







非监督分类是以不同影像地物在特征空间中类别特征的差别为依据的一种无先验类别标准的图像分类,是以集群为理论基础,通过计算机对图像进行集聚统计分析的方法。根据待分类样本特征参数的统计特征,建立决策规则来进行分类。
目前PIE-Engine包括K均值分类与最大期望分类
k均值分类
K均值(K-means Clustering Algorithm)是一种迭代求解的聚类分析方法,易于描述、时间效率高且适于处理大规模数据,核心对象为pie.Clusterer.kMeans。
最大期望分类
最大期望(Expectation-Maximization)是一种通过迭代进行极大四让估计的优化算法,通常作为牛顿迭代法(Newton-Rapson method)的替代,用于含隐变量(latent variable)或缺失数据(incomplete-data)d的概率模型进行参数估计,核心对象为pie.Clusterer.em。
调用流程
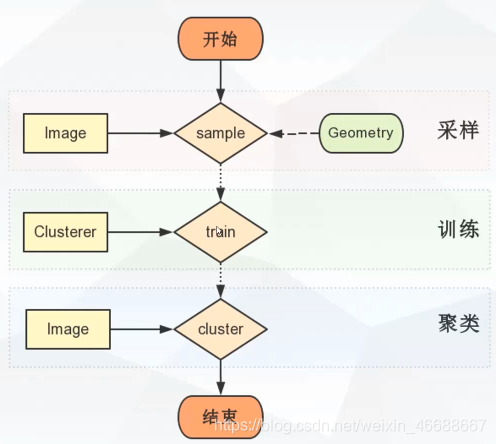
相关算子
sample
从Image中随机采样,返回结果是一个FeatureCollection,FeatureCollcetion下的每一个Feature中存储采样点的相应波段的信息。
函数sample(region,scale,projection,factor,numPixels,seed,dropNulls,tileScale,geometries)
返回值FeatureCollection
| 参数 | 类型 | 说明 |
|---|---|---|
| region | Geometry | 要进行采样的范围 |
| scale | Float | 图像采样比例尺 |
| projection | String | 未启用 |
| factor | Float | 采样横和纵方向的比例 |
| numPixels | Long | 采样的点的个数,当factor不为0的时候,其不起作用 |
| seed | Interger | 未启用 |
| dropNulls | Boolean | 未启用 |
| tileScale | Float | 未启用 |
| geometries | Boolean | 未启用 |
KMeans
函数kMeans(nClusters)
返回值PIEClustererKMeans分类器
| 参数 | 类型 | 说明 |
|---|---|---|
| nClusters | Int | 分类的数目 |
示例
var geometry = pie.Geometry.Polygon([[[116.953, 39.419], [117.078, 39.419], [117.078, 39.477],[116.953,39.477],[116.953, 39.419]]], null);
var image = pie.Image("user/101/public/Raster/GF1_Clip").select(["B1","B2","B3"]);
var training = image.sample(geometry 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









