






基于特征融合与关键词转字幕增强的大规模对比语言-音频预训练
作者:Yusong Wu、Ke Chen、Tianyu Zhang、Yuchen Hui、Marianna Nezhurina、Taylor Berg-Kirkpatrick、Shlomo Dubnov
- Mila,魁北克人工智能研究所,蒙特利尔大学
- 加利福尼亚大学圣地亚哥分校
- LAION

摘要
对比学习在多模态表示学习领域已取得显著成果。本文提出一种对比语言-音频预训练流程,通过将音频数据与自然语言描述相结合来构建音频表示。为实现这一目标,我们首先发布了LAION-Audio-630K,这是一个包含633,526个音频-文本对的大规模数据集,数据来源多样。其次,我们构建了对比语言-音频预训练模型,综合考量不同的音频编码器和文本编码器,并在模型设计中融入特征融合机制与关键词转字幕增强技术,进一步提升模型处理可变长度音频输入的能力与性能。最后,我们开展了全面的实验,通过文本到音频检索、零样本音频分类和有监督音频分类这三项任务对模型进行评估。结果表明,我们的模型在文本到音频检索任务中表现卓越;在音频分类任务中,模型在零样本设置下达到了当前最优性能,且在非零样本设置下的性能可与其他模型相媲美。LAION-Audio-630K数据集和本文提出的模型均已公开。
关键词
对比学习;表示学习;文本到音频检索;音频分类;音频数据集
1. 引言
音频与文本、图像数据一样,是世界上最常见的信息类型之一。然而,不同的音频任务通常需要精细标注的数据,由于数据收集过程耗费大量人力,这限制了可用音频数据的规模。因此,为众多音频任务设计一种无需大量监督的有效音频表示方法仍是一个挑战。
对比学习范式是一种成功的解决方案,可用于在从互联网收集的大规模噪声数据上训练模型。最近提出的对比语言-图像预训练(CLIP)通过将文本和图像投影到共享的潜在空间中,学习它们之间的对应关系。训练过程中将真实的图像-文本对视为正样本,其他组合视为负样本。与单模态数据训练不同,CLIP不受数据注释的限制,并且在ImageNet数据集的域外变体的零样本设置中实现了高精度,展现出强大的鲁棒性。此外,CLIP在诸如文本到图像检索和文本引导的图像字幕生成等下游任务中也取得了巨大成功。与视觉类似,音频和自然语言也包含重叠信息。例如,在音频事件分类任务中,某些事件的文本描述可以映射到相应的音频。这些文本描述具有相似的含义,可以与相关音频一起学习,形成跨模态信息的音频表示。此外,训练这样的模型只需要配对的音频和文本数据,易于收集。
最近的几项研究提出了用于文本到音频检索任务的对比语言-音频预训练模型的原型。[6]利用预训练音频神经网络(PANN)作为音频编码器,BERT作为文本编码器,并使用多种损失函数来评估文本到音频的检索性能。[5]进一步将HTSAT和RoBERTa纳入编码器列表,以进一步提升性能。然后,[4]研究了学习到的表示在音频分类下游任务中的有效性。其他一些研究,如AudioClip和WaveCLIP,则更侧重于对比图像-音频(或图像-音频-语言)预训练模型。所有这些模型都显示出对比学习在音频领域的巨大潜力。
尽管如此,当前的研究尚未充分发挥语言-音频对比学习的全部优势。首先,上述模型是在相对较小的数据集上训练的,这表明需要进行大规模的数据收集和增强以用于训练。其次,先前的工作缺乏对音频/文本编码器选择和超参数设置的全面研究,而这对于确定基本的对比语言-音频架构至关重要。第三,模型难以适应不同长度的音频,特别是基于Transformer的音频编码器。需要有一种解决方案来处理可变长度的音频输入。最后,大多数语言-音频模型研究仅专注于文本到音频检索,而未评估其在下游任务中的音频表示能力。作为一种表示模型,我们期望它在更多下游任务中的泛化能力能有更多发现。
