as: (表示用户项图 的 拉普拉斯矩阵 ,其公式如下:)

- where R ∈ R N × M R \in R^{N×M} R∈RN×M is the user-item interaction matrix, (是用户项交互矩阵,)
- and 0 is all-zero matrix; (全0矩阵)
- A is the adjacency matrix (邻接矩阵)
- and D is the diagonal degree matrix, (对角度矩阵)
- where the t-th diagonal element D t t = ∣ N t ∣ D_{tt} = |N_t| Dtt=∣Nt∣; (其中第t对角线元素)
- as such, the nonzero off-diagonal entry L u i = 1 / ∣ N u ∣ ∣ N i ∣ \mathcal{L}_{ui} = 1/ \sqrt{|N_u||N_i|} Lui=1/∣Nu∣∣Ni∣, which is equal to p u i p_{ui} pui used in Equation (3). (非零非对角项, 这等于 p u i p_{ui} pui用于等式(3))
-
By implementing the matrix-form propagation rule, we can simultaneously update the representations for all users and items in a rather efficient way. (通过实现 矩阵形式传播规则 ,我们可以以一种相当有效的方式同时更新所有用户和项目的表示。)
- It allows us to discard the node sampling procedure, which is commonly used to make graph convolution network runnable on large-scale graph [25]. We will analyze the complexity in Section 2.5.2. (它允许我们放弃节点采样过程,这通常用于使图卷积网络在大规模图上运行[25]。我们将在第2.5.2节中分析复杂性。)
2.3 Model Prediction
-
(1) After propagating with L L L layers, we obtain multiple representations for user u, namely { e u ( 1 ) , ⋅ ⋅ ⋅ , e u ( L ) } \{e^{(1)}_u, · · ·, e^{(L)}_u\} {eu(1),⋅⋅⋅,eu(L)}. (在使用 L L L层进行传播后,我们获得了用户u的多个表示,即)
- Since the representations obtained in different layers emphasize the messages passed over different connections, they have different contributions in reflecting user preference. (由于在不同层中获得的表示强调通过不同连接传递的消息,因此它们在反映用户偏好方面有不同的贡献。)
- As such, we concatenate them to constitute the final embedding for a user; (因此,我们将它们连接起来,构成用户的最终嵌入;)
- we do the same operation on items, concatenating the item representations
{
e
i
(
1
)
,
⋅
⋅
⋅
,
e
i
(
L
)
}
\{e^{(1)}_i, · · ·, e^{(L)}_i\}
{ei(1),⋅⋅⋅,ei(L)} learned by different layers to get the final item embedding: (我们对项目执行相同的操作,将项目表示
{
e
i
(
1
)
,
⋅
⋅
⋅
,
e
i
(
L
)
}
\{e^{(1)}_i, · · ·, e^{(L)}_i\}
{ei(1),⋅⋅⋅,ei(L)}通过不同层次的学习来获得最终的项目嵌入:)

- where ∥ \parallel ∥ is the concatenation operation. (是串联操作。)
-
(2) By doing so, we not only enrich the initial embeddings with embedding propagation layers, (通过这样做,我们不仅用嵌入传播层来丰富初始嵌入,)
- but also allow controlling the range of propagation by adjusting L L L. (但也允许通过调整 L L L来控制传播范围。)
-
Note that besides concatenation, other aggregators can also be applied, such as weighted average, max pooling, LSTM, etc., which imply different assumptions in combining the connectivities of different orders. (请注意,除了连接之外,还可以应用其他聚合器,例如 加权平均 、 最大池、 LSTM 等,这意味着在组合不同阶的连接时会有不同的假设。)
-
The advantage of using concatenation lies in its simplicity, since it involves no additional parameters to learn, and it has been shown quite effectively in a recent work of graph neural networks [37], which refers to layer-aggregation mechanism. (使用 串联 的优点在于它的 简单性 ,因为它不需要学习额外的参数,并且在最近的一项图形神经网络工作[37]中已经非常有效地证明了这一点,该工作涉及层聚合机制。)
-
(3) Finally, we conduct the inner product to estimate the user’s preference towards the target item: (最后,我们通过 内积 来评估用户对目标商品的偏好:)

-
(4) In this work, we emphasize the embedding function learning thus only employ the simple interaction function of inner product. Other more complicated choices, such as neural network-based interaction functions [14], are left to explore in the future work. (在这项工作中,我们 强调嵌入函数学习 ,因此只使用内积的简单交互函数。其他更复杂的选择,如基于神经网络的交互函数[14],有待于在未来的工作中探索。)
2.4 Optimization
- (1) To learn model parameters, we optimize the pairwise BPR loss [26], which has been intensively used in recommender systems [2, 13]. (为了学习模型参数,我们优化了 成对的BPR损失 [26],它已被广泛用于推荐系统[2,13])
- It considers the relative order between observed and unobserved user-item interactions. (它考虑了观察到的和未观察到的用户项交互之间的 相对顺序 。)
- Specifically, BPR assumes that the observed interactions, which are more reflective of a user’s preferences, should be assigned higher prediction values than unobserved ones. (具体来说,BPR假设观察到的交互更能反映用户的偏好,应该比未观察到的交互分配更高的预测值。)
- The objective function is as follows, (目标函数如下)

- where O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } \mathcal{O} = \{(u,i,j)|(u,i) \in \mathcal{R}^+, (u,j) ∈ \mathcal{R}^−\} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−} denotes the pairwise training data, (表示成对的训练数据,)
- R + \mathcal{R}^+ R+ indicates the observed interactions, (表示观察到的相互作用)
- and R − \mathcal{R}^− R− is the unobserved interactions; (是未被观察到的互动)
- σ ( ⋅ ) \sigma(·) σ(⋅) is the sigmoid function;
- Θ = { E , { W 1 ( l ) , W 2 ( l ) } l = 1 L } \Theta = \{E, \{W^{(l)}_1, W^{(l)}_2\}^L_{l=1} \} Θ={E,{W1(l),W2(l)}l=1L} denotes all trainable model parameters, (表示所有可训练的模型参数)
- and λ \lambda λ controls the L 2 L_2 L2 regularization strength to prevent overfitting. ( λ \lambda λ控制 L 2 L_2 L2正则化强度,以防止过度拟合。)
- (2) We adopt mini-batch Adam [17] to optimize the prediction model and update the model parameters. (我们采用mini-batch Adam[17]对预测模型进行优化,并更新模型参数)
- In particular, for a batch of randomly sampled triples ( u , i , j ) ∈ O (u,i,j) \in \mathcal{O} (u,i,j)∈O, (特别是,对于一批随机抽样的三元组)
- we establish their representations [ e ( 0 ) , ⋅ ⋅ ⋅ , e ( L ) ] [e^{(0)}, · · ·, e^{(L)}] [e(0),⋅⋅⋅,e(L)] after L L L steps of propagation, (我们建立了它们的表示 [ e ( 0 ) , ⋅ ⋅ ⋅ , e ( L ) ] [e^{(0)}, · · ·, e^{(L)}] [e(0),⋅⋅⋅,e(L)]在 L L L传播步骤之后)
- and then update model parameters by using the gradients of the loss function. (然后利用损失函数的梯度更新模型参数)
