







标题:CLIP-TSA:基于CLIP辅助的时序自我注意机制,用于弱监督下的视频异常检测
源码链接:github.com https://github.com/joos2010kj/CLIP-TSA
https://github.com/joos2010kj/CLIP-TSA
发表:ICIP-2023(CCF C)
摘要
视频异常检测(VAD)——由于其劳动密集型的本质,通常被表述为一种弱监督下的多实例学习问题——是视频监控中的一个挑战性问题,需要在未剪辑的视频中定位异常帧。在本文中,我们首次提议利用来自CLIP的ViT编码视觉特征,这与领域内传统的C3D或I3D特征形成对比,以在这一新颖技术中高效地抽取判别性表示。随后,我们通过运用我们提出的时序自我注意(TSA)机制来建模时间依赖性,并挑选感兴趣的时间片段。消融研究确认了TSA和ViT特征的有效性。
广泛的实验表明,在视频异常检测问题中常用的三个基准数据集(UCF-Crime,上海科技大学校园和XD-Violence)上,我们提出的CLIP-TSA方法在性能上大幅度超越了现有的最先进技术(SOTA)方法。我们的源代码可在以下网址获取:https://github.com/joos2010kj/CLIP-TSA。
关键词 — 视频异常检测、时序自我注意力机制、弱监督、多模态模型、细微差别。
1.引言
视频行为理解是一个活跃的研究领域,拥有众多应用,例如动作定位[1, 2, 3, 4]、动作识别[5, 6, 7, 8, 9, 10]、视频字幕生成[11, 12, 13, 14]等[15]。视频异常检测(VAD)的任务是在给定的视频中定位异常事件,主要存在三种范式,即全监督(Sup.)[16]、无监督(Un-Sup)[17]以及弱监督(Weakly-Sup)[18]。虽然全监督VAD通常能产生高性能,但它要求精细的异常标签(即帧级的正常/异常注释),而数据标注的工作量巨大是该问题的传统痛点。在无监督VAD中,单类分类(OCC)[19]是一种常见方法,模型仅在正常类样本上进行训练,假设未见过的异常视频会有较高的重建错误。然而,无监督VAD的表现通常较差,因为它缺乏对异常性的先验知识,且无法捕捉所有正常变化[20]。与无监督和全监督VAD相比,弱监督VAD被认为是最实用的方法,因为它通过使用视频级标签来降低手动精细标注的成本,从而在性能和标注效率之间取得平衡[21]。