在本文中,我们从上述问题出发,对数据集、模型设计和实验设置进行了改进:
- 我们发布了LAION-Audio-630K,这是目前最大的公开音频字幕数据集,包含633,526个音频-文本对。为了促进学习过程,我们使用关键词转字幕模型将AudioSet的标签扩充为相应的字幕。该数据集也可用于其他音频任务。
- 我们构建了一个对比语言-音频预训练流程。选择了两个音频编码器和三个文本编码器进行测试。我们采用特征融合机制来提升性能,并使模型能够处理可变长度的输入。
- 我们对模型进行了全面的实验,包括文本到音频检索任务,以及零样本和有监督的音频分类下游任务。我们证明了数据集的扩展、关键词转字幕增强和特征融合可以从不同角度提升模型的性能。它在文本到音频检索和音频分类任务中达到了当前最优(SOTA),甚至可与有监督模型的性能相媲美。
- 我们将LAION-Audio-630K数据集和提出的模型均公开。
2. LAION-Audio-630K和训练数据集
2.1 LAION-Audio-630K
我们收集了LAION-Audio-630K,这是一个大规模的音频-文本数据集,由633,526对数据组成,总时长为4,325.39小时。它包含人类活动、自然声音和音频特效的音频,数据来源包括8个公开网站。我们通过下载音频和相关文本描述来收集这些数据集。据我们目前所知,LAION-Audio-630K是公开可用的最大音频-文本数据集,比之前的音频-文本数据集大一个数量级,详见表1。
2.2 训练数据集
为了测试模型在不同规模和类型数据集上的性能变化,我们在本文中使用了三种训练集设置,规模从小到大。这些设置使用了三个数据集:1)AudioCaps+Clotho(AC+CL)包含约55,000个音频-文本对训练样本。2)LAION-Audio-630K(LA.)包含约630,000个音频-文本对。3)AudioSet包含190万个音频样本,每个样本仅有标签。在处理这些数据集时,我们在评估集中排除了所有重叠数据。训练数据集的更多详细信息可在在线附录中查看。
2.3 数据集格式和预处理
本文中使用的所有音频文件均预处理为单声道,采样率为48kHz,格式为FLAC。对于仅有标签或标记的数据集,我们使用 “The sound of label-1, label-2, …, and label-n” 模板或关键词转字幕模型(详见3.5节)将标签扩展为字幕。这样,我们可以将更多数据用于对比语言-音频预训练模型的训练。结合所有数据集,我们将带有文本字幕的音频样本总数增加到了250万个。
3. 模型架构
3.1 对比语言-音频预训练
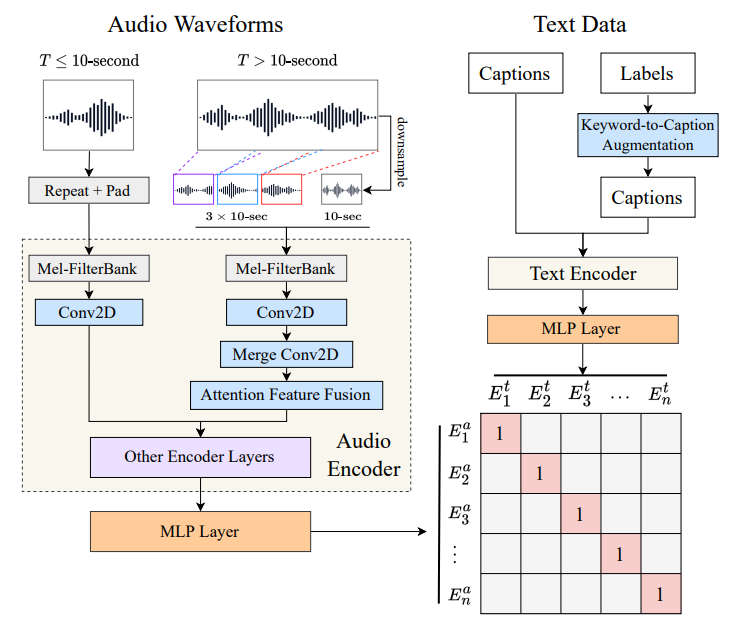
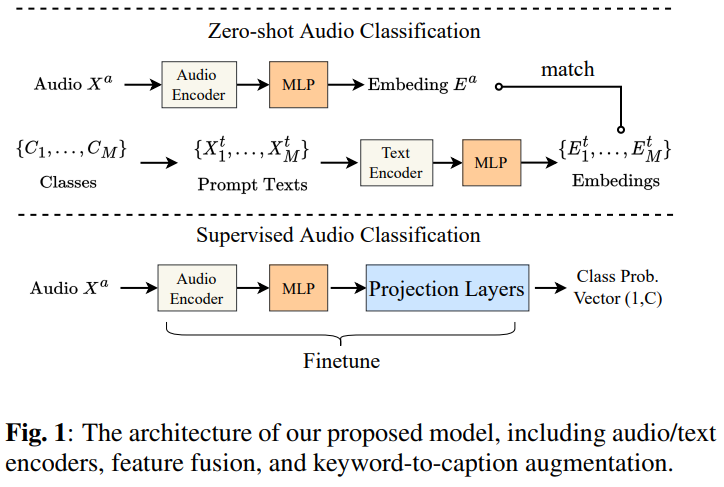
图1展示了我们提出的对比语言-音频编码器模型的总体架构。与CLIP类似,我们有两个编码器,分别处理音频数据
X
i
a
X_{i}^{a}
Xia 和文本数据
X
i
t
X_{i}^{t}
Xit ,其中
(
X
i
a
,
X
i
t
)
(X_{i}^{a}, X_{i}^{t})
(Xia,Xit) 是由
i
i
i 索引的音频-文本对之一。音频嵌入
E
i
a
E_{i}^{a}
Eia 和文本嵌入
E
i
t
E_{i}^{t}
Eit 分别通过音频编码器
f
a
u
d
i
o
(
−
)
faudio(-)
faudio(−) 和文本编码器
f
t
e
x
t
(
⋅
)
f_{text }(\cdot)