2.4.1 Model Size.
- (1) It is worth pointing out that although NGCF obtains an embedding matrix ( E ( l ) E^{(l)} E(l)) at each propagation layer l, it only introduces very few parameters — two weight matrices of size d l × d l − 1 d_l \times d_{l−1} dl×dl−1. (值得指出的是,尽管NGCF在每个传播层l获得了嵌入矩阵( E ( l ) E^{(l)} E(l)),但它只引入了很少的参数——大小为 d l × d l − 1 d_l \times d_{l−1} dl×dl−1的两个权重矩阵)
- Specifically, these embedding matrices are derived from the embedding look-up table E ( 0 ) E^{(0)} E(0), with the transformation based on the user-item graph structure and weight matrices. (具体地说,这些嵌入矩阵是从嵌入查找表 E ( 0 ) E^{(0)} E(0)导出的,其转换基于用户项图结构和权重矩阵。)
- As such, compared to MF — the most concise embedding- based recommender model, our NGCF uses only
2
L
d
l
d
l
−
1
2Ld_l d_{l−1}
2Ldldl−1 more parameters. (因此,与最简洁的基于嵌入的推荐模型MF相比,我们的NGCF只使多用了
2
L
d
l
d
l
−
1
2Ld_l d_{l−1}
2Ldldl−1.个参数 )
- Such additional cost on model parameters is almost negligible, considering that L L L is usually a number smaller than 5, (考虑到 L L L通常小于5,模型参数的额外成本几乎可以忽略不计,)
- and d l d_l dl is typically set as the embedding size, which is much smaller than the number of users and items. (还有 d l d_l dl通常设置为嵌入大小,这比用户和项目的数量小得多。)
- For example, on our experimented Gowalla dataset (20K users and 40K items), (例如,在我们实验过的Gowalla数据集上(2万个用户和4万个项目))
- when the embedding size is 64 and we use 3 propagation layers of size 64×64, (当嵌入大小为64时,我们使用3个大小为64×64的传播层)
- MF has 4.5 million parameters, (MF有450万个参数,)
- while our NGCF uses only 0.024 million additional parameters. (而我们的NGCF只使用了2.4万个额外参数。)
- when the embedding size is 64 and we use 3 propagation layers of size 64×64, (当嵌入大小为64时,我们使用3个大小为64×64的传播层)
- To summarize, NGCF uses very few additional model parameters to achieve the high-order connectivity modeling. (总之,NGCF使用很少的额外模型参数来实现高阶连接性建模。)
2.4.2 Message and Node Dropout.
-
(1) Although deep learning models have strong representation ability, they usually suffer from overfitting. (尽管深度学习模型具有很强的表征能力,但它们通常存在过度拟合问题)
-
Dropout is an effective solution to prevent neural networks from overfitting. (Dropout是防止神经网络过度拟合的有效方法。)
-
Following the prior work on graph convolutional network [29], we propose to adopt two dropout techniques in NGCF: (在之前关于图卷积网络[29]的工作之后,我们建议在NGCF中采用两种dropout技术:)
- message dropout
- and node dropout.
- Message dropout randomly drops out the outgoing messages. (Message dropout随机删除传出的消息)
- Specifically we drop out the messages being propagated in Equation (6), with a probability p 1 p_1 p1. (具体来说,我们以概率 p 1 p_1 p1dropout等式(6)中传播的消息)
- As such, in the l l l-th propagation layer, only partial messages contribute to the refined representations. (因此,在第 l l l传播层中,只有部分消息有助于细化表示。)
- We also conduct node dropout to randomly block a particular node and discard all its outgoing messages. (我们还执行节点dropout,以随机阻止特定节点并丢弃其所有传出消息)
- For the
l
l
l-th propagation layer, we randomly drop
(
M
+
N
)
p
2
(M + N) p_2
(M+N)p2 nodes of the Laplacian matrix, (对于第
l
l
l传播层, 我们随机丢弃 拉普拉斯矩阵的
(
M
+
N
)
p
2
(M + N) p_2
(M+N)p2节点)
- where p 2 p_2 p2 is the dropout ratio.
- For the
l
l
l-th propagation layer, we randomly drop
(
M
+
N
)
p
2
(M + N) p_2
(M+N)p2 nodes of the Laplacian matrix, (对于第
l
l
l传播层, 我们随机丢弃 拉普拉斯矩阵的
(
M
+
N
)
p
2
(M + N) p_2
(M+N)p2节点)
-
(2) Note that dropout is only used in training, and must be disabled during testing. (请注意,dropout仅用于培训,必须在测试期间禁用。)
- The message dropout endows the representations more robustness against the presence or absence of single connections between users and items, (消息dropout使表示对用户和项目之间存在或不存在单一连接具有更强的鲁棒性,)
- and the node dropout focuses on reducing the influences of particular users or items. (节点dropout的重点是减少特定用户或项目的影响。)
- We perform experiments to investigate the impact of message dropout and node dropout on NGCF in Section 4.4.3. (我们在第4.4.3节中进行了实验,以研究消息dropout和节点dropout对NGCF的影响。)
2.5 Discussions
In the subsection, we first show how NGCF generalizes SVD++ [19]. In what follows, we analyze the time complexity of NGCF. (在本小节中,我们首先展示NGCF如何推广SVD++[19]。接下来,我们将分析NGCF的时间复杂性。)
2.5.1 NGCF Generalizes SVD++.
-
(1) SVD++ can be viewed as a special case of NGCF with no high-order propagation layer. (SVD++可以被视为无高阶传播层的NGCF的特例。)
- In particular, we set L to one. (特别是,我们将L设为1。)
- Within the propagation layer, we disable the transformation matrix and nonlinear activation function. (在传播层中,我们禁用了 变换矩阵和 非线性激活函数。)
- Thereafter, e u ( 1 ) e^{(1)}_u eu(1) and e i ( 1 ) e^{(1)}_i ei(1) are treated as the final representations for user u and item i, respectively. (分别作为用户u和项目i的最终表示。)
- We term this simplified model as NGCF-SVD, which can be formulated as: (我们将该简化模型称为NGCF-SVD,其公式如下:)

-
(2) Clearly, by setting p u i ′ p_{ui^′} pui′ and p u ′ i p_{u^′i} pu′i as 1 / ∣ N u ∣ 1/\sqrt{|N_u|} 1/∣Nu∣ and 0 separately, we can exactly recover SVD++ model. (分别为0和0,我们可以准确地恢复SVD++模型。)
-
Moreover, another widely-used item-based CF model, FISM [16], can be also seen as a special case of NGCF, wherein p i u ′ p_{iu^′} piu′ in Equation (12) is set as 0. (此外,另一个广泛使用的基于项目的 CF模型 FISM [16]也可以被视为NGCF的特例,其中 p i u ′ p_{iu^′} piu′在等式(12)中,被设置为0。)
