







CASCADE的中文翻译为"级联"。也就是在针对HIVE不仅变更新分区的表结构(metadata),同时也变更旧分区的表结构。
在针对分区表时对表新增字段,没有使用cascade关键字,那么此时对于历史分区无论是使用insert into还是insert overwrite table 插入数据新增的列显示都是null值。
#创建表,以parquet存储格式存储
create table CASCADE_TEST.par_c(
id int ,
name string,
address string,
oa string,
ob string
)
partitioned by (day string);
STORED AS PARQUET;
#插入数据
insert into CASCADE_TEST.par_c partition(day="20230709") values (1,"tom","nanjin","0a","ob");
insert into CASCADE_TEST.par_c partition(day="20230709") values (2,"jack","hefei1","0a","ob");Parquet 是一种列式存储格式,被广泛应用于大数据处理平台,如 Hive、Impala 和 Spark 等。在 Hive 中使用 Parquet 格式可以提供高性能的查询和压缩,能够节省存储空间并提高查询效率
此时针对历史分区day=20230709,新插入的数据loc列显示的是NULL,这明显就出现了问题。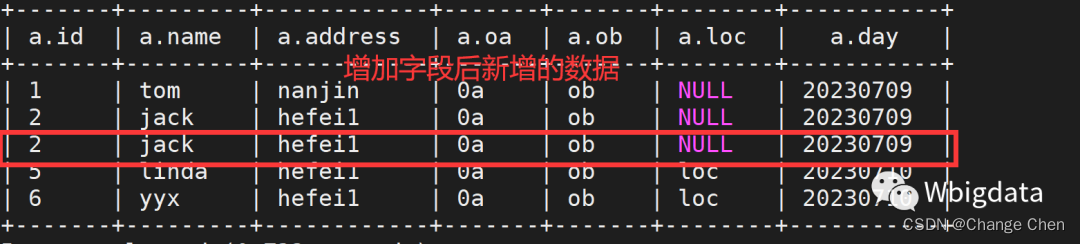
使用CASCADE关键字
下面命令的意思是以级联的方式对CASCADE_TEST.par_c表的loc列重新命名为loc2
为了列名显示正式可以使用相同的方式再修改回去
ALTER TABLE CASCADE_TEST.par_c CHANGE COLUMN loc loc2 string CASCADE;再次查询,发现NULL变成了具体插入的值了,那么问题便解决了

特别说明
如果想改变新增的列在某列之后使用after关键字即执行
ALTER TABLE CASCADE_TEST.par_c CHANGE COLUMN loc loc2 string after name CASCADE;如果存储格式是parquet格式的,那么这新增的列的数据都是null.
如果是普通文本格式则不会出现。
 textfile存储格式这种操作之后的情况:
textfile存储格式这种操作之后的情况: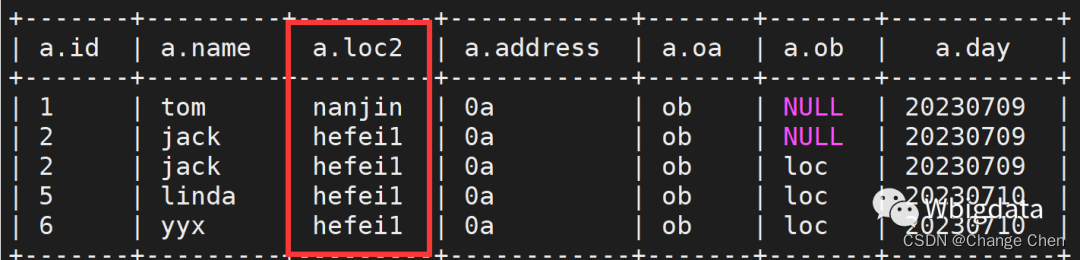
来源于:















 5387
5387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