ftext(⋅) ,并经过投影层获得:
E
i
a
=
M
L
P
a
u
d
i
o
(
f
a
u
d
i
o
(
X
i
a
)
)
E_{i}^{a}=MLP_{audio }(f_{audio }(X_{i}^{a}))
Eia=MLPaudio(faudio(Xia))
E
i
t
=
M
L
P
t
e
x
t
(
f
t
e
x
t
(
X
i
t
)
)
E_{i}^{t}=MLP_{text }(f_{text }(X_{i}^{t}))
Eit=MLPtext(ftext(Xit))
其中,音频/文本投影层是一个两层的多层感知器(MLP),使用ReLU作为激活函数,将编码器的输出映射到相同的维度
D
D
D (即
E
i
a
E_{i}^{a}
Eia ,
E
i
t
∈
R
D
E_{i}^{t} \in \mathbb{R}^{D}
Eit∈RD )。
模型通过音频和文本嵌入对之间的对比学习范式进行训练,采用与[1]中相同的损失函数:
L
=
1
2
N
∑
i
=
1
N
(
l
o
g
e
x
p
(
E
i
a
⋅
E
i
t
/
τ
)
∑
j
=
1
N
e
x
p
(
E
i
a
⋅
E
j
t
/
τ
)
+
l
o
g
e
x
p
(
E
i
t
⋅
E
i
a
/
τ
)
∑
j
=
1
N
e
x
p
(
E
i
t
⋅
E
j
a
/
τ
)
)
L=\frac {1}{2N}\sum _{i=1}^{N}(log \frac {exp (E_{i}^{a}\cdot E_{i}^{t}/\tau )}{\sum _{j=1}^{N}exp (E_{i}^{a}\cdot E_{j}^{t}/\tau )}+log \frac {exp (E_{i}^{t}\cdot E_{i}^{a}/\tau )}{\sum _{j=1}^{N}exp (E_{i}^{t}\cdot E_{j}^{a}/\tau )})
L=2N1i=1∑N(log∑j=1Nexp(Eia⋅Ejt/τ)exp(Eia⋅Eit/τ)+log∑j=1Nexp(Eit⋅Eja/τ)exp(Eit⋅Eia/τ))
其中,
τ
\tau
τ 是一个可学习的温度参数,用于缩放损失。两个对数项分别考虑音频到文本的对数几率和文本到音频的对数几率。
N
N
N 通常是数据的数量,但在训练阶段,
N
N
N 用作批量大小,因为我们无法计算所有数据的完整矩阵,而是通过批量梯度下降来更新模型。
训练模型后,嵌入 ( E a , E b ) (E^{a}, E^{b}) (Ea,Eb) 可用于图1所示的不同任务,具体如下文小节所述。
3.2 推理阶段的下游任务
- 文本到音频检索:目标音频嵌入 E p a E_{p}^{a} Epa 可以通过余弦相似度函数在 M M M 个文本 E t = E 1 t , . . . , E M t E^{t}={E_{1}^{t}, ..., E_{M}^{t}} Et=E1t,...,EMt 中找到最接近的文本嵌入 E q t E_{q}^{t} Eqt ,从而确定最佳匹配。
- 零样本音频分类:对于 M M M 个音频类别 C = C 1 , . . . , C M C={C_{1}, ..., C_{M}} C=C1,...,CM ,我们可以构建 M M M 个提示文本 X t = X 1 t , . . . , X M t X^{t}={X_{1}^{t}, ..., X_{M}^{t}} Xt=X1t,...,XMt (例如,“the sound of class-name”)。对于给定的音频 X P a X_{P}^{a} XPa ,我们通过其嵌入上的余弦相似度函数在 X t X^{t} Xt 中确定最佳匹配 X q t X_{q}^{t} Xqt 。使用对比语言-音频预训练的一个优点是音频类别不受限制(即零样本),因为模型可以将分类任务转换为文本到音频检索任务。
