






分类
1、导入数据
iris = datasets.load_iris()
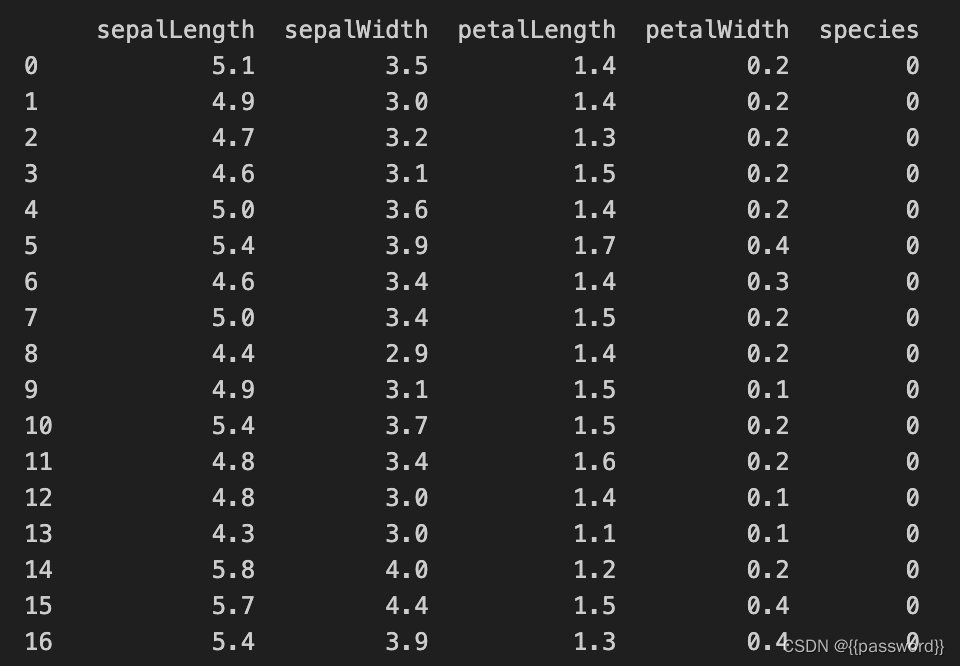
data=pd.DataFrame(iris['data'],columns=['sepalLength','sepalWidth','petalLength','petalWidth'])
data['species']=iris.target
data.describe()
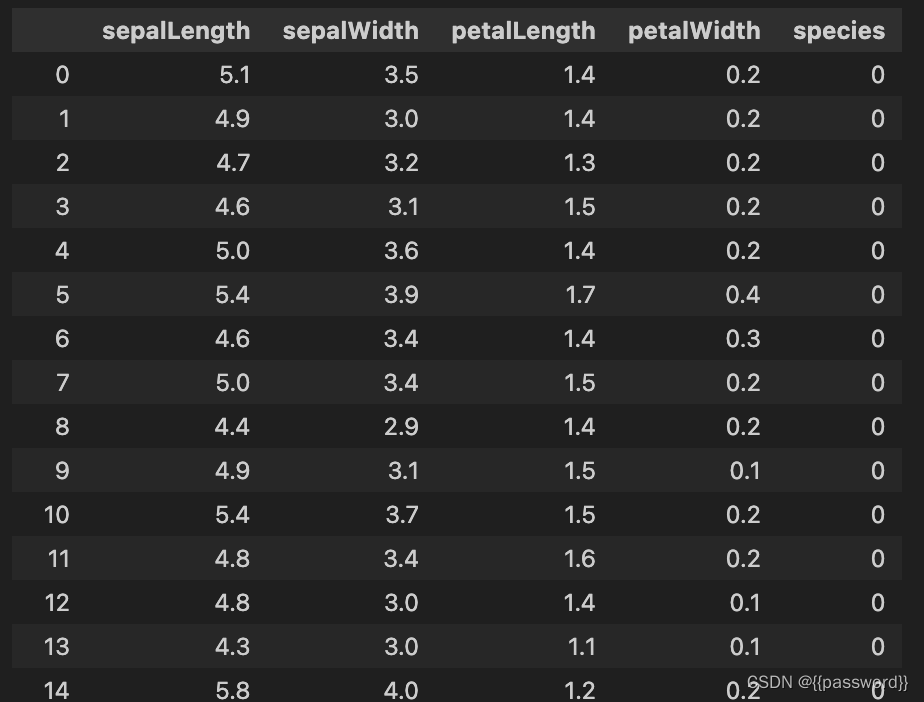

数据展示
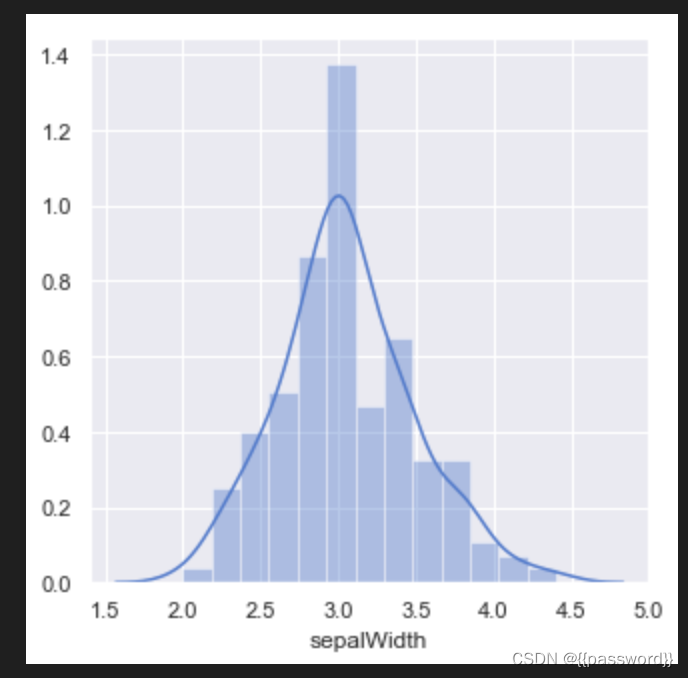
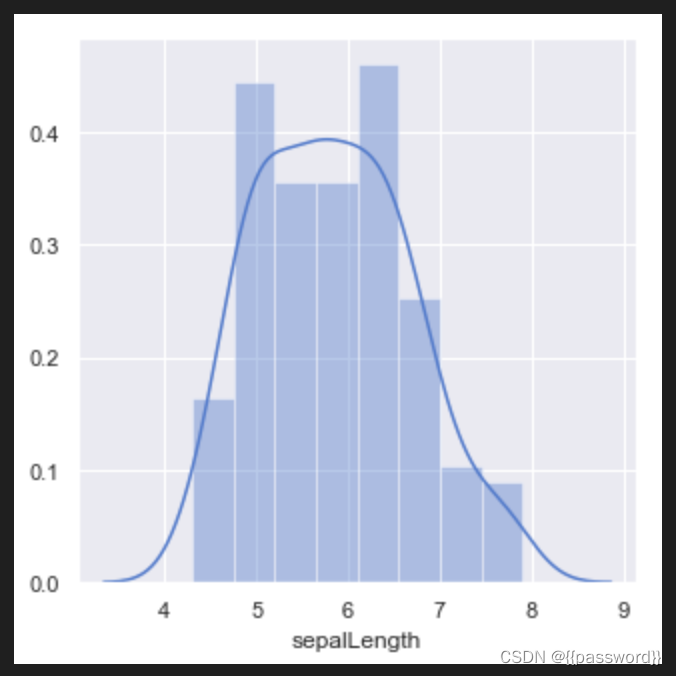
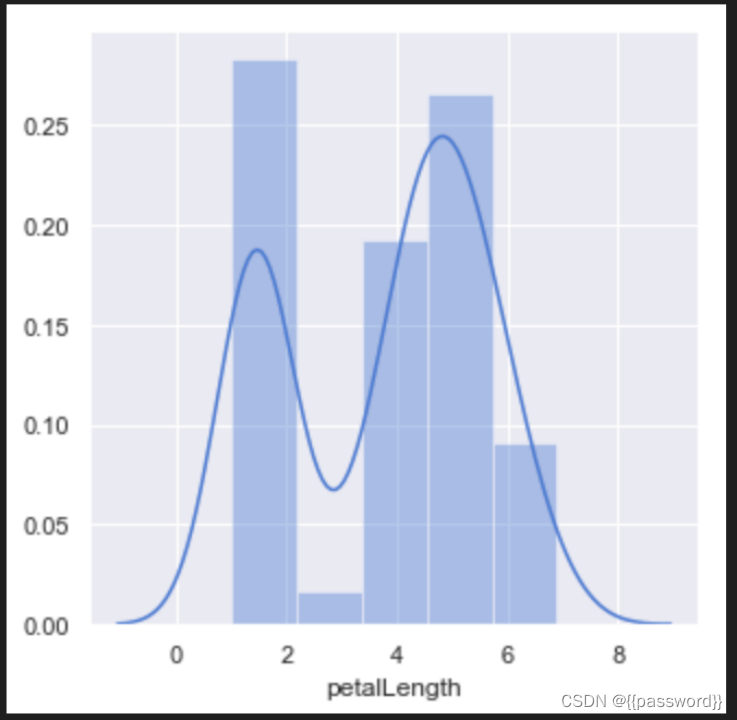
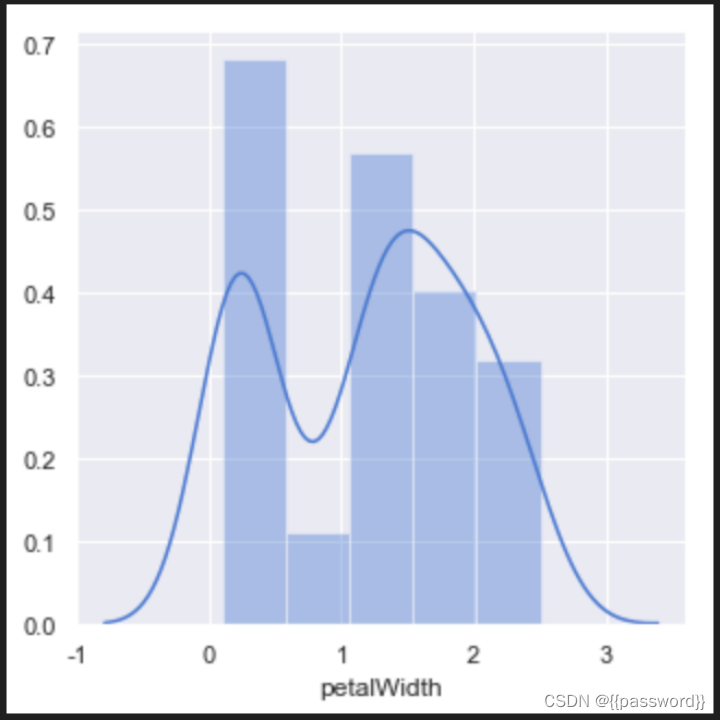
plt.figure(figsize=(5,5))