2.5.2 Time Complexity Analysis.
- As we can see, the layer-wise propagation rule is the main operation. (正如我们所见,分层传播规则 是主要的操作)
- For the
l
l
l-th propagation layer, the matrix multiplication has computational complexity
O
(
∣
R
+
∣
d
l
d
l
−
1
)
O(|R^+|d_l d_{l−1})
O(∣R+∣dldl−1), (对于第
l
l
l传播层,矩阵乘法具有计算复杂性)
- where ∣ R + ∣ |R^+| ∣R+∣ denotes the number of nonzero entires in the Laplacian matrix; (表示拉普拉斯矩阵中 非零实体 的数量;)
- and d l d_l dl and d l − 1 d_{l−1} dl−1 are the current and previous transformation size. (是当前和以前的转换大小)
- For the prediction layer, only the inner product is involved, for which the time complexity of the whole training epoch is O ( ∑ l = 1 L ∣ R + ∣ d l ) O(\sum^L_{l=1} |R^+| d_l) O(∑l=1L∣R+∣dl). (对于预测层,只涉及内积,整个训练周期的时间复杂度为)
- Therefore, the overall complexity for evaluating NGCF is O ( ∑ l = 1 L ∣ R + ∣ d l d l − 1 + ∑ l = 1 L ∣ R + ∣ d l ) O(\sum^L_{l=1} |R^+|d_l d_{l−1} + \sum^L_{l=1}|R^+| d_l) O(∑l=1L∣R+∣dldl−1+∑l=1L∣R+∣dl). (因此,评估NGCF的总体复杂性)
- impirically, under the same experimental settings (as explained in Section 4), MF and NGCF cost around 20s and 80s per epoch on 1 Gowalla dataset for training, respectively; during inference, the time costs of MF and NGCF are 80s and 260s for all testing instances, respectively. (有趣的是,在相同的实验设置下(如第4节所述),在1个Gowalla数据集上,MF和NGCF的训练成本分别约为20秒和80秒/历元;在推断过程中,对于所有测试实例,MF和NGCF的时间成本分别为80和260。)
3 RELATED WORK
- We review existing work on model-based CF, graph-based CF, and graph neural network-based methods, which are most relevant with this work. Here we highlight the differences with our NGCF. (我们回顾了与这项工作最相关的 基于模型的CF、基于图形的CF 和 基于图形神经网络 的方法的现有工作。在这里,我们强调与NGCF的区别。)
3.1 Model-based CF Methods
-
(1) Modern recommender systems [5, 14, 32] parameterize users and items by vectorized representations and reconstruct user-item interaction data based on model parameters. (现代推荐系统[5,14,32]通过矢量化表示对用户和项目进行参数化,并基于模型参数重建用户项目交互数据。)
- For example, MF [20, 26] projects the ID of each user and item as an embedding vector, and conducts inner product between them to predict an interaction. (例如,MF[20,26]将每个用户和项目的ID作为嵌入向量进行投影,并在它们之间进行内积以预测交互。)
- To enhance the embedding function, much effort has been devoted to incorporate side information like item content [2, 30], social relations [33], item relations [36], user reviews [3], and external knowledge graph [31, 34]. (为了增强嵌入功能,人们投入了大量精力来整合项目内容[2,30]、社会关系[33]、项目关系[36]、用户评论[3]和外部知识图[31,34]等辅助信息。)
- While inner product can force user and item embeddings of an observed interaction close to each other, its linearity makes it insufficient to reveal the complex and nonlinear relationships between users and items [14, 15]. (虽然内积可以迫使用户和观察到的交互项目嵌入彼此接近,但其线性度不足以揭示用户和项目之间复杂的非线性关系[14,15]。)
- Towards this end, recent efforts [11, 14, 15, 35] focus on exploiting deep learning techniques to enhance the interaction function, so as to capture the nonlinear feature interactions between users and items. (为此,最近的研究[11,14,15,35]侧重于利用深度学习技术来增强交互功能,从而捕捉用户和项目之间的非线性特征交互。)
- For instance, neural CF models, (例如,神经CF模型)
- such as NeuMF [14], employ nonlinear neural networks as the interaction function; (如NeuMF[14],采用非线性神经网络作为交互函数;)
- meanwhile, translation-based CF models, such as LRML [28], instead model the interaction strength with Euclidean distance metrics. (同时,基于翻译的CF模型(如LRML[28])用欧几里得距离度量对交互强度进行建模。)
- For instance, neural CF models, (例如,神经CF模型)
-
(2) Despite great success, we argue that the design of the embedding function is insufficient to yield optimal embeddings for CF, since the CF signals are only implicitly captured. (尽管取得了巨大的成功,但我们认为嵌入函数的设计不足以产生最佳的CF嵌入,因为CF信号只被隐式捕获。)
-
Summarizing these methods, the embedding function transforms the descriptive features (e.g., ID and attributes) to vectors, while the interaction function serves as a similarity measure on the vectors. (总结这些方法,嵌入函数将描述性特征(例如ID和属性)转换为向量,而交互函数用作向量的相似性度量。)
-
Ideally, when user-item interactions are perfectly reconstructed, the transitivity property of behavior similarity could be captured. (理想情况下,当用户项交互被完美重构时,行为相似性的传递性属性就可以被捕捉到。)
-
However, such transitivity effect showed in the Running Example is not explicitly encoded, thus there is no guarantee that the indirectly connected users and items are close in the embedding space. Without an explicit encoding of the CF signals, it is hard to obtain embeddings that meet the desired properties. (然而,运行示例中显示的这种及物性效果没有显式编码,因此无法保证间接连接的用户和项目在嵌入空间中是紧密的。如果不对CF信号进行显式编码,则很难获得满足所需特性的嵌入。)
3.2 Graph-Based CF Methods
-
(1) Another line of research [12, 24, 39] exploits the user-item interaction graph to infer user preference. (另一项研究[12,24,39]利用用户项目交互图推断用户偏好。)
- Early efforts, such as ItemRank [7] and BiRank [12], adopt the idea of label propagation to capture the CF effect. To score items for a user, these methods define the labels as her interacted items, and propagate the labels on the graph. ((早期的研究,如ItemRank[7]和BiRank[12],采用了 标签传播的思想 来捕捉 CF效应。为了给用户的项目打分,这些方法将标签定义为用户交互的项目,并在图形上传播标签。)
- As the recommendation scores are obtained based on the structural reachness (which can be seen as a kind of similarity) between the historical items and the target item, these methods essentially belong to neighbor-based methods. 由于推荐分数是基于历史项目和目标项目之间的 结构可达性(可以视为一种相似性)获得的,因此这些方法本质上属于 基于邻居的方法。)
- However, these methods are conceptually inferior to model-based CF methods, since there lacks model parameters to optimize the objective function of recommendation. (然而,由于缺乏优化推荐目标函数的模型参数,这些方法在概念上不如基于模型的CF方法。)
-
(2) The recently proposed method HOP-Rec [39] alleviates the problem by combining graph-based with embedding-based method. (最近提出的方法HOP Rec[39]将基于图的方法与基于嵌入的方法相结合,从而缓解了这个问题。)
- It first performs random walks to enrich the interactions of a user with multi-hop connected items. (它首先执行随机行走,以丰富用户与多跳连接项的交互。)