- 有监督音频分类:训练模型后,对于给定的音频 X P a X_{P}^{a} XPa ,其嵌入 E p a E_{p}^{a} Epa 可以通过在后面添加一个投影层并进行微调(即非零样本设置),进一步映射到固定类别的分类任务中。
3.3 音频编码器和文本编码器
我们选择了两个模型,PANN和HTSAT,来构建音频编码器。PANN是一个基于CNN的音频分类模型,有7个下采样CNN块和7个上采样块。HTSAT是一个基于Transformer的模型,有4组swin-transformer块,在三个音频分类数据集上达到了当前最优性能。对于这两个模型,我们使用其倒数第二层的输出,即一个 L L L 维向量,作为发送到投影MLP层的输出,其中 L P A N N = 2048 L_{PANN}=2048 LPANN=2048 , L H T S A T = 768 L_{HTSAT}=768 LHTSAT=768 。
我们选择了三个模型,CLIP transformer(CLIP的文本编码器)、BERT和RoBERTa,来构建文本编码器。文本编码器的输出维度分别为 L C L I P = 512 L_{CLIP}=512 LCLIP=512 、 L B E R T = 768 L_{BERT}=768 LBERT=768 和 L R o B E R T a = 768 L_{RoBERTa }=768 LRoBERTa=768 。我们使用两个带有ReLU激活函数的两层MLP,将音频和文本输出都映射到512维,这是在对比学习范式下训练时音频/文本表示的大小。
3.4 可变长度音频的特征融合
与可以调整大小为统一分辨率的RGB图像数据不同,音频具有可变长度的特性。传统上,人们会将完整的音频输入到音频编码器中,并将每帧或每个音频块的嵌入平均值作为输出(即切片并投票)。然而,这种传统方法在处理长音频时计算效率较低。如图1左侧所示,我们通过结合粗略的全局信息和随机采样的局部信息,在恒定的计算时间内对不同长度的音频输入进行训练和推理。对于时长为 T T T 秒的音频和固定的块持续时间 d = 10 d = 10 d=10 秒:
- 当 T ≤ d T ≤d T≤d 时:我们首先重复输入,然后用零值填充。例如,一个3秒的输入将被重复为 3 × 3 = 9 3×3 = 9 3×3=9 秒,并填充1秒的零值。
- 当
T
>
d
T>d
T>d 时:我们首先将输入从
T
T
T 秒下采样到
d
d
d 秒作为全局输入。然后,我们从输入的前
1
3
\frac{1}{3}
31 、中间
1
3
\frac{1}{3}
31 和后
1
3
\frac{1}{3}
31 分别随机切片三个
d
d
d 秒的片段,作为局部输入。我们将这些
4
×
d
4 ×d
4×d 的输入发送到音频编码器的第一层以获得初始特征,然后三个局部特征将通过另一个在时间轴上具有3步长的2D卷积层进一步转换为一个特征。最后,局部特征
X
l
o
c
a
l
a
X_{local }^{a}
Xlocala 和全局特征
X
g
l
o
b
a
l
a
X_{global }^{a}
Xglobala 将按如下方式融合:
X f u s i o n a = α X g l o b a l a + ( 1 − α ) X l o c a l a X_{fusion }^{a}=\alpha X_{global }^{a}+(1-\alpha) X_{local }^{a} Xfusiona=αXglobala+(1−α)Xlocala
