






摘要
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但难以捕获全局表示。在visual transformer中,级联的自注意模块可以捕获长距离的特性依赖关系,但不幸的是会恶化本地特性细节。在本文中,我们提出了一种混合网络结构,称为Conformer,以利用卷积操作和自注意机制来增强表示学习。Conformer起源于特征耦合单元(Feature Coupling Unit, FCU),它以交互方式融合不同分辨率下的局部特征和全局表示。Conformer采用并行结构,最大限度地保留了局部特征和全局表示。实验表明,在相似的参数复杂度下,Conformer比visual transformer (DeiT-B)在ImageNet上的性能提高了2.3%。在MSCOCO上,它在对象检测和实例分割方面分别优于ResNet-101的3.7%和mAPs的3.6%,显示了成为通用骨干网的巨大潜力。代码可以在github.com/pengzhiliang/Conformer上找到。
1.介绍
卷积神经网络(Convolutional neural networks, CNNs)[29,37,40,19,48,22]具有显著的先进的计算机视觉任务,如图像分类、目标检测和实例分割。这在很大程度上归功于卷积操作,它以一种分层的方式收集局部特征,作为强大的图像表示。尽管cnn在局部特征提取上具有优势,但它难以捕获全局表示,例如视觉元素之间的远程关系,这往往是高级计算机视觉任务的关键。一个直观的解决方案是扩大接受域,但这可能需要更密集但有损害的池化操作。
最近,transformer架构[42]已经被引入到视觉任务中[16,47,41,51,8,9,3,55,28]。ViT方法[16]通过将每个图像分割成具有位置嵌入的小块来构造一个标记序列,并应用级联transformer块提取参数化向量作为视觉表示。由于自注意机制和多层感知器(Multilayer Perceptron, MLP)结构,visual transformer反映了复杂的空间变换和长距离特征依赖,构成全局表示。不幸的是,观察到visual transformer忽略了局部特征细节,从而降低了背景和前景之间的可分辨性,如图1(c)和(g)所示。改进的visual transformer[16,51]提出了一个标记化模块或利用CNN特征图作为输入标记来捕获特征邻近信息。然而,如何精确地将局部特征和全局表示相互嵌入(embed local features and global representations)的问题仍然存在。
本文提出一种Conformer的双重网络结构(a dual network structure),旨在将基于CNN的局部特征与基于Transformer的全局表示相结合,以增强表示学习。Conformer由CNN和Transformer分支组成,分别遵循ResNet和ViT的设计,这两个分支形成了local convolution blocks,自注意力模块和MLP的组合。在训练期间,使用交叉熵损失函数用于监督CNN和Transformer分支,以耦合CNN-style和Transformer-style特征。考虑到CNN和Transformer之间的特征错位(feature misalignment),特征耦合单元Feature Coupling Unit(FCU)被设计为bridge,一方面为了融合这两种风格特征,FCU利用1x1卷积来对齐通道尺寸,利用向上/向下采样策略来对齐分辨率,利用LN,BN对齐特征值。另一方面,由于CNN和Transformer分支倾向于捕获不同级别的特征(例如,global和local),因此FCU被插入到每个块中,以交互方式连续消除它们之间的语义差异,这样的融合过程可以大大增强局部特征的全局感知能力和全局表示的局部细节。
Conformer在耦合局部特征和全局表示方面的能力如图1所示,虽然传统CNN倾向于保留有区别的局部区域(如孔雀的头部和尾部),但Conformer的CNN分支可以激活整个对象范围,如图1b和f,当仅使用visual transformer时,对于较弱的局部特征(例如,模糊的对象边界)很难区分对象和背景,如图1c和g,局部特征和全局特征的耦合显著增强了基于Transformer特征的可分辨率,如图1d和h。