在弱监督VAD中,存在两个根本性问题。首先,异常标记的帧往往被正常标记的帧所主导,因为视频未经过剪辑,且视频中的异常没有严格的长度要求。其次,异常并不一定总是与正常情况形成鲜明对比。因此,有时定位异常帧变得非常困难。因此,问题通常设计为多重实例学习(MIL)框架[18],其中视频被视为包含多个实例的包,每个实例都是视频片段。如果视频的任何片段异常,则视频标记为异常;如果所有片段正常,则视频标记为正常。异常标记的视频属于正例包,而正常标记的视频属于负例包。然而,现有的基于MIL的弱监督VAD方法在处理异常视频中任意数量的异常片段方面有限制。为了解决这个问题,我们受到可微分top-K运算符[22]的启发,引入了一种名为top-κ函数的新技术,它在类似的MIL设置中使用可微硬注意力定位视频中的κ个感兴趣的片段,以展示其有效性和适用于传统流行设置的能力。此外,我们引入了时序自我注意(TSA)机制,通过衡量片段的异常程度来生成重新加权的注意力特征。
此外,现有方法通过应用骨干网络(如C3D[23]、I3D[24])来编码视觉内容,这些网络在动作识别任务上进行了预训练。不同于动作识别问题,VAD依赖于能清晰表示场景中事件的判别性表示。因此,这些现有的骨干网络由于领域差距[16]而不适用。为了解决这一局限,我们借鉴了最近“视觉-语言”(V-L)工作的成功[25],这些工作证明了通过对比语言-图像预训练(CLIP)[26, 13, 14]学习到的特征表示的有效性。我们提出的CLIP-TSA遵循MIL框架,包含三个组件:(i) 由CLIP进行的特征编码;(ii) 利用我们的TSA在时间维度上建模片段一致性;(iii) 使用差-异最大化训练器进行弱监督模型训练。
2.提出的方法
让我们假设有这样一个弱标注的训练视频集合,其中每个视频
,它是一个由Nk帧组成的序列,每帧宽度为W像素,高度为H像素。而y(k) = {0, 1}是视频X(k)在异常检测方面的视频级标签(即,如果视频含有异常,则其值为1)。给定一个视频
,我们首先将X(k)分割成一系列δ帧的小片段
。通过将视觉语言(V-L)模型应用于每个小片段的中间帧来提取其特征表示。在这个工作里,选择了CLIP作为V-L模型;但是,可以使用任何V-L模型来替代。这样,每个δ帧的小片段si就由一个V-L特征fi ∈ Rd表示,整个视频X(k)则由一组视频特征向量
表示,其中
,Tk是视频X(k)中小片段的数量。为了使训练能够分批进行,输入特征F在时间维度上被标准化到统一的视频特征长度T,具体如下[18],其中对于F1和F2,分别有
