







文献标题:参与者识别时空动作检测-检测谁在视频中做什么
源码链接:https://github.com/fandulu/ASAD
类别:Computer Vision and Pattern Recognition (cs.CV)
摘要
现存的问题:深度学习在视频动作识别(Action Recognition, AR)中的成功促使研究人员逐步将相关任务从粗粒度级别提升到细粒度级别。与传统AR仅预测整个视频的动作标签相比,时间动作检测(TAD)被用于估计视频中每个动作的开始和结束时间。在此基础上,本文进一步研究了在视频中对动作进行空间和时间定位的时空动作检测方法。然而,在SAD(时空动作检测)中,谁来执行这个动作,通常被忽略了,而识别行为者也可能很重要。为此,我们提出了一种新的任务——参与者识别的时空动作检测(ASAD),以弥合SAD与参与者识别之间的差距。
本文能实现的效果:在ASAD中,我们不仅能检测实例级别的动作的时空边界,而且为每个参与者分配唯一的ID。多目标跟踪(MOT)和动作分类(AC)是实现ASAD的两个基本要素。通过使用MOT,得到每个参与者的时空边界,并赋予一个唯一的参与者身份。通过AC,在相应的时空边界内估计动作类。
本文存在的问题:由于ASAD是一个新的任务,它提出了许多现有方法无法解决的新挑战:i)没有专门为ASAD创建的数据集,ii)没有为ASAD设计的评估指标,iii)现存的MOT方法的性能可能无法获得满意的ASAD结果。
本文针对问题提出的方法:为了解决这些问题,我们提出了一种新的ASAD数据集的标注方法,提出了考虑多标签行为和参与者识别的ASAD评价指标,改进了MOT中的数据关联策略,以提高MOT性能,从而获得更好的ASAD结果。我们认为,将参与者识别与时空动作检测相结合,可以促进视频理解等领域的研究。
该代码可在https://github.com/fandulu/ASAD获得。
关键词:动作识别,多目标跟踪
1.介绍