sns.set(style='darkgrid',palette='muted',color_codes=True)
sns.distplot(data[data['sepalLength'].notnull()]['sepalLength'])
2、数据基本处理
2.1缺失值、异常值处理
# 查看缺失值
data.isnull().sum()
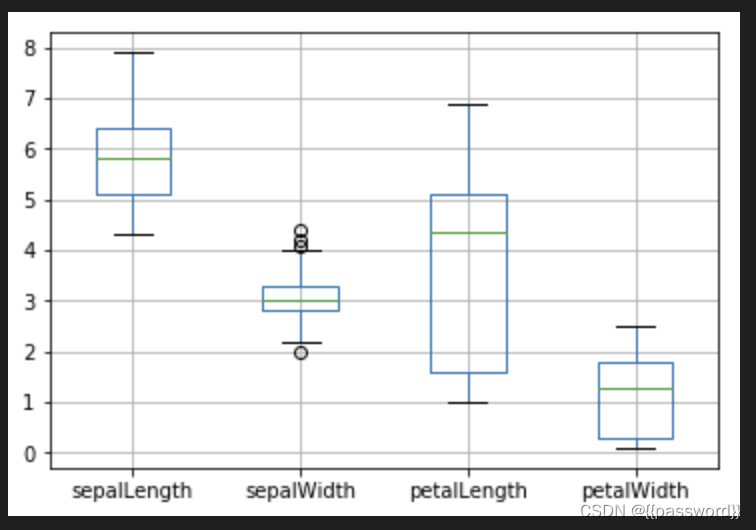
# 查看异常值
data.boxplot(column=['sepalLength','sepalWidth','petalLength','petalWidth'])
2.2变量独特率检测
# 查看数据独特值
data.nunique()

2.3变量相关度处理
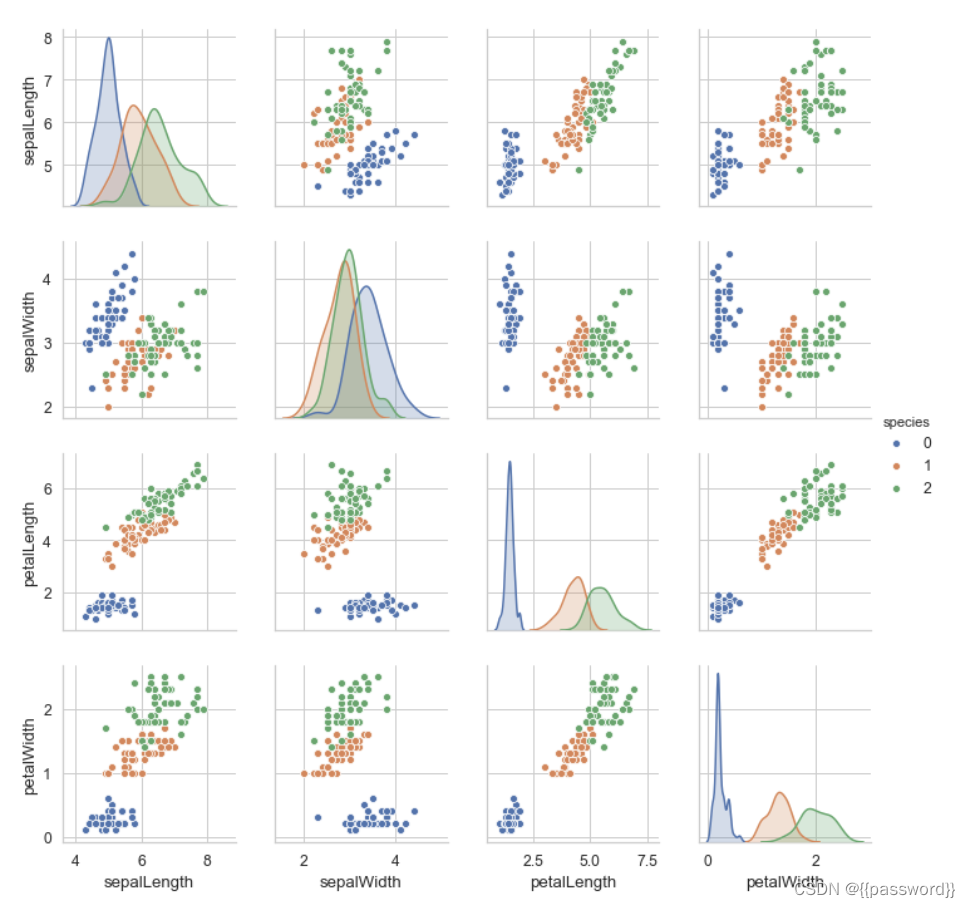
#相关矩阵
pd.set_option('precision',2)
sns.set(font_scale=1.1)
sns.set_style('whitegrid')
grid=sns.pairplot(data,vars=data.columns[0:4],hue='species')