贡献:
•我们提出了一种双网络结构,称为Conformer,它在最大程度上保留了局部特征和全局表示。
•我们提出了特征耦合单元(Feature Coupling Unit, FCU),以交互方式将卷积局部特征与基于transformer的全局表示相融合。
•在相当复杂的参数下,Conformer优于cnn和vision transformer的显著优势。Conformer继承了cnn和visual transformer的结构和泛化优势,显示了成为通用骨干网的巨大潜力。
2.相关工作
CNNs with Global Cues
在深度学习时代,CNN可以被视为具有不同感受野的局部特征的层次集合. 不幸的是,大多数CNN擅长提取局部特征,但难以捕获全局线索。为了缓解这种限制,一种解决方案是通过引入更深的体系结构和更多的池化操作来接收更大的感受野。空洞卷积增加了采样步长,而可形变卷积学习了采样位置。SENet和GENet建议使用全局平均池化聚合全局上下文,然后使用它来重新加权特征通道,而CBAM分别使用全局最大池化和全局平均池化在空间和通道维度上独立地细化特征。
另一个解决方案是全局注意力机制,它在NLP中捕获远程依赖方面显示出巨大优势。使用non-local means(非局部均值降噪)方法的启发,以自注意力的方式将局部运算引入到CNN中,以使得每个位置的响应是全局位置特征的加权求和。特征增强局部网络将卷积特征映射域自注意力特征串联起来,以增强卷积操作以捕获远程交互。Relation Networks提出一个对象注意模块,该模块通过一组对象的外观特征和几何特征之间的交互来同时处理这些对象。
尽管取得了进展,但现有的将全局索引入cnn的解决方案有明显的缺点。对于第一种解决方案,更大的接收域需要更密集的池化操作,这意味着更低的空间分辨率。对于第二种解决方案,如果卷积操作没有与注意力机制正确融合,局部特征细节可能会恶化。
Visual Transformer
作为一项开创性的工作,ViT[16]验证了纯transformer架构用于计算机视觉任务的可行性。为了利用长距离依赖关系,transformer块作为独立架构或被引入cnn用于图像分类[47,41,51]、目标检测[8,58,3]、语义分割[55]、图像增强[9]、弱监督目标定位[17]和图像生成[11,28]。然而,视visual transformer中的自注意机制常常忽略局部特征细节。为了解决这一问题,DeiT[41]提出使用蒸馏令牌将基于cnn的特征传递到visual transformer,而T2T-ViT[51]提出使用令牌化模块将图像递归地重组为考虑邻近像素的令牌。在目标检测中,DETR方法[8,58]将CNN提取的局部特征馈入transformer的编解码器,以串行方式对特征之间的全局关系进行建模。
与现有的作品不同,Conformer定义了第一个以交互方式融合特征的并发网络结构。这种结构既自然地继承了CNN和transformer的结构优势,又最大限度地保留了局部特征和全局表示的表示能力。
3.Conformer
3.1概述
局部特征及其描述符,是局部图像邻域的紧凑向量表示,已成为许多计算机视觉算法的构建模块。全局表示包括,但不限于轮廓表示、形状描述符和长距离的目标拓扑结构。在深度学习中,CNN 通过卷积运算以层级方式收集局部特征,并将局部线索保留为特征图。而 visual transformer 被认为通过级联的自注意力模块以一种 soft 的方式聚合 压缩patch embeddings (ViT Patch Embedding理解_YoJayC的博客-CSDN博客)之间的全局表示。
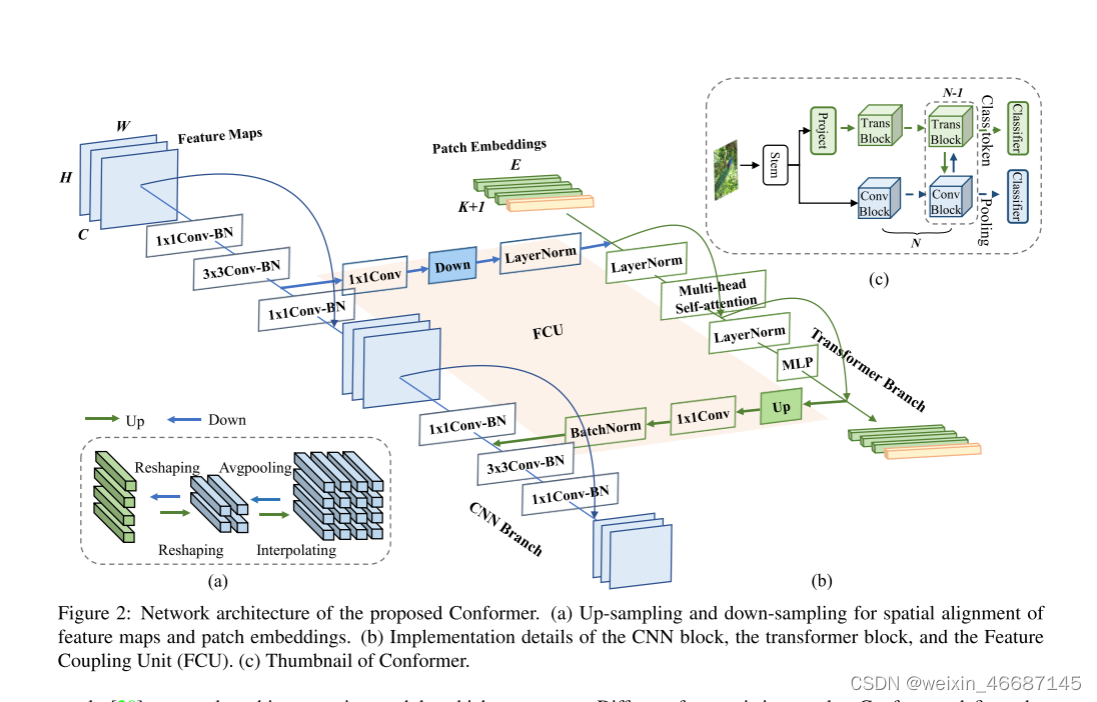
