







 超级会员免费看
超级会员免费看
关键词库搭建+关键词自动分组
每一个关键词对应一个用户的真实需求
被动接收:系统推送
主动接收:
搜索→关键词(用户需求+精准用户群体区分)
互联网运营的目标:找到我们最佳的对标需求用户(精准用户)
关键词筛选工具
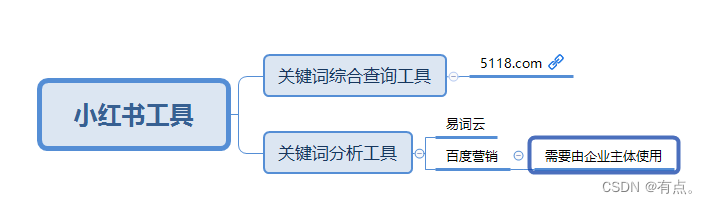
通过筛选,看你所想要涉及的领域具体方向,具体板块,倾向与哪方面延伸。
关键词搜索排名核心机制
- 搜索排名价值
- 搜索排名机制
- 搜索排名流量分配
案例
- 婴儿
- 婴儿用品推荐
- 婴儿注意事项
- 婴儿早教分享
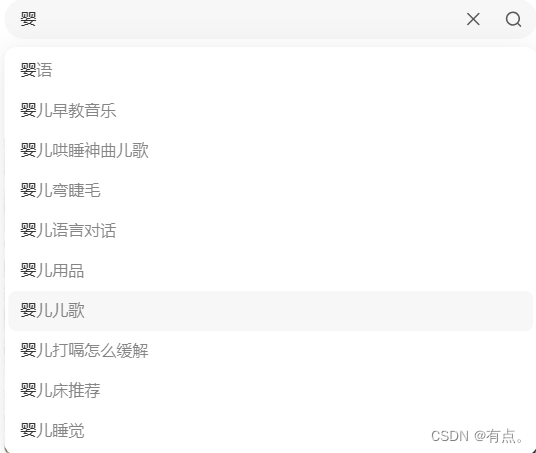
以上都是长尾词
做流量就必须要有核心词
对长尾词、产品、成交的时候就要考虑对核心词所衍生出来的产品做分类,找到专门做类似产

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