其中, α = f A F F ( X q l o b a l a , X l o c a l a ) \alpha=f_{AFF}(X_{q l o b a l}^{a}, X_{local }^{a}) α=fAFF(Xqlobala,Xlocala) 是通过注意力特征融合(AFF)获得的因子,AFF是一个双分支CNN模型,用于学习两个输入的融合因子。与 “切片并投票” 方法相比,特征融合还节省了训练时间,因为我们只在前几层处理音频切片。
3.5 关键词转字幕增强
如2.1节所述,一些数据集包含合理的标签或标记,作为相应音频的关键词。如图1右侧所示,我们使用预训练的语言模型T5在这些关键词的基础上生成字幕。我们还在后期处理中对输出句子进行去偏处理。例如,我们用 “person” 替换 “woman” 和 “man” 以消除性别偏见。由于篇幅限制,我们在在线附录中提供了增强的示例。
4. 实验
在本节中,我们对提出的模型进行了三个实验。首先,我们使用不同的音频和文本编码器进行训练,以找到最佳的基线组合。然后,我们在不同规模的数据集上训练模型,并使用特征融合和关键词转字幕增强技术,以验证所提出方法的有效性。对于前两个实验,我们通过音频到文本和文本到音频检索的召回率和平均精度均值(mAP)来评估模型的性能。最后,我们使用最佳模型进行零样本和有监督的音频分类实验,以评估模型对下游任务的泛化能力。
4.1 超参数和训练细节
如2.2节所述,我们使用AudioCaps、Clotho、LAION-Audio-630K,以及通过关键词转字幕增强的额外数据集AudioSet来训练我们的模型。对于音频数据,我们使用10秒的输入长度、480的跳跃大小、1024的窗口大小和64个梅尔频段来计算STFT和梅尔频谱图。结果,发送到音频编码器的每个输入的形状为( T = 1024 T = 1024 T=1024 , F = 64 F = 64 F=64 )。对于文本数据,我们对文本进行分词,最大分词长度为77。
在不使用特征融合训练模型时,长度超过10秒的音频将被随机分割为10秒的片段。在训练过程中,我们使用Adam优化器, β 1 = 0.99 \beta_{1}=0.99 β1=0.99 , β 2 = 0.9 \beta_{2}=0.9 β2=0.9 ,并采用热身策略和余弦学习率衰减,基本学习率为 1 0 − 4 10^{-4} 10−4 。我们在AudioCaps+Clotho数据集上使用768的批量大小进行训练,在包含LAION-Audio-630K的训练数据集上使用2304的批量大小,在包含AudioSet的训练数据集上使用4608的批量大小。我们训练模型45个epoch。
4.2 文本到音频检索
- 音频和文本编码器:我们首先进行实验,为文本到音频检索任务选择最佳的音频编码器和文本编码器。我们在3.3节中将两个音频编码器与三个文本编码器进行组合,这些编码器均从预训练的检查点加载,与[5,7,8]相同。在这个实验中,我们仅在AudioCaps和Clotho数据集(约55,000个数据)上进行训练,并报告在音频到文本(A→T)和文本到音频(T→A)两个视角下最佳的mAP@10。
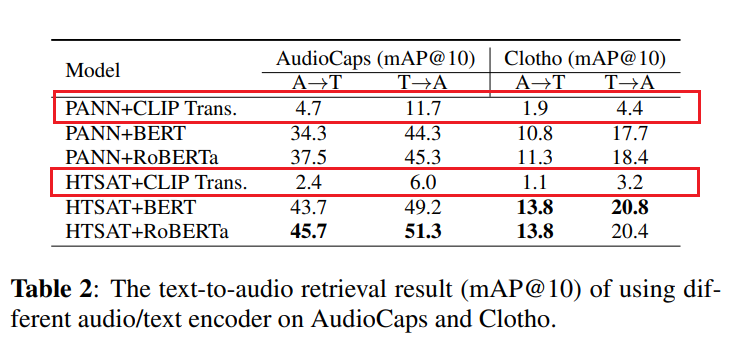