- Then it trains MF with BPR objective based on the enriched user-item interaction data to build the recommender model. (然后,基于丰富的用户项目交互数据,以BPR为目标对MF进行训练,建立推荐模型。)
- The superior performance of HOP-Rec over MF provides evidence that incorporating the connectivity information is beneficial to obtain better embeddings in capturing the CF effect. (HOP-Rec优于MF的性能证明,结合 连通性信息 有助于在捕获CF效应时获得更好的嵌入。)
- However, we argue that HOP-Rec does not fully explore the high-order connectivity, which is only utilized to enrich the training data1, rather than directly contributing to the model’s embedding function. (然而,我们认为HOP-Rec并没有充分探索高阶连接性,高阶连接性仅用于丰富训练数据1,而不是直接用于模型的嵌入功能。)
- Moreover, the performance of HOP-Rec depends heavily on the random walks, which require careful tuning efforts such as a proper setting of decay factor. (此外,HOP-Rec的性能在很大程度上取决于 随机游走,这需要仔细调整,例如适当设置 衰减因子 。)
3.3 Graph Convolutional Networks
-
(1) By devising a specialized graph convolution operation on user-item interaction graph (cf. Equation (3)), we make NGCF effective in exploiting the CF signal in high-order connectivities. Here we discuss existing recommendation methods that also employ graph convolution operations [29, 41, 42]. (通过在用户项交互图(参见等式(3))上设计专门的 图卷积运算,我们使NGCF有效地利用 高阶连通性 中的 cf信号 。在这里,我们讨论了也采用 图卷积运算 的现有推荐方法[29,41,42]。)
-
(2) GC-MC [29] applies the graph convolution network (GCN) [18] on user-item graph, (GC-MC[29]将图卷积网络(GCN)[18]应用于用户项图)
- however it only employs one convolutional layer to exploit the direct connections between users and items. (然而,它只使用 一个卷积层 来利用用户和项目之间的直接连接。)
- Hence it fails to reveal collaborative signal in high-order connectivities. (因此,它无法在高阶连通性中揭示协同信号。)
-
PinSage [41] is an industrial solution that employs multiple graph convolution layers on item-item graph for Pinterest image recommendation. (PinSage[41]是一种工业解决方案,在项目图上使用 多个图卷积层 来推荐Pinterest图像。)
- As such, the CF effect is captured on the level of item relations, rather than the collective user behaviors. (因此,CF影响是在项目关系的层面上捕捉的,而不是在用户的集体行为上。)
-
SpectralCF [42] proposes a spectral convolution operation to discover all possible connectivity between users and items in the spectral domain. (SpectralCF[42]提出了一种 频谱卷积操作 ,以发现 频谱域中 用户和项目之间所有可能的连接。)
- Through the eigen-decomposition of graph adjacency matrix, it can discover the connections between a user-item pair. (通过 图邻接矩阵 的 特征分解 ,可以发现用户项对之间的联系。)
- However, the eigen-decomposition causes a high computational complexity, which is very time-consuming and difficult to support large-scale recommendation scenarios. (然而,特征分解会导致较高的计算复杂度,这非常耗时,并且难以支持大规模的推荐场景。)
4 EXPERIMENTS
- (1) We perform experiments on three real-world datasets to evaluate our proposed method, especially the embedding propagation layer. (我们在三个真实数据集上进行了实验,以评估我们提出的方法,尤其是嵌入传播层。)
- We aim to answer the following research questions: (我们旨在回答以下研究问题:)
- RQ1: How does NGCF perform as compared with state-of-the-art CF methods? (与最先进的CF方法相比,NGCF的性能如何?)
- RQ2: How do different hyper-parameter settings (e.g., depth of layer, embedding propagation layer, layer-aggregation mechanism, message dropout, and node dropout) affect NGCF? (不同的超参数设置(例如,层深度、嵌入传播层、层聚合机制、消息丢失和节点丢失)如何影响NGCF?)
- RQ3: How do the representations benefit from the high-order connectivity? (表示如何从高阶连接性中受益?)
4.1 Dataset Description
-
(1) To evaluate the effectiveness of NGCF, we conduct experiments on three benchmark datasets: Gowalla, Yelp2018, and Amazon-book, which are publicly accessible and vary in terms of domain, size, and sparsity. We summarize the statistics of three datasets in Table 1. (为了评估NGCF的有效性,我们在三个基准数据集上进行了实验:Gowalla、Yelp2018和Amazon book,这些数据集可以公开访问,并且在域、大小和稀疏性方面有所不同。我们在表1中总结了三个数据集的统计数据。)

-
Gowalla: This is the check-in dataset [21] obtained from Gowalla, where users =share their locations== by checking-in. To ensure the quality of the dataset, we use the 10-core setting [10], i.e., retaining users and items with at least ten interactions. (这是从Gowalla获得的签入数据集[21],用户通过签入共享他们的位置。为了确保数据集的质量,我们使用了10个核心设置[10],即保留至少有10个交互的用户和项目。)
-
Yelp2018: This dataset is adopted from the 2018 edition of the Yelp challenge. Wherein, the local businesses like restaurants and bars are viewed as the items. We use the same 10-core setting in order to ensure data quality. (该数据集取自2018年版的Yelp挑战赛。其中,餐厅 和 酒吧 等当地企业被视为项目。我们使用相同的10核设置,以确保数据质量。)
-
Amazon-book: Amazon-review is a widely used dataset for product recommendation [9]. We select Amazon-book from the collection. Similarly, we use the 10-core setting to ensure that each user and item have at least ten interactions. (Amazon review是一个广泛使用的产品推荐数据集[9]。我们从收藏中选择亚马逊图书。类似地,我们使用10个核心设置来确保每个用户和项目至少有10个交互。)
-
(2) For each dataset, we randomly select 80% of historical interactions of each user to constitute the training set, and treat the remaining as the test set. From the training set, we randomly select10%of interactions as validation set to tune hyper-parameters. (对于每个数据集,我们随机选择每个用户80%的历史交互来构成训练集,并将剩余的作为测试集。从训练集中,我们随机选择10%的交互作为验证集来调整超参数。)
-
For each observed user-item interaction, we treat it as a positive instance, (对于每个观察到的用户项目交互,我们将其视为一个正实例)
- and then conduct the negative sampling strategy to pair it with one negative item that the user did not consume before. (然后执行 负采样策略,将其与用户以前没有消费过的一个负项目配对。)
4.2 Experimental Settings
4.2.1 Evaluation Metrics.
- (1) For each user in the test set, we treat all the items that the user has not interacted with as the negative items. (对于测试集中的每个用户,我们将用户未交互的所有项目视为负项目。)
- Then each method outputs the user’s preference scores over all the items, except the positive ones used in the training set. (然后,每种方法都会输出用户对所有项目的偏好分数,除了训练集中使用的积极项目。)
- To evaluate the effectiveness of top-K recommendation and preference ranking, we adopt two widely-used evaluation protocols [14, 39]: (为了评估top-K推荐和偏好排名的有效性,我们采用了两种广泛使用的评估协议[14,39]:)
- recall@K
- and ndcg@K.