基于视觉的动作识别的应用价值:基于视觉的动作识别(Vision-based Action Recognition, AR)旨在从一系列数据(如视频)中检测出人类定义的动作,在我们的日常生活中有着广泛的应用。例如,它被应用于YouTube识别数十亿个视频标签,然后向我们推荐视频,或者被应用于警察快速从数千小时的监控视频中检索罪犯,或者被应用于虚拟游戏机与玩家互动,等等([10,33])。
传统的AR与提出的ASAD的区别:近年来,基于增强现实的深度学习的成功促使研究人员逐步将增强现实任务从粗粒度级别提升到细粒度级别。与传统AR仅预测整个视频的动作标签相比,时间动作检测(TAD)被用于估计视频中每个动作的开始和结束时间。在此基础上,本文进一步研究了在视频中对动作进行空间和时间定位的时空动作检测方法。然而,在SAD研究中,谁来执行这个动作通常被忽略。我们认为参与者认同应该与SAD一起考虑。当目标场景中有多个参与者时(如篮球/足球比赛),我们更希望知道“谁在做什么”,因此,我们希望通过每个参与者的动作来识别他们。但是,长期以来,SAD和行动者识别被视为不同的任务。为此,我们提出了一种新的任务——参与者识别时空动作检测(ASAD),以弥合SAD和参与者识别之间的差距(图1)。
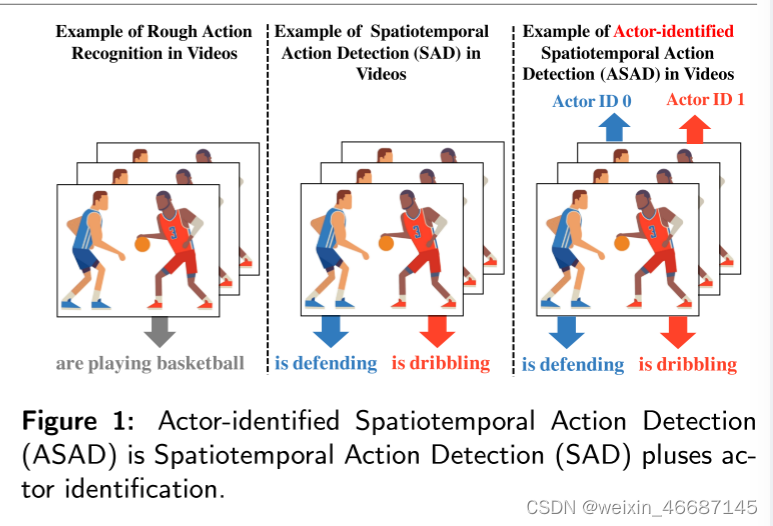
为了实现ASAD,多目标跟踪(Multiple Object Tracking, MOT)[49]和动作分类(Action Classification, AC)[33]是两个基本元素(图2)。通过使用MOT,获得每个参与者的时空边界,并将其分配给一个唯一的参与者标识。通过AC,在相应的时空边界内估计动作类。一般情况下,考虑到模型训练的灵活性,它们可以作为独立的模块工作。
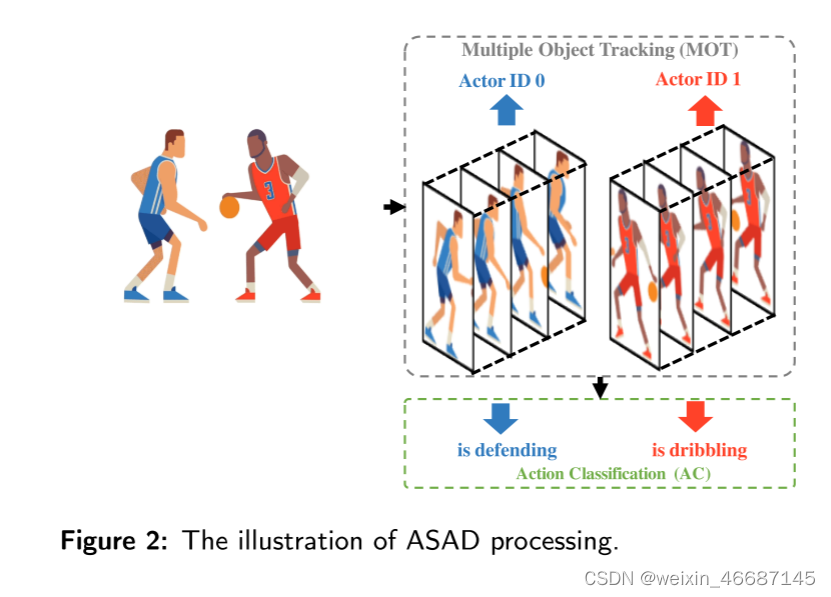