:
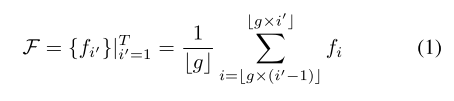
2.2 特征编码
我们选取每个小片段si的中间帧Ii作为该片段的代表。首先用预训练的视觉变换器[27]对帧Ii进行编码,提取视觉特征Ifi。随后,将特征Ifi通过预训练的CLIP投影到视觉投影矩阵L上,得到图像嵌入。因此,由Tk个小片段X = {si}|Tk i=1组成的视频X的嵌入特征Fk在方程2b中定义。最后,我们将嵌入特征应用视频规范化,如方程1所示,以获得最终的嵌入特征F:
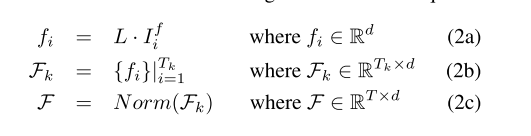
2.3 时序自我注意力(TSA)
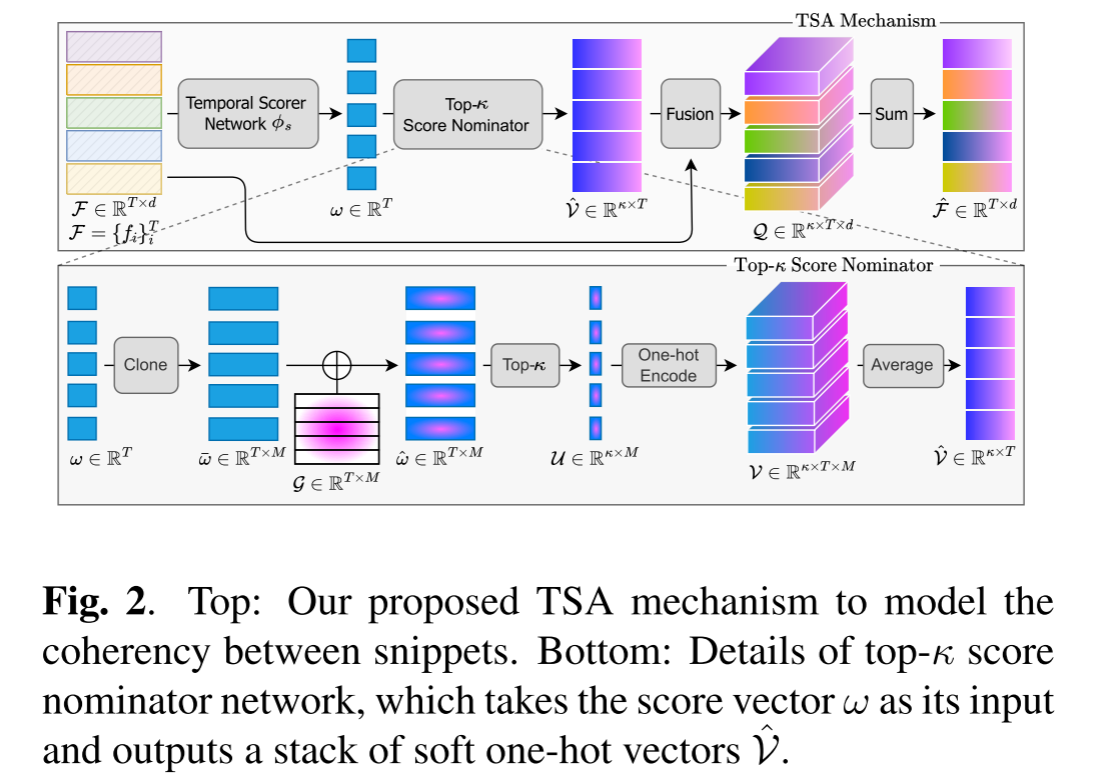

我们提出的TSA机制旨在模拟视频中片段之间的连贯性并选择κ个最相关的片段。它包含三个模块,即(i)时序评分网络,(ii)κ个最高评分选择器,以及(iii)融合网络,如图2和算法1所示。在TSA中,视觉语言特征F ∈ RT×d(来自2.2节的特征编码)首先通过一个时序评分网络ϕs转换成一个得分向量ω ∈ RT×1。这个网络设计得很浅,因此,在本文中我们选择了一个三层的多层感知机(MLP)。这些分数,每一个都代表了片段si,然后传递到κ个最高评分选择器中,从中提取视频中最相关的κ个片段。κ个最高评分选择器通过以下两个步骤实现。首先,得分向量ω ∈ RT×1被复制M次,得到克隆后的得分向量¯ω ∈ RT×M;M代表了要生成的独立样本数,用于计算带有噪声扰动特征的期望。第二步,通过方程3中的高斯噪声G ∈ RT×M对M份拷贝进行元素级相加,产生扰动后的得分向量ˆω ∈ RT×M: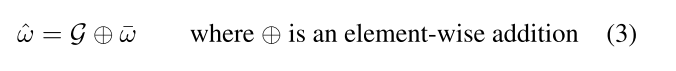
从高斯扰动后的得分ˆω ∈ RT×M中,基于得分大小独立地在M维方向上选择κ个最高分的片段,以代表最相关的片段,然后将它们通过one-hot编码成一个矩阵,其中每一项Vi ∈ Rκ×T包含一组one-hot向量。更具体地说,我们指导网络关注κ个最高值的幅度,因为差异最大化训练器(见第2.4节)训练异常片段具有较高的值,而正常片段具有较低的值。矩阵V然后在其M维方向上平均,以产生一叠软one-hot向量ˆV ∈ Rκ×T。通过软one-hot编码机制,更多的注意力或权重被放置在接近和位于κ个最高分索引的位置(例如,[0, 0, 1, 0] → [0, 0.03, 0.95, 0.02])。请参阅算法2了解其概览。