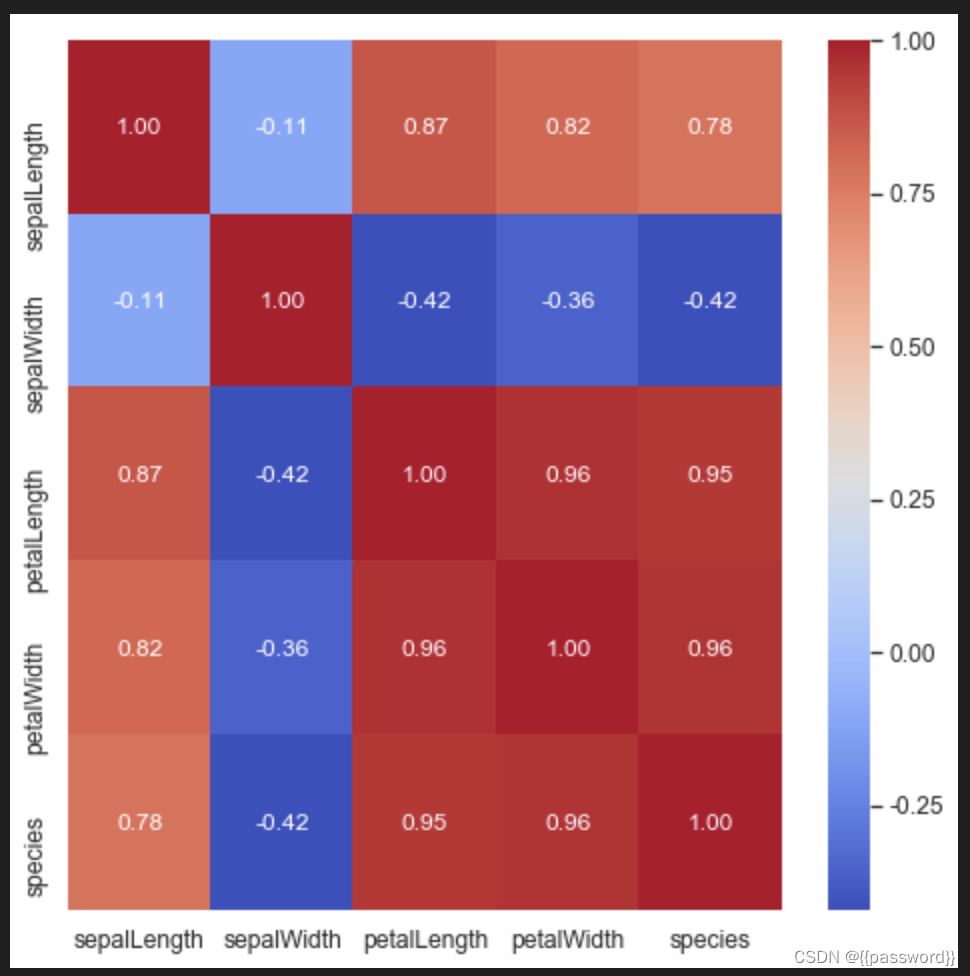
#热力图
plt.figure(figsize=(8,8))
# sns.heatmap(x.corr(),linewidths=0.1,cmap=sns.diverging_palette(20,220,n=220),square=True,vmin=-1,vmax=1,annot=True,cbar=True)
sns.heatmap(data.corr(),annot=True,cmap="coolwarm",fmt='.2f',annot_kws={'size':12})
plt.show()
2.4one-hot(独热编码)
3、特征工程
3.1特征提取(特征重要性分析)
from sklearn.feature_selection import VarianceThreshold
sel_model=VarianceThreshold()
featureVT=sel_model.fit_transform(x)