由于ASAD是一个新的任务,它提出了许多现有方法无法解决的新挑战:i)没有专门为ASAD创建数据集,ii)没有为ASAD设计评估指标,iii) 现存的MOT方法的性能可能无法获得满意的ASAD结果。为了解决这些问题,我们提出了一种新的ASAD数据集的标注方法,提出了考虑多标签行为和参与者识别的ASAD评价指标,改进了MOT中的数据关联策略,提高了MOT性能,从而得到了更好的ASAD结果1。
我们总结了主要的贡献如下:
•我们提出了一项新的视频动作识别研究任务——参与者识别时空动作检测(ASAD)。据我们所知,这一问题非常重要,但在历史上一直被忽视。ASAD弥合了现有的时空行为检测(SAD)研究与识别行为实施者之间的差距。
•我们专门为ASAD研究提供了一个新的数据集。它涵盖了丰富的动作类别和参与者身份。
•我们提出了ASAD评估的新指标。据我们所知,现有的度量标准不能应用于ASAD,我们是第一个引入这种度量标准的。
2.相关工作(原文无内容)
3.视频动作识别
现有的视频动作识别研究:一般来说,视频动作识别研究可以分为几个类别(图3)。常规的动作识别(AR)以整个视频或视频剪辑为输入,生成相应的动作类。它被用来理解整体的视频概念,而不是在空间域和时间域上指定细节。时间动作检测(TAD)通过明确动作的开始和结束时间,为AR提供时间细节。据此,在TAD中可以将一个视频分割成多个时间分量。与TAD相比,时空动作检测(spatial - temporal Action Detection, SAD)不仅能在时间域内检测动作边界,还能在空间域内通过box框(或实例mask)定位动作主体。我们通常把这样的时空边界称为行为流管。在本研究中,我们提出了一种基于参与者识别的时空动作检测方法(ASAD)。
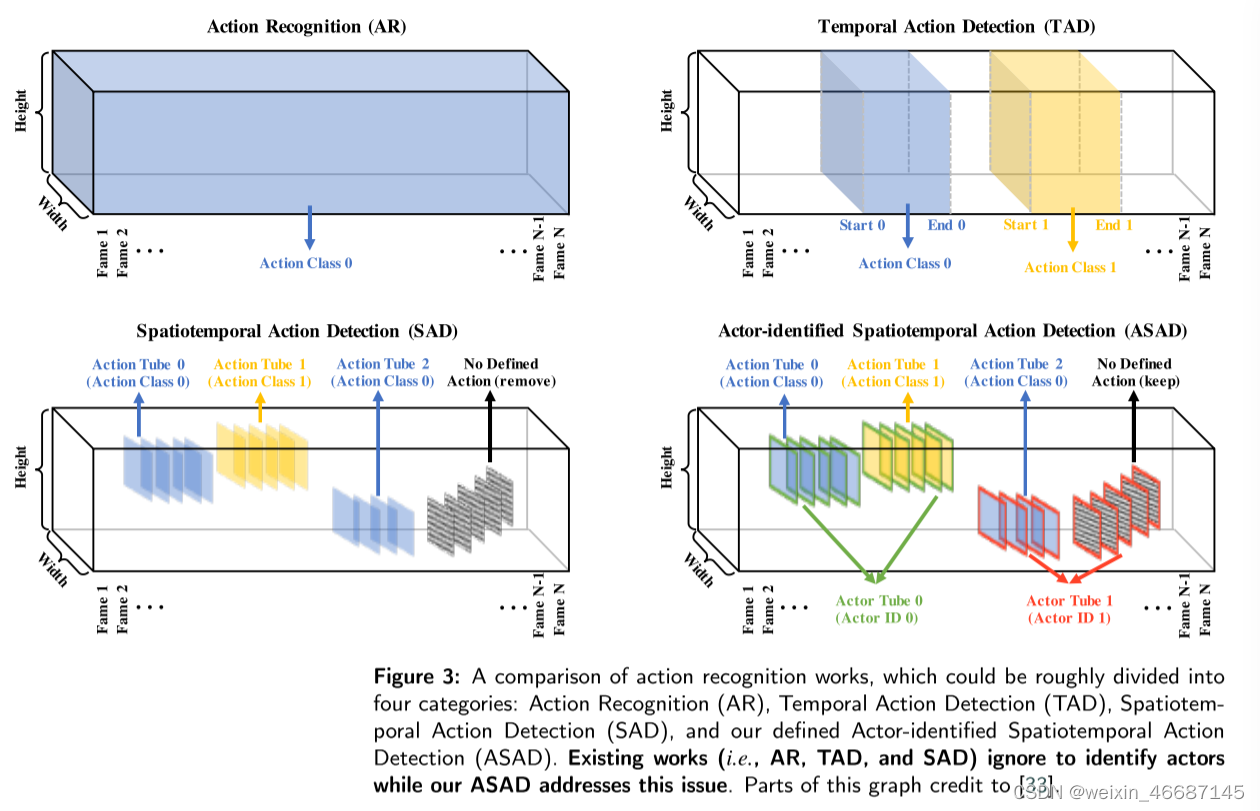
图3:动作识别工作的比较,大致可以分为四类:动作识别(AR)、时间动作检测(TAD)、时空动作检测(SAD)和我们定义的参与者识别的时空动作检测(ASAD)。现有的工作(如AR、TAD和SAD)忽略了参与者,而我们的ASAD解决了这个问题。这张图的一部分归功于[33]。