- By default, we set K = 20.
- We report the average metrics for all users in the test set. (我们报告测试集中所有用户的 平均指标 。)
4.2.2 Baselines.
To demonstrate the effectiveness, we compare our proposed NGCF with the following methods: (为了证明其有效性,我们将我们提出的NGCF与以下方法进行了比较:)
- MF [26]: This is matrix factorization optimized by the Bayesian personalized ranking (BPR) loss, which exploits the user-item direct interactions only as the target value of interaction function. (这是由贝叶斯个性化排名(BPR)损失优化的矩阵分解,它仅利用用户项直接交互作为交互函数的目标值。)
- NeuMF [14]: The method is a state-of-the-art neural CF model which uses multiple hidden layers above the element-wise and concatenation of user and item embeddings to capture their non-linear feature interactions. Especially, we employ two-layered plain architecture, where the dimension of each hidden layer keeps the same. (该方法是一种最先进的神经CF模型,它在元素层次上使用 多个隐藏层,并将用户和项目嵌入 串联 起来,以捕获其非线性特征交互。特别是,我们采用了两层平面结构,其中每个隐藏层的尺寸保持不变。)
- CMN [5]: It is a state-of-the-art memory-based model, where the user representation attentively combines the memory slots of neighboring users via the memory layers. Note that the first-order connections are used to find similar users who interacted with the same items. (它是一种 基于内存 的最先进模型,其中用户表示通过内存层仔细地组合相邻用户的 内存插槽。请注意,一阶连接 用于查找与相同项目交互的类似用户。)
- HOP-Rec [39]: This is a state-of-the-art graph-based model, where the high-order neighbors derived from random walks are exploited to enrich the user-item interaction data. (这是一个最先进的基于图的模型,利用随机游动产生的高阶邻域来丰富用户项交互数据。)
- PinSage [41]: PinSage is designed to employ GraphSAGE [8] on item-item graph. In this work, we apply it on user-item interaction graph. Especially, we employ two graph convolution layers as suggested in [41], and the hidden dimension is set equal to the embedding size. (PinSage设计用于在项目图上使用GraphSAGE[8]。在这项工作中,我们将其应用于用户项交互图。特别是,我们使用了[41]中建议的两个图卷积层,并且隐藏维度设置为嵌入大小。)
- GC-MC [29]: This model adopts GCN [18] encoder to generate the representations for users and items, where only the first-order neighbors are considered. Hence one graph convolution layer, where the hidden dimension is set as the embedding size, is used as suggested in [29]. (该模型采用GCN[18]编码器生成用户和项目的表示,只考虑一阶邻居。因此,按照[29]中的建议,使用了一个图卷积层,其中隐藏维度被设置为嵌入大小。)
We also tried SpectralCF [42] but found that the eigen-decomposition leads to high time cost and resource cost, especially when the number of users and items is large. Hence, although it achieved promising performance in small datasets, we did not select it for comparison. For fair comparison, all methods optimize the BPR loss as shown in Equation (11). (我们还尝试了SpectralCF[42],但发现 特征分解 会导致较高的时间成本和资源成本,尤其是当用户和项目数量较大时。因此,尽管它在小数据集上取得了很好的性能,但我们没有选择它进行比较。为了进行公平比较,所有方法都优化了 BPR损失 ,如等式(11)所示。)
4.2.3 Parameter Settings.
- We implement our NGCF model in Tensorflow.
- The embedding size is fixed to 64 for all models.
- For HOP-Rec, we search the steps of random walks in {1,2,3} and tune the learning rate in {0.025,0.020,0.015,0.010}.
- We optimize all models except HOP-Rec with the Adam optimizer,
- where the batch size is fixed at 1024.
- In terms of hyperparameters, we apply a grid search for hyperparameters: the learning rate is tuned amongst {0.0001,0.0005,0.001,0.005},
- the coefficient of L 2 L_2 L2 normalization is searched in { 1 0 − 5 , 1 0 − 4 , ⋅ ⋅ ⋅ , 1 0 1 , 1 0 2 } \{10^{−5},10^{−4},· · ·,10^1,10^2\} {10−5,10−4,⋅⋅⋅,101,102},
- and the dropout ratio in {0.0,0.1,· · ·,0.8}.
- Besides, we employ the node dropout technique for GC-MC and NGCF,
- where the ratio is tuned in {0.0,0.1,· · ·,0.8}.
- We use the Xavier initializer [6] to initialize the model parameters.
- Moreover, early stopping strategy is performed, i.e., premature stopping if recall@20 on the validation data does not increase for 50 successive epochs.
- To model the CF signal encoded in third-order connectivity, we set the depth of NGCF L L L as three.
- Without specification, we show the results of three embedding propagation layers, node dropout ratio of 0.0, and message dropout ratio of 0.1.
4.3 Performance Comparison (RQ1)
We start by comparing the performance of all the methods, and then explore how the modeling of high-order connectivity improves under the sparse settings. (我们首先比较了所有方法的性能,然后探讨了在稀疏设置下 高阶连通性 的建模是如何改进的。)

4.3.1 Overall Comparison.
Table 2 reports the performance comparison results. We have the following observations: (表2报告了性能比较结果。我们有以下观察结果:)
- MF achieves poor performance on three datasets. This indicates that the inner product is insufficient to capture the complex relations between users and items, further limiting the performance. NeuMF consistently outperforms MF across all cases, demonstrating the importance of nonlinear feature interactions between user and item embeddings. However, neither MF nor NeuMF explicitly models the connectivity in the embedding learning process, which could easily lead to suboptimal representations. (MF在三个数据集上表现不佳。这表明内积不足以捕捉用户和项目之间的复杂关系,进一步限制了性能。NeuMF在所有情况下都始终优于MF,这证明了用户和项目嵌入之间非线性特征交互的重要性。然而,MF和NeuMF都没有明确建模嵌入学习过程中的连通性,这很容易导致次优表示。)
- Compared to MF and NeuMF, the performance of GC-MC verifies that incorporating the first-order neighbors can improve the representation learning. However, in Yelp2018, GC-MC underperforms NeuMF w.r.t. ndcg@20. The reason might be that GC-MC fails to fully explore the nonlinear feature interactions between users and items. (与MF和NeuMF相比,GC-MC的性能验证了加入一阶邻域可以改善表征学习。然而,在2018年的Yelp2018中,GC-MC的表现不如NeuMF w.r.t。ndcg@20.原因可能是GC-MC未能充分探索用户和项目之间的非线性特征交互。)
- CMN generally achieves better performance than GC-MC in most cases. Such improvement might be attributed to the neural attention mechanism, which can specify the attentive weight of each neighboring user, rather than the equal or heuristic weight used in GC-MC. (在大多数情况下,CMN通常比GC-MC实现更好的性能。这种改善可能归因于神经注意机制,它可以指定每个相邻用户的注意权重,而不是GC-MC中使用的相等或启发式权重。)
- PinSage slightly underperforms CMN in Gowalla and Amazon-Book, while performing much better in Yelp2018; meanwhile, HOP-Rec generally achieves remarkable improvements in most cases. It makes sense since PinSage introduces high-order connectivity in the embedding function, and HOP-Rec exploits high-order neighbors to enrich the training data, while CMN considers the similar users only. It therefore points to the positive effect of modeling the high-order connectivity or neighbors. (PinSage在Gowalla和Amazon Book中的表现略逊于CMN,而在Yelp2018中的表现要好得多;同时,在大多数情况下,HOP Rec通常会取得显著的改进。这是有意义的,因为PinSage在嵌入函数中引入了高阶连接性,HOP-Rec利用高阶邻居来丰富训练数据,而CMN只考虑相似的用户。因此,它指出了对高阶连通性或邻居建模的积极影响。)
- NGCF consistently yields the best performance on all the datasets. In particular, NGCF improves over the strongest baselines w.r.t.
