






“才感春来 忽而已夏🌷”


THE ROMANCE
OF SPRING

简要解释

CASCADE的中文翻译为"级联",顾名思义就是就是与之有联系的。在针对HIVE也就是不仅变更新分区的表结构(metadata),同时也变更旧分区的表结构。
接下来我们要验证这个关键字对分区表新增字段之后有什么影响?

背景说明

在生产环境中,由于用户对HIVE知识了解不深,在针对分区表时对表新增字段,没有使用cascade关键字,那么此时对于历史分区无论是使用insert into还是insert overwrite table 插入数据新增的列显示都是null值,那么如何解决?
下面是验证步骤

新增测试表以及插入数据

#创建表,以parquet存储格式存储
create table aiops.par_c(
id int , name string,address string,oa string,ob string
)
partitioned by (day string);
STORED AS PARQUET;
#插入数据
insert into aiops.par_c partition(day="20230709") values (1,"tom","nanjin","0a","ob");
insert into aiops.par_c partition(day="20230709") values (2,"jack","hefei1","0a","ob");
对分区表新增字段

#新增loc字段
alter table aiops.par_c add columns (loc string);此时对于历史分区数据loc列都是null

继续插入数据

#在新增字段之后分别向历史分区以及新分区插入数据
insert into aiops.par_c partition(day="20230709") values (2,"jack","hefei1","0a","ob","loc");
insert into aiops.par_c partition(day="20230710") values (5,"linda","hefei1","0a","ob","loc");
insert into aiops.par_c partition(day="20230710") values (6,"yyx","hefei1","0a","ob","loc");此时针对历史分区day=20230709,新插入的数据loc列显示的是MULL,这明显就出现了问题。
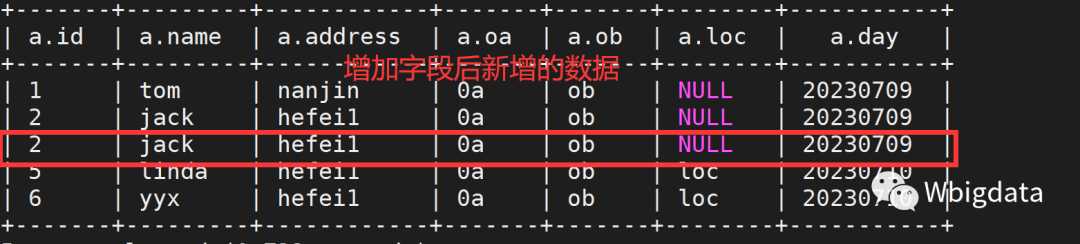

如何解决NULL值问题?

使用CASCADE关键字
下面命令的意思是以级联的方式对aiops.par_c表的loc列重新命名为loc2
为了列名显示正式可以使用相同的方式再修改回去
ALTER TABLE aiops.par_c CHANGE COLUMN loc loc2 string CASCADE;再次查询,发现NULL变成了具体插入的值了,那么问题便解决了


总结

通过比较加与不加CASCADE关键字就知道了区别了,针对分区表新增字段时不加CASCADE关键字时对于历史分区新插入的数据,那个新增的列名值都会显示为NULL反之可正常显示。
特别说明
如果想改变新增的列在某列之后使用after关键字即执行
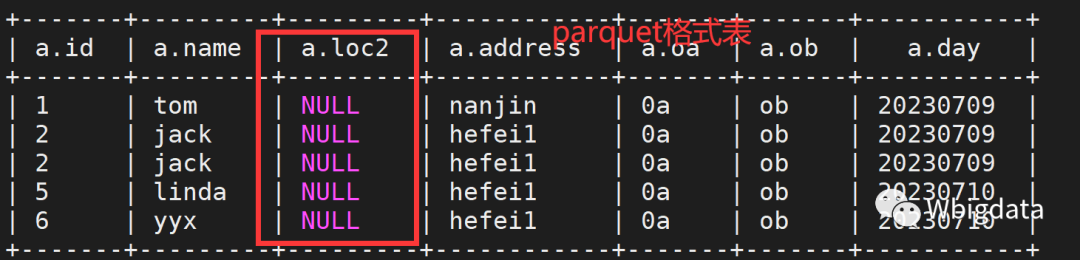
ALTER TABLE aiops.par_c CHANGE COLUMN loc loc2 string after name CASCADE;如果存储格式是parquet格式的,那么这新增的列的数据都是null,就会出现问题,如果是普通文本格式则不会出现。
parquet存储格式在这种操作之后的情况
textfile存储格式这种操作之后的情况

参考链接:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterTable/PartitionProtections

点个在看你最好看















 1725
1725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