根据表2中的结果,对于音频编码器,HTSAT与RoBERTa或BERT文本编码器结合时的性能优于PANN。对于文本编码器,RoBERTa的性能优于BERT,而CLIP transformer的性能最差。这与先前工作[4,8]中对文本编码器的选择一致。在进一步分析CLIP transformer模型的损失收敛趋势时,我们发现RoBERTa的过拟合程度较低,而CLIP transformer的过拟合程度较高,因此其泛化性能较低。
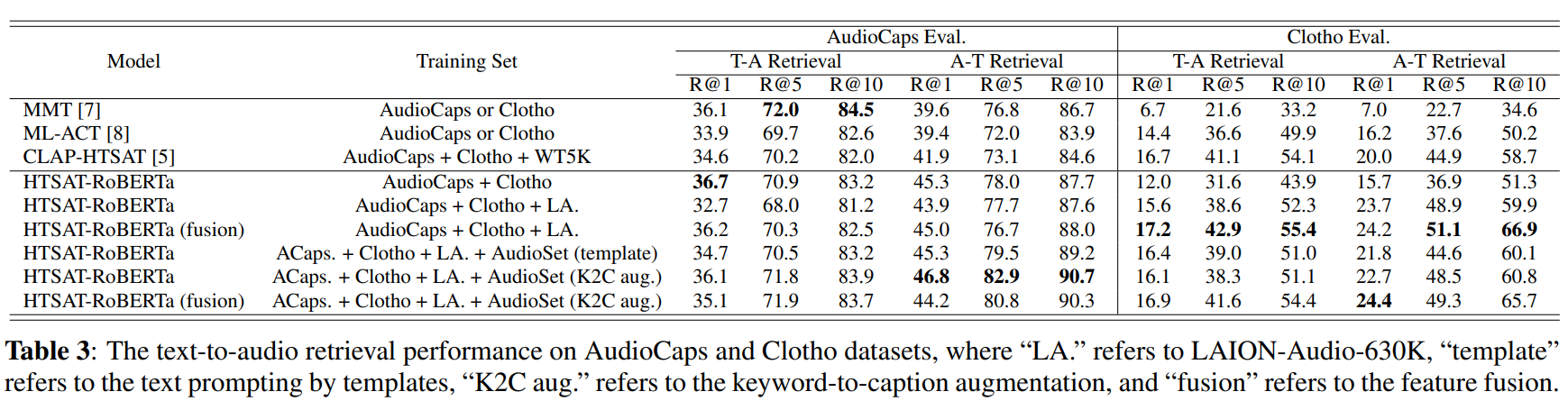
- 数据集规模:因此,我们应用HTSAT-RoBERTa作为最佳模型设置,进行文本到音频检索实验,作为表3中的综合评估。我们采用与[7, 8]相同的指标来计算该任务中不同排名的召回率得分。在训练集中,我们逐渐增加数据集的规模。我们发现,将数据集从 “AudioCaps + Clotho” 扩展到 “LA.” 并没有提高在AudioCaps评估集上的结果,但在Clotho评估集上的性能有所提升,这与MMT [7]和CLAP - HTSAT [5]之间的比较结果相似。一个原因是AudioCaps包含与AudioSet相似的音频,而音频编码器加载的检查点是在AudioSet上预训练的。当模型从其他来源接收更多数据时,它提高了泛化能力,但使分布偏离了AudioSet数据。因此,在AudioCaps上的性能下降,但在Clotho上的性能大幅提升,这表明了模型在不同类型音频之间保持性能的权衡。
- 关键词转字幕和特征融合:当在模型中添加特征融合机制和关键词转字幕增强时,我们可以观察到这两种方法都提高了性能。特征融合在Clotho数据集上特别有效,因为它包含更长的音频数据(超过10秒)。当我们将AudioSet添加到训练集中,无论是使用模板提示还是关键词转字幕增强,我们可以看到在AudioCaps上的性能再次提高,而在Clotho上的性能下降。这进一步证实了上述AudioCaps和Clotho数据集之间的性能权衡。并且在大多数指标上,关键词转字幕增强确实比简单的模板文本提示方法带来了更好的性能。
结果,我们的最佳模型在文本到音频检索任务中的大多数指标上优于先前的方法(主要是在AudioCaps上R@1 = 36.7%,在Clotho上R@1 = 18.2%)。我们表明,在大规模数据集(LAION - Audio - 630K和带有关键词转字幕增强的AudioSet)上进行训练,以及特征融合可以有效地提高模型性能。
4.3零样本和有监督音频分类
- 零样本音频分类:为了研究模型的泛化能力和鲁棒性,我们对之前实验中表现最佳的三个模型进行零样本音频分类实验。我们在三个音频分类数据集上评估模型,即ESC - 50 [27]、VGGSound [28]和城市声音8K(US8K)[29]。我们使用top - 1准确率作为指标。我们通过执行音频到文本检索来对音频进行分类,每个文本对应于通过“This a sound of label.”从类标签转换而来的文本提示。我们注意到我们的训练数据与正在评估的零样本数据集之间存在数据集重叠。我们排除了所有重叠样本,并在整个剩余数据集上进行零样本评估。
- 有监督音频分类:我们通过在FSD50K [30]和VGGSound数据集上微调音频编码器来进行有监督音频分类。我们没有在ESC50和城市声音8K上进行这个实验,因为这些数据集中存在潜在的数据泄露问题,会使结果与先前方法无法比较。特别地,我们使用平均精度均值(mAP)作为评估FSD50K的指标。
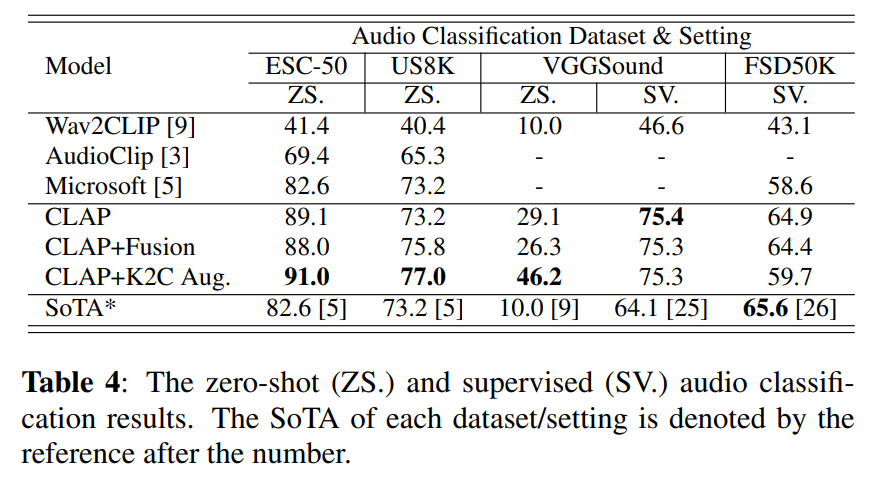