recall@20 by 10.18%, 12.88%, and 11.32% in Gowalla, Yelp2018, and Amazon-Book, respectively. By stacking multiple embedding
propagation layers, NGCF is capable of exploring the high-order connectivity in an explicit way, while CMN and GC-MC only utilize the first-order neighbors to guide the representation learning. This verifies the importance of capturing collaborative signal in the embedding function. Moreover, compared with PinSage, NGCF considers multi-grained representations to infer user preference, while PinSage only uses the output of the last layer. This demonstrates that different propagation layers encode different information in the representations. And the improvements over HOP-Rec indicate that explicit encoding CF in the embedding function can achieve better representations. We conduct one-sample t-tests and p-value < 0.05 indicates that the improvements of NGCF over the strongest baseline are statistically significant. (NGCF始终在所有数据集上产生最佳性能。特别是,NGCF比w.r.t.的最强基线有所改善。recall@20Gowalla、Yelp2018和Amazon Book分别下降了10.18%、12.88%和11.32%。通过叠加多个嵌入传播层,NGCF能够以显式方式探索高阶连通性,而CMN和GC-MC仅利用一阶邻域来指导表示学习。这验证了在嵌入函数中捕获协同信号的重要性。此外,与PinSage相比,NGCF考虑多粒度表示来推断用户偏好,而PinSage只使用最后一层的输出。这表明不同的传播层在表示中编码不同的信息。对HOP-Rec的改进表明,嵌入函数中的显式编码CF可以实现更好的表示。我们进行了单样本t检验,p-value < 0.05表明NGCF在最强基线上的改善具有统计学意义。)
4.3.2 Performance Comparison w.r.t. Interaction Sparsity Levels.
-
(1) The sparsity issue usually limits the expressiveness of recommender systems, since few interactions of inactive users are insufficient to generate high-quality representations. We investigate whether exploiting connectivity information helps to alleviate this issue. (稀疏性问题通常会限制推荐系统的表达能力,因为非活动用户的少量交互不足以生成高质量的表示。我们调查利用连通性信息是否有助于缓解这个问题。)
-
(2) Towards this end, we perform experiments over user groups of different sparsity levels. In particular, based on interaction number per user, we divide the test set into four groups, each of which has the same total interactions. Taking Gowalla dataset as an example, the interaction numbers per user are less than 24, 50, 117, and 014 respectively. Figure 4 illustrates the results w.r.t. ndcg@20 on different user groups in Gowalla, Yelp2018, and Amazon-Book; we see a similar trend for performance w.r.t. recall@20 and omit the part due to the space limitation. We find that: (为此,我们对不同稀疏级别的用户组进行了实验。特别是,根据每个用户的交互次数,我们将测试集分为四个组,每个组的总交互次数相同。以Gowalla数据集为例,每个用户的交互次数分别小于24、50、117和014。图4显示了w.r.t.的结果。ndcg@20在Gowalla、Yelp2018和Amazon Book的不同用户群上;我们看到了类似的表现趋势。recall@20由于空间限制,省略了该部分。我们发现:)
-
(3) NGCF and HOP-Rec consistently outperform all other baselines on all user groups. It demonstrates that exploiting high-order connectivity greatly facilitates the representation learning for inactive users, as the collaborative signal can be effectively captured. Hence, it might be promising to solve the sparsity issue in recommender systems, and we leave it in future work. (NGCF和HOP Rec在所有用户组上的表现都始终优于所有其他基线。研究表明,利用高阶连通性可以有效地捕获协同信号,极大地促进了非活动用户的表示学习。因此,解决推荐系统中的稀疏性问题可能是有希望的,我们将在未来的工作中讨论它。)
-
(4) Jointly analyzing Figures 4(a), 4(b), and 4(c ), we observe that the improvements achieved in the first two groups (e.g., 6.78%
and 3.75% over the best baselines separately for < 24 and < 50 in Gowalla) are more significant than that of the others (e.g., 0.49% for < 117 Gowalla groups). It verifies that the embedding propagation is beneficial to the relatively inactive users. (联合分析图4(a)、图4(b)和图4(c),我们观察到前两组的改善(例如,Gowalla组<24和<50的最佳基线分别比6.78%和3.75%)比其他组(例如<117 Gowalla组0.49%)更显著。验证了嵌入传播对相对不活跃的用户是有益的。)
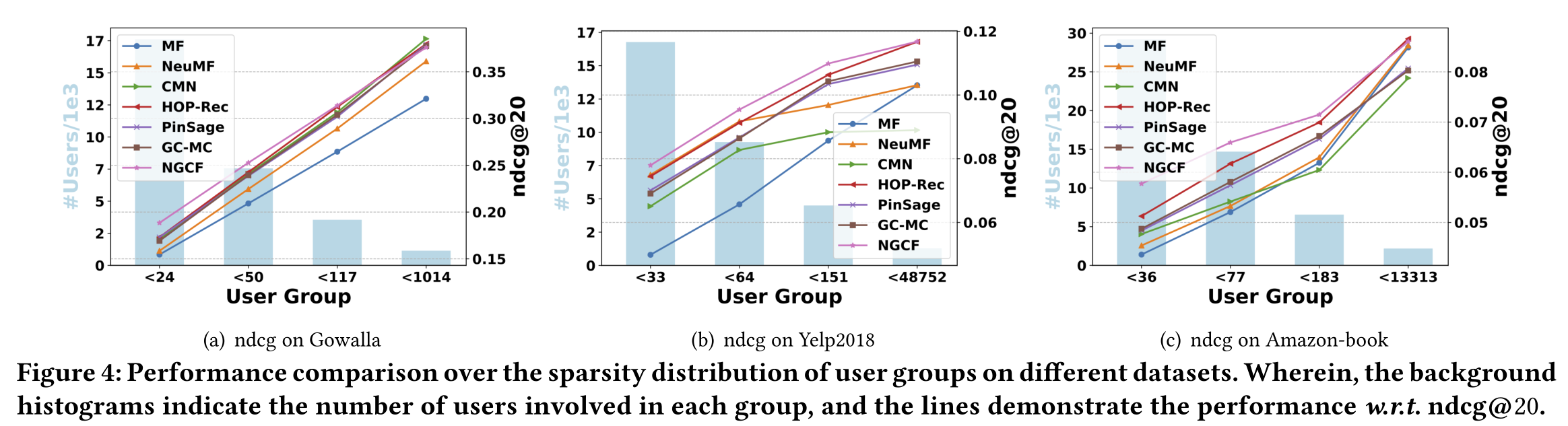
图4:不同数据集上用户组稀疏分布的性能比较。其中,背景直方图表示每组涉及的用户数量,线条表示性能
4.4 Study of NGCF (RQ2)
As the embedding propagation layer plays a pivotal role in NGCF, we investigate its impact on the performance. (由于 嵌入传播层 在NGCF中起着关键作用,我们研究了它对性能的影响。)
- We start by exploring the influence of layer numbers. We then study how the Laplacian matrix (i.e.,discounting factor p u i p_{ui} pui between user u and item i) affects the performance. (我们从探索层数的影响开始。然后,我们研究拉普拉斯矩阵(即useru和itemi之间的贴现因子 p u i p_{ui} pui)如何影响性能。)
- Moreover, we analyze the influences of key factors, such as node dropout and message dropout ratios. We also study the training process of NGCF. (此外,我们还分析了节点丢失率和消息丢失率等关键因素的影响。我们还研究了NGCF的训练过程。)