featureVT=pd.DataFrame(data=featureVT,columns=x.columns) #重复代码 feature_VT=feature_MinMax
var=sel_model.variances_
col=zip(featureVT,var) #把feature和var进行配对
var_data=pd.DataFrame(data=list(col),columns=['feature','var'])
var_data_sort=var_data.sort_values('var') #根据var的值进行排序
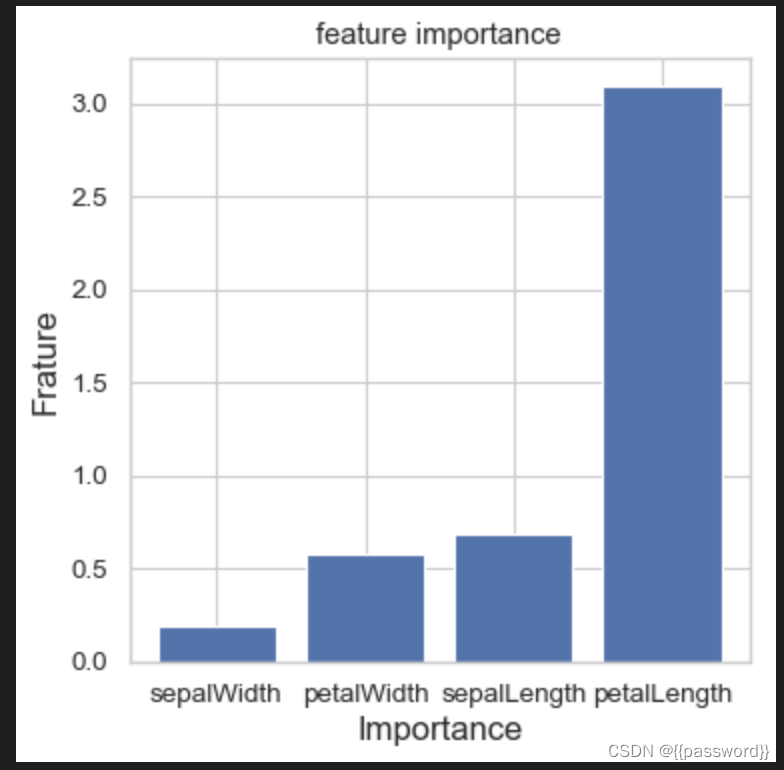
fig=plt.figure(figsize=(5,5),dpi=80)
plt.bar(var_data_sort['feature'], var_data_sort['var'])
plt.ylabel('Frature',fontsize=15)
plt.xlabel('Importance',fontsize=15)
plt.title('feature importance')