为了利用局部特征和全局表示,本文设计了一个并发 (concurrent) 网络结构,如 Figure 2 (c) 所示,称为 Conformer。考虑到两种风格特征的互补性,在Conform内部,将 transformer分支的全局 上下文信息连续馈送到 CNN 特征图,以加强 CNN 分支的全局感知能力。类似地,来自 CNN 分支的局部特征逐渐反馈到 patch embeddings,以丰富 transformer 分支的局部细节。这样的过程构成了交互作用。(就是加上一个分支路径,让特征信息交替地经过CNN 和 transformer 两个分支)

具体地,Conformer 由一个 stem 模块(主要用于下采样)、双分支、桥接双分支的 FCU 、和用于双分支的两个分类器(一个 fc 层)组成。stem 模块是一个 7×7 卷积,步长为 2,然后是一个 3×3 最大池化,步长为 2,用于提取初始局部特征(例如,边缘和纹理信息),然后将其馈送到双分支。CNN 分支和 transformer 分支分别由 N 个(例如 12)个重复的卷积 block 和 transformer block 组成,如 Table 1 中所述。这种并发结构意味着 CNN 和 transformer 分支可以分别最大程度地保留局部特征和全局表示。 FCU 被提出作为桥接模块,将 CNN 分支中的局部特征与 transformer 分支中的全局表示融合,如 Figure 2(b)。FCU 从第二个 block 开始应用,因为两个分支的初始化特征是相同的。沿着分支,FCU 以交互方式逐步融合特征图和 patch embeddings。

最后,对于 CNN 分支,所有特征都被 池化并馈送到一个分类器。对于 transformer 分支,class token 被取出并馈送到另一个分类器。在训练期间,使用两个交叉熵损失来分别监督两个分类器。损失函数的重要性根据经验设置为相同。在推理过程中,两个分类器的输出被简单地总结为预测结果。
3.2网络结构
CNN Branch
如 Figure 2 (b) 所示,CNN分支采用特征金字塔结构,特征图的分辨率随着网络深度的增加而降低,而通道数增加。整个分支分为 4 个阶段,如 Tab 1(CNN分支)。每个阶段由多个卷积 block 组成,每个卷积 block 包含 ![]() 个 bottlenecks 。按照 ResNet 中的定义,一个 bottleneck 包含一个 1×1 下投影卷积、一个 3×3 空间卷积、一个 1×1 上投影卷积,以及 bottleneck 的输入和输出之间的残差连接。在实验中,
个 bottlenecks 。按照 ResNet 中的定义,一个 bottleneck 包含一个 1×1 下投影卷积、一个 3×3 空间卷积、一个 1×1 上投影卷积,以及 bottleneck 的输入和输出之间的残差连接。在实验中, ![]() 在第一个卷积 block 中设置为1,在随后的 N-1 个卷积 block 中满足 ≥2。
在第一个卷积 block 中设置为1,在随后的 N-1 个卷积 block 中满足 ≥2。
Visual transformer 只通过一步将图像 patch 投影到向量中,会导致局部细节丢失。而在 CNN 中,卷积核在重叠的特征图上滑动,这提供了保留精细局部特征的可能性。因此,CNN 分支能够为 transformer 分支连续提供局部特征细节。
Transformer Branch
借鉴了 ViT,这个分支包含 N 个重复的 transformer blocks。如 Figure 2(b)所示,每个 transformer block 由一个多头自注意力模块和一个MLP块(包含一个上投影fc层和一个下投影fc层)组成。 LayerNorms 应用于自注意力层和 MLP 块中的每一层和残差连接之前。对于 tokenization,通过线性投影层将 stem 模块生成的特征图压缩成 14×14 的 patch embeddings 而没有重叠,这是一个的 4×4 卷积,步幅为 4。然后将一个class token 作为 patch embeddings,用于分类。考虑到 CNN 分支(3×3 卷积)对已经对局部特征和空间位置信息进行了编码,因此不再需要 位置嵌入。 这有助于提高下游视觉任务的图像分辨率。
Feature Coupling Unit(特征耦合单元FCU)