之后,这叠扰动后的软one-hot向量ˆV ∈ Rκ×T被通过复制d次转换成˜V ∈ Rκ×T×d,而输入特征向量集合F ∈ RT×d也通过复制κ次变成˜F ∈ Rκ×T×d。接下来,携带片段重权信息的矩阵˜V和代表输入视频特征的矩阵˜F融合在一起,创建一个扰动特征Q ∈ Rκ×T×d,该特征根据之前的计算表示了基于片段的权重特征幅度。然后,扰动特征矩阵Q中的每个κ维扰动特征向量Q ∈ Rκ×d独立地在其κ维方向上求和,将Qi的信息合并为一个向量ˆfi ∈ Rd。权重特征向量ˆfi ∈ Rd,它们集体形成,作为TSA σ的输出,代表异常注意力特征ˆF ∈ RT×d。
2.4 差异最大化训练器学习
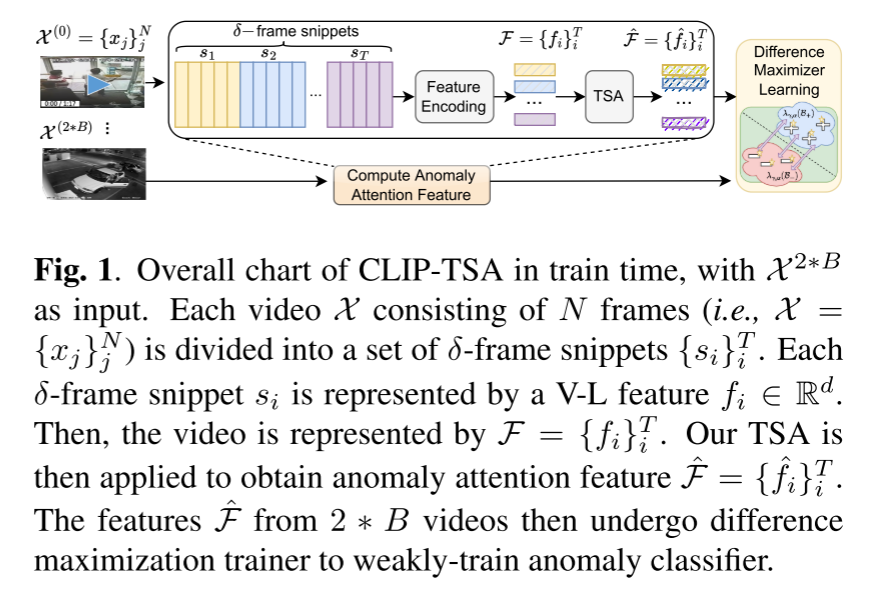
图1. 在训练时间CLIP-TSA的整体流程图,以X2*B作为输入。 每个由N帧组成(即X = {xj}N j)的视频X被分割成一系列δ帧的小片段{si}T i。每一个δ帧的小片段si通过视觉-语言(V-L)模型表示为一个d维的特征fi。这样,整个视频就被表示为一个特征序列F = {fi}T i。然后,我们的时间片段注意力(TSA)机制被应用到这个特征序列上,从而获得异常注意力特征Fˆ = { ˆfi}T i。从2 * B个视频中得到的特征Fˆ随后经过差异最大化训练器(DMT)进行弱监督的异常分类器训练。
给定一个由2 * B个视频组成的迷你批次,其中每个视频X(k)由TSA(第2.3节)获取的
表示。设输入的迷你批次由Z =
表示,其中B、T和d分别表示用户指定的批次大小、归一化的时间片段数量和特征维度。实际的批次大小依赖于用户输入的批次大小,遵循2 * B的规则,因为前半部分,
,装载了一组正常样本(袋),而后半部分,
,在迷你批次内装载了一组异常样本(袋)。
迷你批次经过TSA阶段后,会输出一组重新加权的正常注意力特征和一组重新加权的异常注意力特征
。这些重新加权的注意力特征Zˆ随后被送入由膨胀卷积[28]和非局部块[29]组成的卷积网络模块J中,根据重新加权的幅度来建模片段之间的长期和短期关系。由此产生的卷积注意力特征堆
,其中Zˇ ∈ R2*B×T×d,然后传递给基于浅层MLP(多层感知机)的得分分类网络C,该网络将特征转换为一组得分U ∈ R2*B×T×1,以确定特征片段的二进制异常状态。这组得分U作为返回变量的一部分被保存下来,用于计算损失。