plt.show()
# 归一化
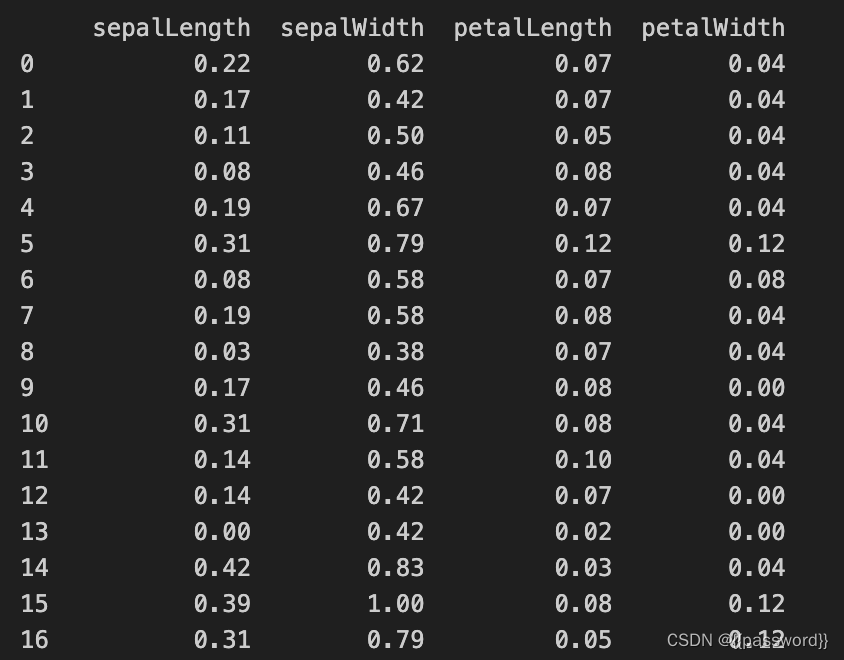
from sklearn.preprocessing import MinMaxScaler
transfer=MinMaxScaler(feature_range=(0,1))
dataX1=transfer.fit_transform(x)
dataX1=pd.DataFrame(dataX1,columns=x.columns)
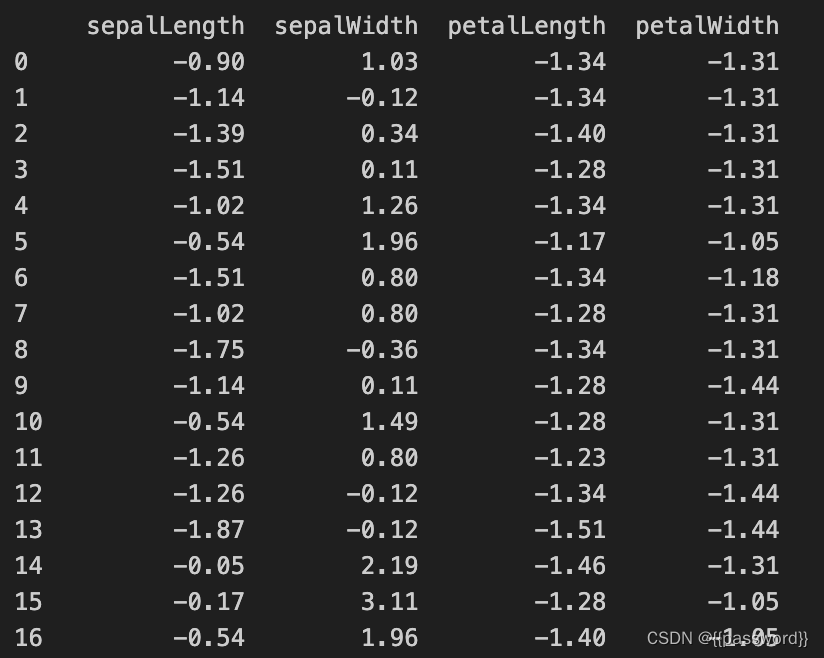
# 标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
dataX2 = scaler.fit_transform(x)
dataX2=pd.DataFrame(dataX2,columns=x.columns)
3.3特征降维
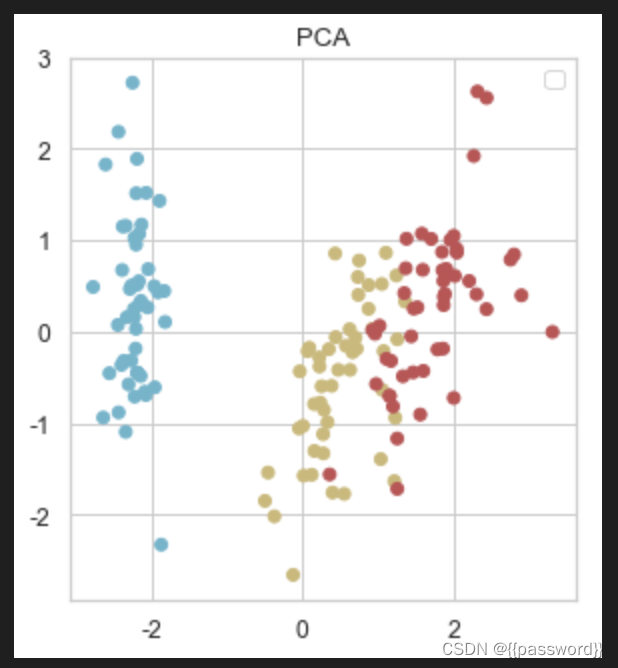