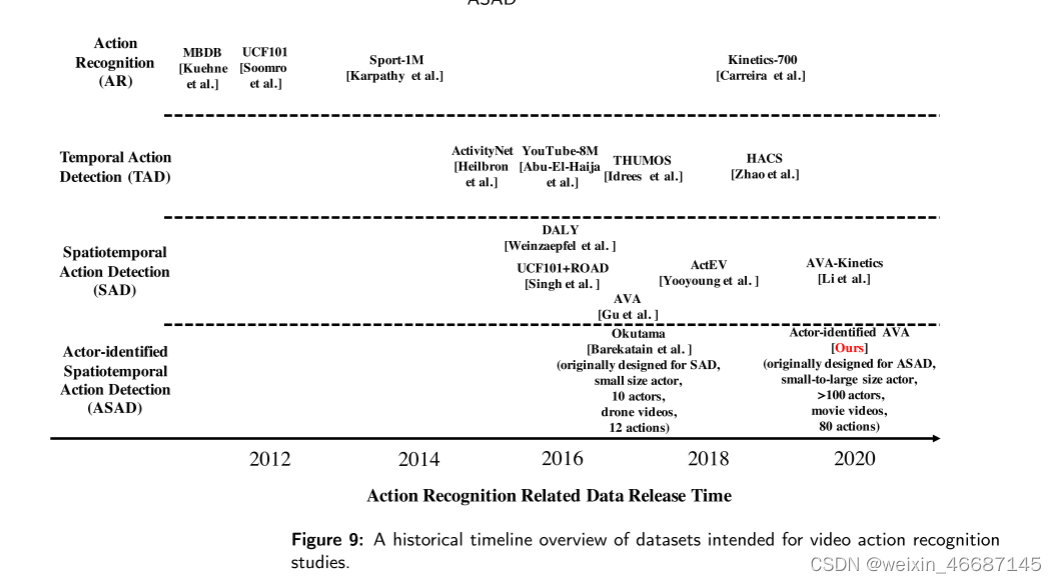
数据集的区别:我们在表1中总结了AR、TAD、SAD和ASAD的相关数据集和研究。多目标跟踪(Multiple Object Tracking, MOT)[82]也是SAD中常用的一种方法,将box框与行为流管连接起来。一些SAD作品还可以跟踪参与者,并为他们分配唯一的id。但是,基于SAD的评价协议,可能没有提供参与者身份的标注,也没有对参与者身份进行评价。也就是说,ASAD和SAD在方法上没有明确的界限,它们的区别更多的是在数据标注和评估协议上。SAD中给出的行为流管ID与参与者ID可能并非始终保持不一致。例如,在同一个参与者改变了他/她的动作后,相应的行为流管ID改变了,但参与者ID应该保持不变。不幸的是,这种参与者ID在大多数SAD数据集中是不可用的。
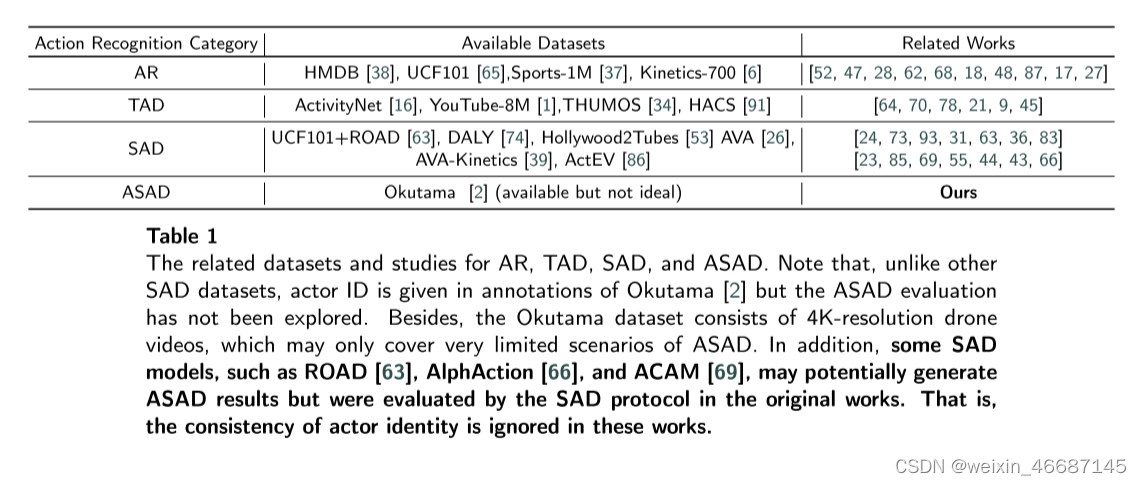
表1 AR、TAD、SAD、ASAD的相关数据集和研究。请注意,与其他SAD数据集不同,Okutama[2]的注释中给出了参与者ID,但ASAD评估尚未被探索。此外,Okutama数据集包含4k分辨率的无人机视频,可能只覆盖非常有限的ASAD场景。此外,一些SAD模型如ROAD[63]、AlphAction[66]、ACAM[69]可能会产生ASAD结果,但在原著中均采用SAD协议进行了评估。也就是说,这些作品忽略了参与者身份的一致性。
MOT和AC的重要性:假设MOT和AC是ASAD中的两个重要组成部分,我们来看看MOT和AC在AR、TAD、SAD和ASAD中的作用(见表3)。AC是所有动作识别类别的必要模块。在SAD中,可以使用MOT(例如,在UCF101 + ROAD数据集上[63]),但不是必需的(例如,在AVA数据集[26]上)。然而,在ASAD中,MOT和AC都是需要的。