4.4.1 Effect of Layer Numbers.
- (1) To investigate whether NGCF can benefit from multiple embedding propagation layers, we vary the model depth. In particular, we search the layer numbers in the range of {1,2,3,4}. Table 3 summarizes the experimental results, wherein NGCF-3 indicates the model with three embedding propagation layers, and similar notations for others. Jointly analyzing Tables 2 and 3, we have the following observations: (为了研究NGCF是否能受益于多个嵌入传播层,我们改变了 模型深度。特别地,我们在{1,2,3,4}范围内搜索层号。表3总结了实验结果,其中NGCF-3表示具有三个嵌入传播层的模型,以及其他类似符号。综合分析表2和表3,我们得出以下观察结果:)
- Increasing the depth of NGCF substantially enhances the recommendation cases. Clearly, NGCF-2 and NGCF-3 achieve consistent improvement over NGCF-1 across all the board, which considers the first-order neighbors only. We attribute the improvement to the effective modeling of CF effect: collaborative user similarity and collaborative signal are carried by the second- and third-order connectivities, respectively. (增加NGCF的深度可以显著增强推荐案例。显然,NGCF-2和NGCF-3在所有方面都比NGCF-1取得了一致的改进,这只考虑了一阶邻居。我们将这一改进归因于CF效应的有效建模:协同用户相似度 和 协同信号 分别由 二阶 和 三阶 连接承载。)
- When further stacking propagation layer on the top of NGCF-3, we find that NGCF-4 leads to overfitting on Yelp2018 dataset. This might be caused by applying a too deep architecture might introduce noises to the representation learning. The marginal improvements on the other two datasets verifies that conducting three propagation layers is sufficient to capture the CF signal. (当进一步将传播层叠加在NGCF-3的顶部时,我们发现NGCF-4会导致对Yelp2018数据集的过度拟合。这可能是因为应用过深的架构可能会给表征学习带来噪音。对其他两个数据集的边际改进验证了传导三个传播层足以捕获CF信号。)
- When varying the number of propagation layers, NGCF is consistently superior to other methods across three datasets. It again verifies the effectiveness of NGCF, empirically showing that explicit modeling of high-order connectivity can greatly facilitate the recommendation task. (当改变传播层的数量时,NGCF在三个数据集上始终优于其他方法。它再次验证了NGCF的有效性,经验表明,高阶连通性的显式建模可以极大地促进推荐任务。)


4.4.2 Effect of Embedding Propagation Layer and Layer- Aggregation Mechanism.
- (1) To investigate how the embedding propagation (i.e., graph convolution) layer affects the performance, we consider the variants of NGCF-1 that use different layers. In particular, we remove the representation interaction between a node and its neighbor from the message passing function (cf. Equation(3)) and set it as that of PinSage and GC-MC, termed NGCF-1PinSage and NGCF-1GC-MC respectively. Moreover, following SVD++, we obtain one variant based on Equations (12), termed NGCF-1SVD++. We show the results in Table 4 and have the following findings: (为了研究 嵌入传播(即,图卷积)层 如何影响性能,我们考虑使用不同层的NGCF-1的变体。特别是,我们从消息传递函数(参见等式(3))中删除了节点与其邻居之间的表示交互,并将其设置为PinSage和GC-MC的表示交互,分别称为NGCF-1PinSage和NGCF-1GC-MC。此外,在SVD++之后,我们根据方程式(12)获得了一个变量,称为NGCF-1SVD++。我们在表4中给出了结果,并得出以下结论:)
- NGCF-1 is consistently superior to all variants. We attribute the improvements to the representation interactions (i.e., eu⊙ ei), which makes messages being propagated dependent on the affinity between ei and eu and functions like the attention mechanism [2]. Whereas, all variants only take linear transformation into consideration. It hence verifies the rationality and effectiveness of our embedding propagation function. (NGCF-1始终优于所有变体。我们将改进归因于表征交互(即eu⊙ ei),这使得信息的传播依赖于ei和eu之间的亲和力 以及 注意机制 等功能[2]。然而,所有变量只考虑线性变换。从而验证了嵌入传播函数的合理性和有效性)
- In most cases, NGCF-1SVD++ underperforms NGCF-1PinSage and NGCF-1GC-MC. It illustrates the importance of messages passed by the nodes themselves and the nonlinear transformation. (在大多数情况下,NGCF-1SVD++的表现不如NGCF-1Pinsage和NGCF-1GC-MC。它说明了 节点本身传递的消息 以及非线性转换的重要性。)
- Jointly analyzing Tables 2 and 4, we find that, when concatenating all layers’ outputs together, NGCF-1PinSage and NGCF-1GC-MC achieve better performance than PinSage and GC-MC, respectively. This emphasizes the significance of layer-aggregation mechanism, which is consistent with [37]. (联合分析表2和表4,我们发现,当将所有层的输出连接在一起时,NGCF-1Pinsage和NGCF-1GC-MC分别比PinSage和GC-MC实现更好的性能。这强调了 层聚合机制 的重要性,这与[37]一致。)