有了CNN分支中的特征图和 transformer 分支中的 patch embeddings,如何消除它们之间的错位是一个重要的问题。本文提出了 FCU 以交互方式将局部特征与全局表示连续地进行耦合。
一方面,必须意识到 CNN 和 transformer 的特征维度不一致。CNN 特征图的维度为 C×H×W(C、H、W 分别为通道、高度和宽度),而 patch embeddings 的形状为 (K + 1) × E,其中 K、1 和 E分别表示图像 patches 的数量、class token (原始vit中,没有用到decoder,所以需要多加一个 class token 维度,让它蕴含所有patch的信息,最终用它做图像表示去进行分类)和 embedding 维度。当输入到 transformer 分支时,特征图首先需要通过 1×1 卷积来对齐 patch embeddings 的通道数。然后使用下采样模块来完成空间维度对齐( Figure 2(a))。最后,特征图添加了 patch embeddings,如 Figure 2(b)所示。当从 transformer 分支反馈到 CNN 分支时,patch embeddings 需要上采样( Figure 2(a))以对齐空间尺度。然后通过 1×1 卷积将通道维度与 CNN 特征图的维度对齐,并添加到特征图中。同时,LayerNorm 和 BatchNorm 模块用于正则化特征(LN是用在 transformer 中,BN是用在CNN 中)。
另一方面,feature map和patch embedding之间存在显著的语义差异,即feature map是通过局部卷积算子收集的,而patch embedding是通过全局自注意机制聚合的。因此,FCU应用于每个块(除了第一个),以逐步缩小语义差距。

3.3分析与讨论
结构分析
将FCU考虑为短连接,我们可以将所提出的对偶结构抽象为特殊的串行残差结构,如图3(a)所示。在不同的残差连接单元下,Conformer可以实现不同深度的瓶颈组合(如ResNet,图3(b))和transformer块组合(如ViT,图3(d)),这意味着Conformer继承了cnn和visual transformer的结构优势。此外,它实现了不同深度的瓶颈和transformer块的不同排列,包括但不限于图3(c)和(e)。这极大地增强了网络的表示能力。
特征分析
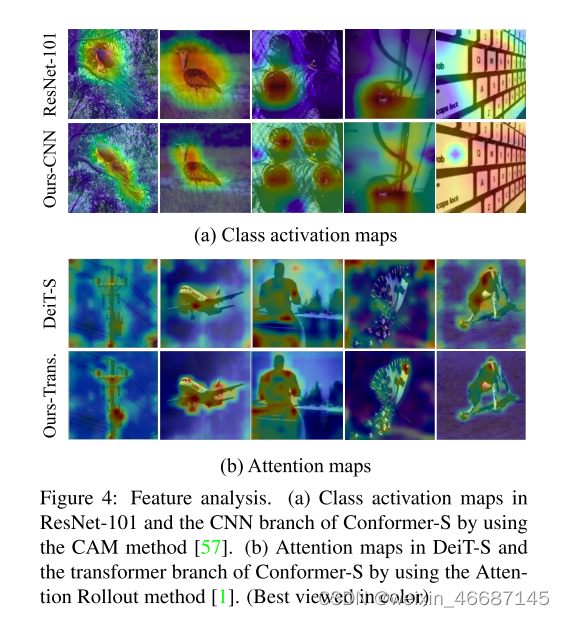
将特征图可视化为 Figure 1、将类激活图和注意力图可视化为 Figure 4。 与 ResNet 相比,通过耦合全局表示,Conformer 的 CNN 分支倾向于激活更大的区域而不是局部区域,这表明增强了长距离特征依赖性,这在 Figure 1(f) 和 Figure 4 (a)中得到了显着证明。由于 CNN 分支逐步提供精细的局部特征,Conformer 中 transformer 分支的 patch embeddings 保留了重要的详细局部特征(Figure 1(d)和(h)),这些特征被 visual transformer 破坏了(Figure 1(c)和(g))。此外,Figure 4 (b) 中的注意力区域更完整,而背景被显著抑制,这意味着 Conformer 学习的特征表示具有更高的判别能力。
4.实验
5.总结
我们提出Conformer,第一个将CNN与visual transformer双重主干结合。在Conformer中,我们利用卷积算子来提取局部特征,并利用自注意机制来捕获全局表示。我们设计了特征耦合单元来融合局部特征和全局表示,以交互的方式增强视觉表达的能力。实验表明,在具有可比较的参数和计算预算的情况下,Conformer优于cnn和visual transformer,与目前的先进技术形成鲜明对比。在下游任务上,Conformer已经显示出成为一个简单而有效的骨干网络的巨大潜力。















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