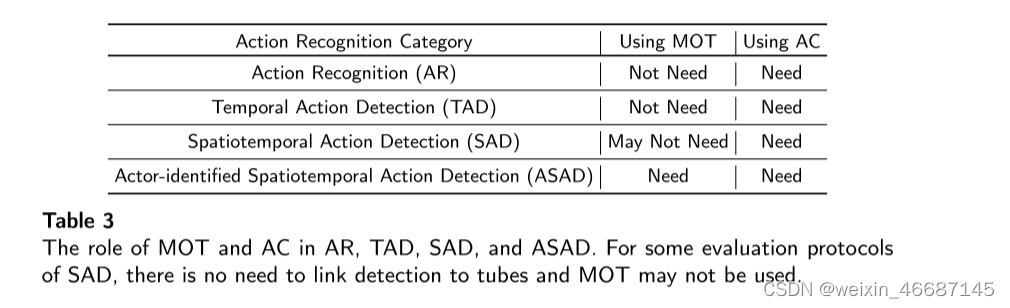
此外,以往的研究[60,79,32]只关注识别视频中的参与者,而没有识别他们的行为。这样,作为一项新的任务,ASAD在SAD和参与者识别之间架起了桥梁(表2)。

4.多目标跟踪
鉴于多目标跟踪(MOT)在参与者识别的时空动作检测(ASAD)中发挥着重要作用,本文进一步综述了多目标跟踪的相关工作。
一般来说,MOT是根据MOT特征的相似性将相同的观测数据连接成轨迹。具体来说,MOT方法可分为在线MOT和离线MOT两类(表4)。在线数据关联在处理每一帧时,只使用直到当前帧为止已经获取到的观测信息,以进行目标的关联和跟踪。与在线方法不同,离线数据关联考虑了全局观测数据,需要考虑到完整的数据,可能不适用于实时应用,但对于辅助标注工作是理想的。在之前的研究[49]中已经提出了许多离线方法。其中,将MOT数据关联构建为全局聚类问题取得了很大的成功[81]。

5.行为分类
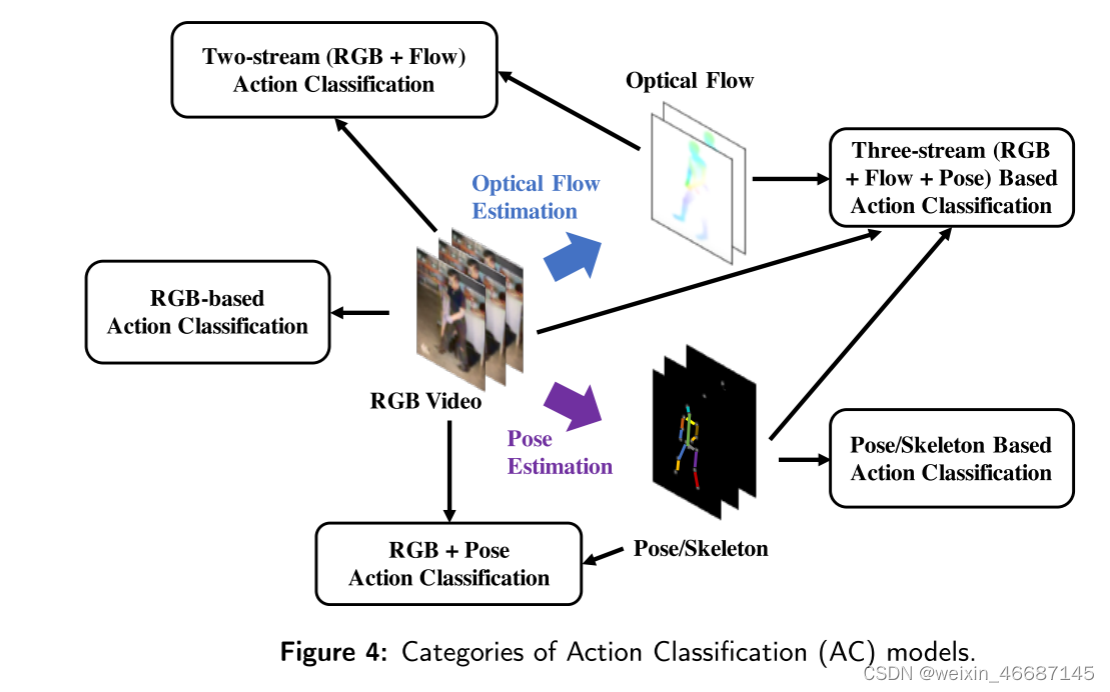
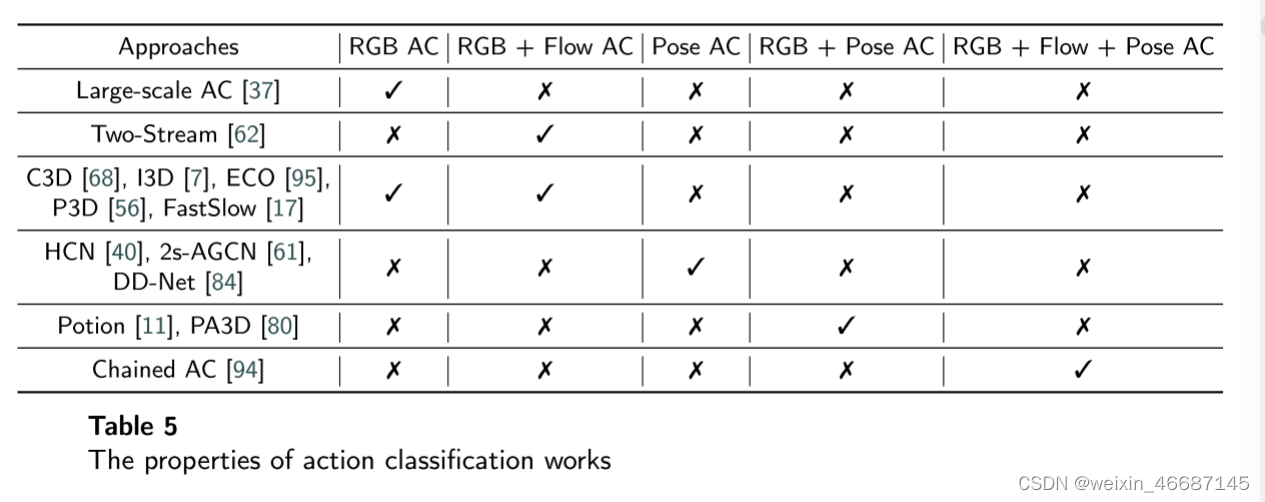
行为分类(Action Classification, AC)模型就是这样一个将时空信息映射到动作类别的模型。许多研究都考虑了利用特征和设计模型结构的方法。其中,行为分类 (AC)方法可分为RGB AC、RGB + Flow AC、Pose AC、RGB + Pose AC、RGB + Flow + Pose AC 5类,如图4所示。基于这5个类别,我们在表5中列出了相应的研究。
6. 提出的ASAD数据集和评估指标
给定一个视频,参与者识别时空动作检测 (ASAD)的目标是检测每个参与者的时空边界(即tracklets/actor tubes),为每个参与者分配一个唯一的身份,获取参与者在每个时刻的动作。因此,ASAD数据集应该包括这些因素,ASAD指标应该验证这些因素的性能。