4.4.3 Effect of Dropout.
- (1) Following the prior work [29], we employ node dropout and message dropout techniques to prevent NGCF from overfitting. Figure 5 plots the effect of message dropout ratio
p
1
p_1
p1 and node dropout ratio
p
2
p_2
p2 against different evaluation protocols on different datasets. (在之前的工作[29]之后,我们采用节点dropout 和消息dropout 技术来防止NGCF过度拟合。图5绘制了消息丢失率
p
1
p_1
p1和节点丢失率
p
2
p_2
p2对不同数据集上不同评估协议的影响。)

- (2) Between the two dropout strategies, node dropout offers better performance. Taking Gowalla as an example, settingp2as 0.2 leads to the highest recall@20 of 0.1514, which is better than that of message dropout 0.1506. One reason might be that dropping out all outgoing messages from particular users and items makes the representations robust against not only the influence of particular edges, but also the effect of nodes. Hence, node dropout is more effective than message dropout, which is consistent with the findings of prior effort [29]. We believe this is an interesting finding, which means that node dropout can be an effective strategy to address overfitting of graph neural networks. ( 在这两种dropout策略之间,节点dropout提供了更好的性能 。以Gowalla为例,将p2设置为0.2会导致最高recall@200.1514,优于消息丢失0.1506。一个原因可能是,删除来自特定用户和项目的所有传出消息,使得表示不仅能够抵抗特定边缘的影响,而且能够抵抗节点的影响。因此,节点丢失比消息丢失更有效,这与之前的研究结果一致[29]。我们认为这是一个有趣的发现,这意味着节点丢失可以成为解决图神经网络过度拟合的有效策略。)
4.4.4 Test Performance w.r.t. Epoch.
Figure 6 shows the test performance w.r.t. recall of each epoch of MF and NGCF. Due to the space limitation, we omit the performance w.r.t. ndcg which has the similar trend. We can see that, NGCF exhibits fast convergence than MF on three datasets. It is reasonable since indirectly connected users and items are involved when optimizing the interaction pairs in mini-batch. Such an observation demonstrates the better model capacity of NGCF and the effectiveness of performing embedding propagation in the embedding space. (图6显示了MF和NGCF每个时期的测试性能w.r.t召回。由于空间限制,我们省略了具有类似趋势的性能w.r.t.ndcg。我们可以看到,在三个数据集上,NGCF比MF表现出更快的收敛性。这是合理的,因为在小批量优化交互对时,涉及到间接连接的用户和项目。这样的观察证明了NGCF更好的模型容量和在嵌入空间中执行嵌入传播的有效性。)

4.5 Effect of High-order Connectivity (RQ3)
-
(1) In this section, we attempt to understand how the embedding propagation layer facilitates the representation learning in the embedding space. Towards this end, we randomly selected six users from Gowalla dataset, as well as their relevant items. We observe how their representations are influenced w.r.t. the depth of NGCF. (在本节中,我们试图了解 嵌入传播层 如何促进嵌入空间中的表示学习。为此,我们从Gowalla数据集中随机选择了六名用户,以及他们的相关项目。我们观察了NGCF的深度对他们表达的影响。)

-
(2) Figures 7(a) and 7(b) show the visualization of the representations derived from MF (i.e., NGCF-0) and NGCF-3, respectively. Note that the items are from the test set, which are not paired with users in the training phase. There are two key observations: (图7(a)和图7(b)分别显示了源自MF(即NGCF-0)和NGCF-3的表示的可视化。请注意,这些项目来自测试集,在培训阶段没有与用户配对。有两个关键观察结果:)
- The connectivities of users and items are well reflected in the embedding space, that is, they are embedded into the near part of the space. In particular, the representations of NGCF-3 exhibit discernible clustering, meaning that the points with the same colors (i.e., the items consumed by the same users) tend to form the clusters. (嵌入空间很好地反映了用户和项目的连通性,也就是说,它们被嵌入到空间的近端。特别是,NGCF-3的表示呈现出明显的聚类,这意味着 具有相同颜色的点(即相同用户消费的项目)倾向于形成聚类。)
- Jointly analyzing the same users (e.g., 12201 and 6880) across Figures 7(a) and 7(b), we find that, when stacking three embedding propagation layers, the embeddings of their historical items tend to be closer. It qualitatively verifies that the proposed embedding propagation layer is capable of injecting the explicit collaborative signal (via NGCF-3) into the representations. (通过对图7(a)和图7(b)中相同用户(例如12201和6880)的联合分析,我们发现,当堆叠三个嵌入传播层时,它们的历史项目的嵌入往往更紧密。定性地验证了所提出的嵌入传播层能够将显式协同信号(通过NGCF-3)注入到表示中。)
5 CONCLUSION AND FUTURE WORK
-
(1) In this work, we explicitly incorporated collaborative signal into the embedding function of model-based CF . (在这项工作中,我们 明确地 将 协同信号 纳入 基于模型的CF 的 嵌入功能 中。)
- We devised a new framework NGCF, which achieves the target by leveraging high-order connectivities in the user-item integration graph. (我们设计了一个新的框架NGCF,它通过利用 用户项目集成图 中的 高阶连接性 来实现目标。)
- The key of NGCF is the newly proposed embedding propagation layer, based on which we allow the embeddings of users and items interact with each other to harvest the collaborative signal. (NGCF的 关键 是新提出的 嵌入传播层 ,在此基础上,我们允许用户和项目的嵌入相互作用,以获取 协同信号 。)
- Extensive experiments on three real-world datasets demonstrate the rationality and effectiveness of injecting the user-item graph structure into the embedding learning process. (在三个真实数据集上的大量实验证明了将用户项图结构注入嵌入学习过程的合理性和有效性。)
-
(2) In future, we will further improve NGCF by incorporating the attention mechanism [2] to learn variable weights for neighbors during embedding propagation and for the connectivities of different orders. (在未来,我们将通过结合 注意机制 [2]来进一步改进NGCF,以便在嵌入传播过程中学习邻居的可变权重,以及不同阶次的连通性。)
- This will be beneficial to model generalization and interpretability. (这将有利于模型的泛化和可解释性。)
- Moreover, we are interested in exploring the adversarial learning [13] on user/item embedding and the graph structure for enhancing the robustness of NGCF. (此外,我们有兴趣探索关于用户/项目嵌入的对抗性学习[13],以及增强NGCF鲁棒性的图形结构。)
-
(3) This work represents an initial attempt to exploit structural knowledge with the message-passing mechanism in model-based CF and opens up new research possibilities. (这项工作代表了在基于模型的CF中利用 消息传递机制 的 结构知识 的初步尝试,并开辟了新的研究可能性。)
- Specifically, there are many other forms of structural information can be useful for understanding user behaviors, such as (具体来说,还有许多其他形式的结构信息可用于理解用户行为,例如)
- the cross features [40] in context-aware and semantics-rich recommendation [22, 27], item knowledge graph [31], and social networks [33]. (上下文感知和语义丰富的推荐[22,27]、项目知识图[31]和社交网络[33]中的交叉特征[40]。)
- For example, by integrating item knowledge graph with user-item graph, we can establish knowledge-aware connectivities between users and items, which help unveil user decision-making process in choosing items. (例如,通过集成 项目知识图 和 用户项目图 ,我们可以在用户和项目之间建立 知识感知连接 ,这有助于揭示用户选择项目的决策过程。)
- We hope the development of NGCF is beneficial to the reasoning of user online behavior towards more effective and interpretable recommendation. (我们希望NGCF的发展有助于用户在线行为的推理,从而实现更有效、更可解释的推荐。)
- Specifically, there are many other forms of structural information can be useful for understanding user behaviors, such as (具体来说,还有许多其他形式的结构信息可用于理解用户行为,例如)















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