# 使用PCA主成分分析法对数据集降维并可视化
standard_x = scale(x, axis=0, with_mean=True, with_std=True)
pca = PCA(n_components = 2)
res_x = pca.fit_transform(standard_x)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(121)
colors = list()
for i in y:
if i == 0:
colors.append('c')
elif i == 1:
colors.append('y')
elif i == 2:
colors.append('r')
ax1.scatter(res_x[:,0], res_x[:,1], c=colors)
ax1.set_title('PCA')
ax1.legend()
4、机器学习
监督学习(KNN为例)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
modelKNN = KNeighborsClassifier(n_neighbors=5)
modelKNN.fit(x_train, y_train)
train_score = modelKNN.score(x_train, y_train)

5、模型评估
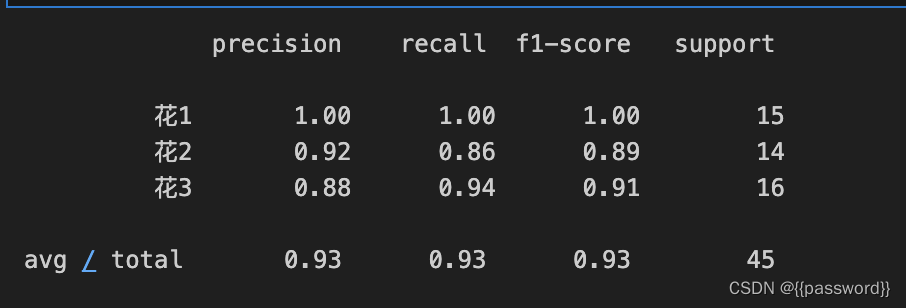
y_pre=modelKNN.predict(x_test)
ret=classification_report(y_test,y_pre,labels=(0,1,2),target_names=('花1','花2','花3'))
print(ret)
ROC曲线
from sklearn import datasets
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
TPR=[]
FPR=[]
num=4.5
for it in range(1,26):
num+=0.1
TP = 0
FN = 0
FP = 0
TN = 0
for i in range(1, 100):
if(iris.data[i][0]<=num):
if(iris.target[i]==0):