6.1.ASAD数据集
通过回顾现有的动作识别数据集(第2节),可以注意到一个适当的ASAD数据集可能是不可用的。尽管现有的Spatiotemporal Action Detection (SAD)数据集可能与我们想要的ASAD数据集相似,但在SAD数据集中参与者身份没有被正确地注释。我们以UCF101+ROAD数据集[63]和AVA数据集[26]为例,说明SAD和ASAD数据标注的差异(图5和图6)。UCF101+ROAD数据集中,时空边界是不完整的。由于角色识别不是SAD关注的问题,在预定义的动作完成后,时空标注是不可用的。而ASAD中的标注则需要完成整个视频中每个参与者的时空边界,无论所定义的动作是否完成。在AVA数据集中,尽管给出了参与者id,但在一个视频中为同一个参与者分配了多个参与者id,这对于参与者标识来说是不正确的。出于参与者标识的目的,应该为一段视频中的每个参与者分配唯一的参与者ID。此外,虽然一些远程监控视频数据集具有时空边界、角色身份和角色类,但它们集中于特殊场景(如远程监控),可能不适用于一般的ASAD研究。例如Okutama数据集[2]和PANDA[71]只记录了很小规模的演员,覆盖了一小群人类的日常活动。
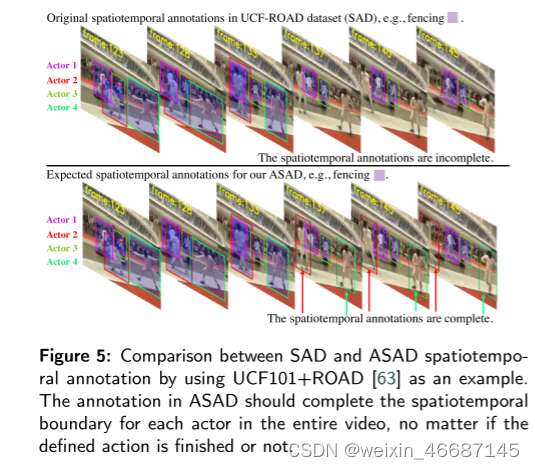

图6:以AVA[26]为例,比较SAD和ASAD参与者ID标注。在单个视频中,现有的SAD数据集可以为同一个参与者分配多个参与者ID,而我们的ASAD为参与者分配唯一的参与者ID。
由于上述原因,我们有动机对新的ASAD数据集进行注释。与SAD数据集相比,ASAD数据集需要添加正确的参与者身份。由于AVA数据集[26]是一个规范SAD数据集,而TAO数据集[14]提供了一些参与者身份标注,所以我们选择了AVA数据集的一部分作为ASAD数据集(图7)。注意,我们主要选择了有可见参与者和多个参与者可用的视频剪辑。同时,由于繁重的标注成本,在430个AVA视频剪辑中只选择了77个。