接下来,迷你批次Zˇ中的每个卷积注意力特征将经历差异最大化训练器(DMT)。借鉴[30, 18]中采用的顶部-α实例分离概念,我们在本问题中使用表示为
的DMT来最大化两个对比袋Zˇ −和Zˇ +之间顶级实例的分离或差异,首先是从每个卷积注意力特征Fˇ k中根据特征幅度挑选出前-α片段。这为每个卷积注意力特征Fˇ k ∈ RT×d生成了一个前α子集
。其次,对F˙ k在前-α片段上取平均,以创建一个代表袋的特征向量F¨ k ∈ Rd。此过程由下面的等式4解释:
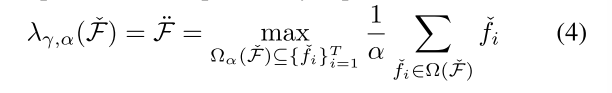
在此处,λ由γ参数化,表示其对卷积网络模块J能力的依赖(即,F¨的表示取决于相对于J选择的前-α个正例)。接下来,α表示Ω的大小,Ω代表了Fˇ中α个片段的子集。每个代表向量F¨随后被归一化以产生... F ∈ R1。
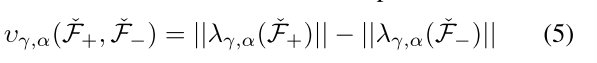
分离度按照等式5进行计算,其中Fˇ − = { ˇf−,i}|T i表示一个负袋,而Fˇ + = { ˇf+,i}|T i表示一个正袋。更具体地说,我们利用预期分离性定理[30]来最大化从每个对比袋中选出的前-α实例(特征片段)的分离度:在假设Z+有ϵ ∈ [1, T]个异常样本和(T - ϵ)个正常样本,Z−有T个正常样本,且T = |Z+| = |Z−|的情况下,只要α ≤ ϵ,从正(异常)和负(正常)袋中选出的前-α实例(特征片段)的分离度预计会被最大化(最大化正常和异常的特征)。之后,为了计算损失,一组归一化的代表特征![]() 和
和![]() 被用于测量它们之间的边距。随后,这批边距被平均,并与使用得分集U计算的基于得分的二元交叉熵损失一起,作为净损失的一部分。
被用于测量它们之间的边距。随后,这批边距被平均,并与使用得分集U计算的基于得分的二元交叉熵损失一起,作为净损失的一部分。
3. 实验结果
A. 数据集与实施细节
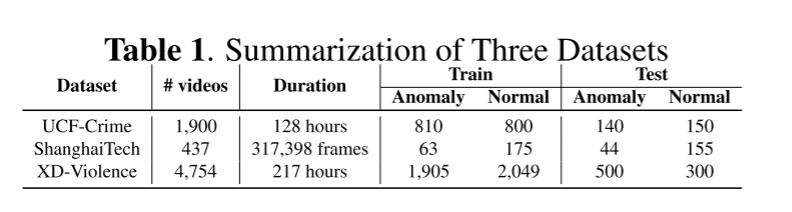
我们在三个数据集上进行了实验,即UCF-Crime [18]、ShanghaiTech [47]和XD-Violence [39],如表1所总结。参照[18]的做法,我们将每个视频分割成32个视频片段,即T = 32(方程1),片段长度δ = 16。评分网络θs(第2.3节)被定义为一个包含三层(512, 256, 1)的多层感知机(MLP)。