如表4所示,我们的模型在所有三个数据集上实现了零样本音频分类的新的最优结果,证明了我们的模型对未见数据具有很高的泛化能力。关键词转字幕增强显著提高了VGGSound和US8K上的性能,因为它添加了更多的文本字幕来“丰富”文本嵌入空间。特征融合不仅使模型能够处理可变长度的输入,而且比以前的模型取得了更好的性能。我们最好的有监督音频分类结果在VGGSound数据集上优于当前的最优结果,并且在FSD50K数据集上接近最优结果。结果验证了所提出的模型在对比学习范式中也学习到了有效的音频表示。
5.结论和未来工作
在本文中,我们提出了一个大规模的音频 - 文本数据集,并对当前的语言 - 音频对比学习范式进行了改进。我们表明,LAION - Audio - 630K、带有关键词转字幕增强的AudioSet和特征融合有效地促进了更好的音频理解、任务性能,并能够对可变长度的数据进行有效的学习。未来的工作包括收集更大的训练数据集,将表示应用于更多的下游任务,如音频合成和分离。
6.参考文献
[此处省略参考文献列表]
A.附录
B.致谢
Yusong Wu、Ke Chen、Tianyu Zhang是LAION项目的开源贡献者。我们的代码库基于以下开源项目:PANN、HTSAT、open clip、PyTorch。我们感谢LAION、Stability.ai和橡树岭国家实验室的Summit集群提供的计算基础设施支持。这个项目是在蒙特利尔大学的IFT - 6167课程和Mila提出的,由Irina Rish教授指导。我们感谢Christoph Schuhmann、Richard Vencu、Romain Beaumon的支持,没有他们这个项目不可能完成。我们感谢声学与音乐研究协调研究所(IRCAM)和REACH项目:提高人机协作音乐创作能力对这个项目的支持。我们感谢所有社区贡献者对LAION - 630k数据集收集的贡献。这些社区贡献者(Discord用户名)包括但不限于:@marianna13#7139、@Chr0my#0173、@PiEquals4#1909、@Yuchen Hui#8574、@Antoniooooo#4758、@IYWO#9072、krishna#1648、@dicknascarsixtynine#3885和@turian#1607。我们感谢Xinhao Mei对检索指标的解释和帮助。
C.评估检索性能的细节
在本研究中,主要关注的是使用R@1、R@5、R@10和平均精度均值(mAP)等指标来评估模型在检索性能方面的有效性。特别是Clotho和AudioCaps数据集,其特点是每个音频样本有五个文本标签。因此,在评估这些数据集上的检索性能时,我们采用与先前研究相同的指标,具体是在[7,8]中概述的指标。
对于文本到音频检索,我们将每个音频的文本视为独立的测试样本,并在测试样本数量为测试集五倍的情况下计算文本到音频检索指标的平均值。在评估音频到文本召回率时,每个音频的召回率通过从五个文本标签中选取最佳的音频到文本检索结果来计算。此外,音频到文本平均精度均值(mAP)计算为 m A P @ 10 = 1 R ∑ r = 1 10 ( P ( r ) ∗ r e l ( r ) ) mAP@10=\frac{1}{R} \sum_{r = 1}^{10}(P(r) * rel(r)) mAP@10=R1∑r=110(P(r)∗rel(r)),其中 P ( r ) P(r) P(r)表示召回水平 r r r处的精度, r e l ( r ) rel(r) rel(r)是一个二进制指示符,用于表示召回水平 r r r处的文本是否相关。
在其他数据集(如Freesound)的情况下,每个音频样本仅关联一个文本,召回率和平均精度均值(mAP)以标准方式进行测量。
D.LAION - Audio - 630K的细节
关于论文的2.1节和2.2节:
- 我们在表5中列出了收集LAION - Audio - 630K音频样本和文本字幕的网站/来源的规格。
- 我们在表6中列出了三个数据集的详细信息。我们在提交的第4节中使用它们的组合来训练模型。
- 关于论文的3.4节,我们展示了Epidemic Sound和Freesound [31](作为LAION - Audio - 630K的一部分)上音频长度的分布,以证明音频数据处理和模型训练中可变长度问题的存在。
D.1.Freesound数据集
Freesound数据集中的样本收集自Freesound [31]。Freesound中的所有音频片段均根据知识共享(CC)许可发布,每个片段都有其在Freesound中由上传者定义的单独许可,其中一些要求对原始作者进行署名,一些禁止进一步商业再利用。具体而言,以下是LAION - Audio - 630K中涉及的音频片段许可的统计信息:
- CC - BY:196884
- CC - BY - NC:63693
- CC0:270843
- CC Sampling +:11556
我们在数据集发布页面列出了每个样本的许可。
E.注意力特征融合
关于论文的3.4节,我们展示了“注意力特征融合”架构,这是一个双分支CNN网络,以展示我们如何将输入音频的全局信息和局部信息结合在一起。
如图3所示,融合架构接受两个输入: X X X是全局信息( X g l o b a l a X_{global }^{a} Xglobala), Y Y Y是合并后的局部信息( X l o c a l a X_{local }^{a} Xlocala)。两个输入被发送到两个CNN网络以生成系数,然后 X X X和 Y Y Y通过该系数相加。
F.在Freesound数据集上的特征融合额外实验
关于论文的4.2节,为了进一步评估特征融合的有效性,除了AudioCaps和Clotho数据集之外,我们还在Freesound评估集上进一步评估我们的模型,该评估集包含超过10秒的音频样本(与Clotho数据集类似)。
结果如表7所示,符号表示与提交论文中的表3相同。Freesound数据集上的性能与Clotho数据集上的性能趋势相似:
- 在“AudioCaps + Clotho + LA.”上训练的性能优于在“AudioCaps + Clotho + LA. + AudioSet”上训练的性能。如4.2节所述,与Clotho类似,Freesound数据集包含与AudioSet不同的音频样本,将AudioSet添加到训练集中会使模型的分布从一般音频数据转移到类似AudioSet的音频数据,从而降低性能。
- 有特征融合的性能优于没有特征融合的性能,因为Freesound数据集包含大于10秒的样本,这与Clotho数据集相同。它们的性能趋势相似。
从上述实验中,我们可以进一步得出结论,特征融合可以提高可变长度音频样本上文本到音频任务的性能(即生成更好的音频表示)。
G.关键词转字幕增强的示例
关于论文的3.5节,我们在下面的表4中展示了一些由T5模型从AudioSet标签生成的关键词转字幕的示例,以及用于模型训练的去偏版本。
此外,在应用关键词转字幕时,我们排除了长度短于2秒的样本,因为我们发现在这种情况下音频仅仅是单个事件,与生成的字幕匹配度较差。在包括AudioSet的训练数据集中使用关键词转字幕时,我们仅使用由关键词转字幕生成的字幕,并排除由模板生成的字幕。
H.数据排除的实验设置
关于论文的4.3节,我们排除了所有重叠样本,并在整个剩余数据集上进行零样本评估。下表8显示了详细信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