我们将我们的ASAD数据集命名为A-AVA,它表示参与者识别的AVA数据集。A-AVA数据集包含47个训练视频和30个测试视频。和AVA数据集一样,A-AVA数据集有80个动作类别,每25帧(约1秒)给出一次注释。在A-AVA数据集中,时空边界、参与者身份和相应的动作都被标注。图8展示了更多示例。

我们在图9中展示了我们的A-AVA数据集的历史角色。作为专门为ASAD研究设计的第一个数据集,A-AVA数据集涵盖了丰富的视频场景,如室内和室外、一天中的不同时间、各种参与者尺度等。这些属性在之前的数据集(即Okutama数据集)中是不可用的。AAVA数据集弥补了SAD数据集和参与者识别数据集之间的差距。
6.2.ASAD的评估指标
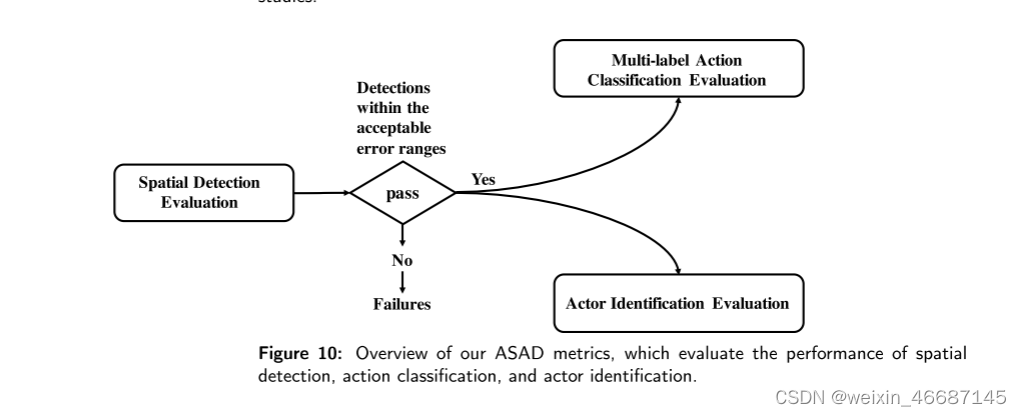
当考虑多标签行为时,ASAD评估可能是一个复杂的任务。与单标签SAD评价[25]不同,利用空间检测同时评价多标签动作分类和行动者识别具有挑战性。为了解决这一问题,我们建议从三个方面来评估ASAD,然后考虑其整体性能。这三个方面包括空间检测评价、参与者识别评价和多标签行为分类评价(图10)。
7. 实验
7.1. ASAD Framework
7.2. Experiment Results
7.3.讨论
为什么离线MOT在我们的A-AVA数据集中在参与者识别方面有更好的性能?对于静态摄像机记录,运动一致性是数据关联的一个重要线索。相反,对于非静态摄像机记录,运动一致性假设可能会失败。当视频中的视角突然改变时,追踪参与者的正确身份是一项挑战。这个问题在电影和电话录制的视频中经常发生(图13)。大多数在线MOT方法(如[77])可能会过度依赖运动一致性,从而导致我们的A-AVA数据集出现故障。使用离线MOT通过更多地根据观察结果的外观相似性来确定它们之间的对应关系,从而缓解了这个问题。此外,离线MOT解决方案利用全局信息进一步减少ID切换,并生成鲁棒的参与者识别结果。