利用CLIP [26],我们将d设置为512。在方程3中,我们为高斯噪声设置了M = 100。令κ = ⌊T×r⌋;r是一个超参数,我们选择0.7作为其值。我们的CLIP-TSA以端到端的方式使用PyTorch进行训练。我们使用Adam优化器 [51],学习率为0.001,权重衰减为0.005,所有数据集的批次大小为16。
B. 性能比较
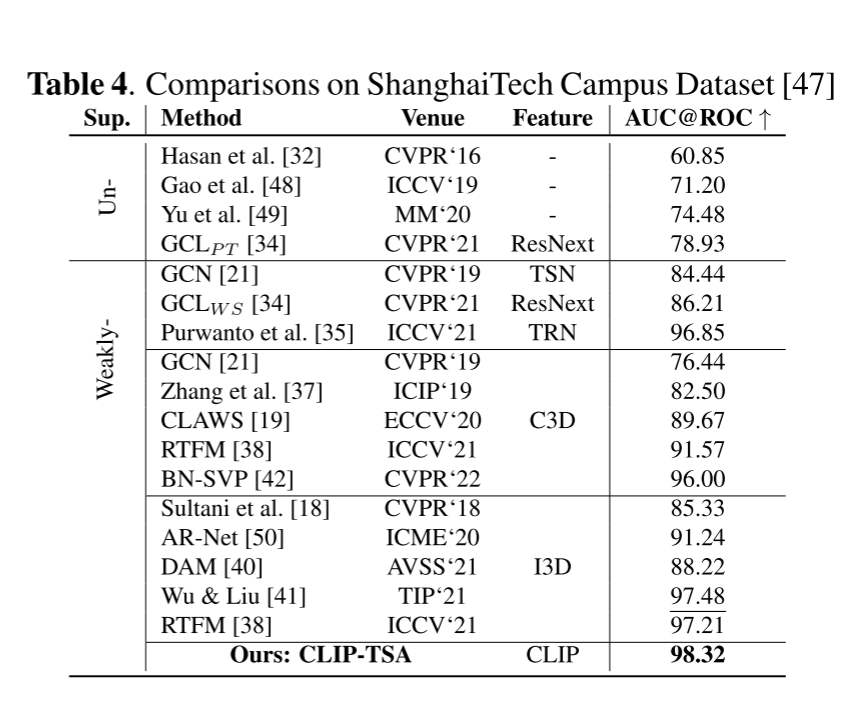
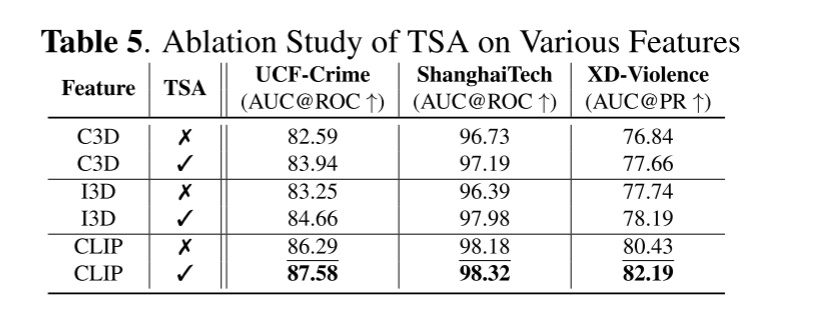
表2、表3和表4展示了我们的提议方法与其他最先进的技术(SOTAs)在多个数据集上的性能比较。在所有表格中,最佳分数以粗体标出,次佳分数则被下划线标出。我们显著的性能主要来自于两个模块:(i)丰富的视觉语言特征CLIP和(ii)时间片段注意力(TSA)。为了分析每个模块的影响并做出公平的比较,我们在表5中进行了一项全面的消融研究。在这个表格中,我们通过以下方式对每个模块进行基准测试:(i)将CLIP特征替换为C3D [23]和I3D [24],以及(ii)开启和关闭我们的TSA模块。将表5与表2至表4进行对比,我们可以看到,C3D-TSA(用C3D替换CLIP特征)和I3D-TSA(用I3D替换CLIP特征)在UCF-Crime和ShanghaiTech数据集上仍然优于其他与C3D和I3D特征基准测试的SOTA模型。至于XD-Violence数据集,我们超越了所有其他基于视觉的方法,并且那些具有更高分数的SOTA通常会额外利用模态,比如音频(A),使用VGGish。很明显,表5显示:(i)在开启我们的TSA情况下所有场景的性能都有所提升,以及(ii)由于强大的CLIP特征和TSA模块的贡献,我们提议的CLIP-TSA获得了最佳性能。

4.总结
本文介绍了CLIP-TSA,这是一种有效的端到端弱监督视频异常检测(VAD)框架。具体而言,我们提出了新颖的时间段注意力(TSA)机制,该机制在最大化对特征子集的关注的同时最小化对噪声的关注,并展示了其在这一领域的适用性。我们还将TSA应用于由CLIP提取的特征,以展示其在视觉语言特征中的有效性,并在问题中加以利用。全面的实验和消融研究通过与现有最先进技术(SOTAs)在三个流行的VAD数据集上的比较,经验上验证了我们模型的卓越性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