TP+=1
else:
FN+=1
else:
if(iris.target[i]==1):
TN+=1
else:
FP+=1
print(TP," ",FN," ",FP," ",TN)
TPR.append(TP/(TP+FN))
FPR.append(FP/(TN+FP))
print(TPR)
print(FPR)
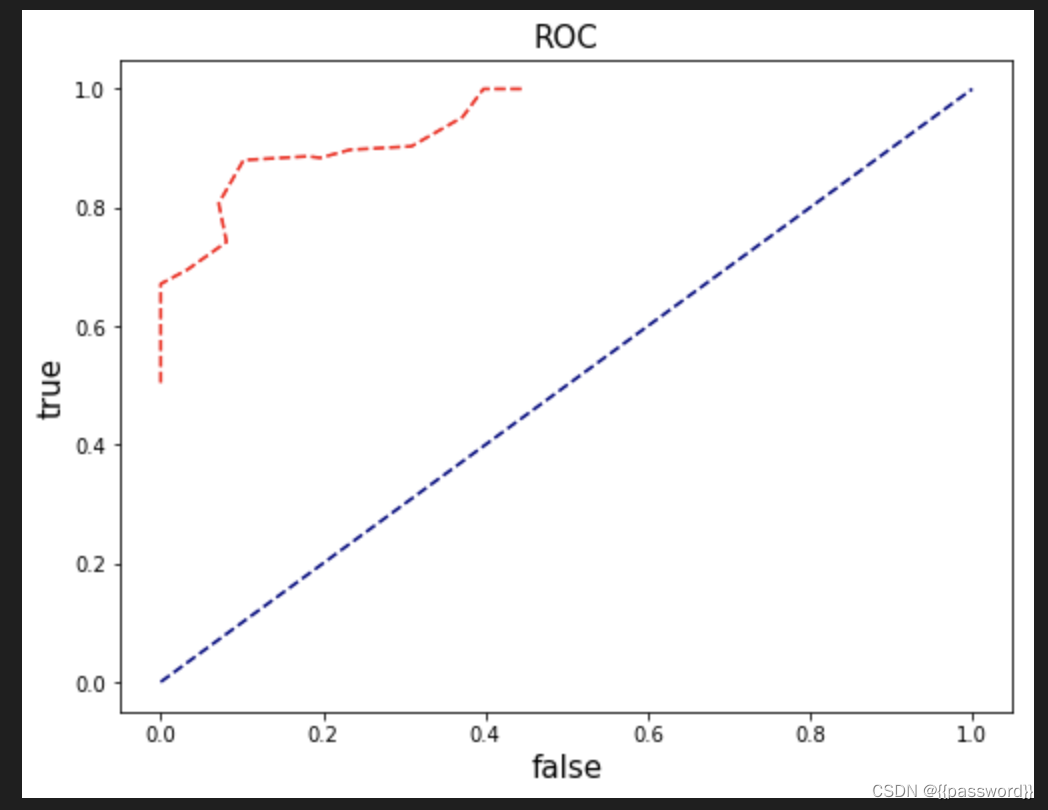
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.plot(FPR,TPR,color="red",linestyle='--')
plt.title("ROC",fontsize='15')
plt.xlabel("false",fontsize='15')
plt.ylabel("true",fontsize='15')
plt.show()















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