8.总结
本文提出了一种新的任务——参与者识别时空动作检测(ASAD),它标志着计算机视觉领域首次联合研究时空边界、参与者身份和相应动作。ASAD非常适合包含多个角色的动作识别应用程序,如人机交互、篮球/足球比赛和杂货店操作监控等。为了研究ASAD,我们很高兴能够提供相应的a - ava数据集。作为第一个专门为ASAD研究设计的数据集,A-AVA数据集已经在SAD数据集和参与者识别数据集之间架起了桥梁。我们还提出了考虑多标签行为和参与者识别的ASAD评估指标。这是在ASAD如此复杂的任务中第一个评估指标。
除了上述成功之外,值得注意的是,我们的ASAD研究也存在一些局限性:
•考虑到较高的标注成本,我们提出的ASADdataset的规模仍然相对较小。同时,由于动作标签的定义可能不明确,所以动作注释可能不准确。例如,在连续时间域中很难判断“走”与“跑”的边界。或者,如果不包含音频信息,就很难判断是谁在说话。这些问题可能会影响ASAD研究。为了解决这个问题,有必要使用更多的注释器来执行高质量的注释。
•因为评估ASAD结果是复杂的,我们分别评估了空间检测、参与者识别和多标签动作分类。因此,ASAD的总体性能由多个度量值表示。然而,在理想的情况下,我们希望使用一个单一的度量值来代表整个ASAD性能。考虑到我们的每一个ASAD度量(例如,HL@0.5)都是从一个复杂的公式中获得的,将它们集成到一个单一的度量值是具有挑战性的。为了找到解决办法,需要进一步的探索。由于我们在ASAD任务中提出了这个问题,所以在以后的工作中可能会得到解决。
我们正在考虑在未来的工作中解决这些问题。
这篇论文不是结束,而是开始的步骤,我们很高兴能与研究界合作,更深入地探索ASAD。我们认为,将参与者识别与时空动作检测相结合,可以促进视频理解等领域的研究。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









