









文章目录
前言
遥感图像处理(processing of remote sensing image data)
对遥感图像进行辐射校正和几何纠正、图像整饰、投影变换、镶嵌、特征提取、分类以及各种专题处理等一系列操作,以求达到预期目的的技术。
本节以一个具体遥感影像处理的案例——基于遥感影像的非监督分类,介绍一下使用Earth Engine对遥感影像进行非监督分类的具体操作流程。
一、非监督分类介绍
1. 定义
非监督分类(Unsupervised classification)
以不同影像地物在特征空间中类别特征的差别为依据的一种无先验(已知)类别标准的图像分类,是以集群(Cluster)为理论基础,通过计算机对图像进行集聚统计分析的方法。根据待分类样本特征参数的统计特征,建立决策规则来进行分类。而不需事先知道类别特征。把各样本的空间分布按其相似性分割或合并成一群集,每一群集代表的地物类别,需经实地调查或与已知类型的地物加以比较才能确定。是模式识别的一种方法。
2. 分类方法介绍
① 常用的遥感影像非监督分类方法有:K-mean方法、ISODATA迭代自组织分类、ISO聚类方法、最大似然法分类、Iso聚类非监督分类和主成分分析方法等,具体分类方法的详细介绍,此处不做补充,可自行百度查找。
② GEE中非监督分类的方法放在了ee.Clusterer里面,具体的分类方法如下图所示:
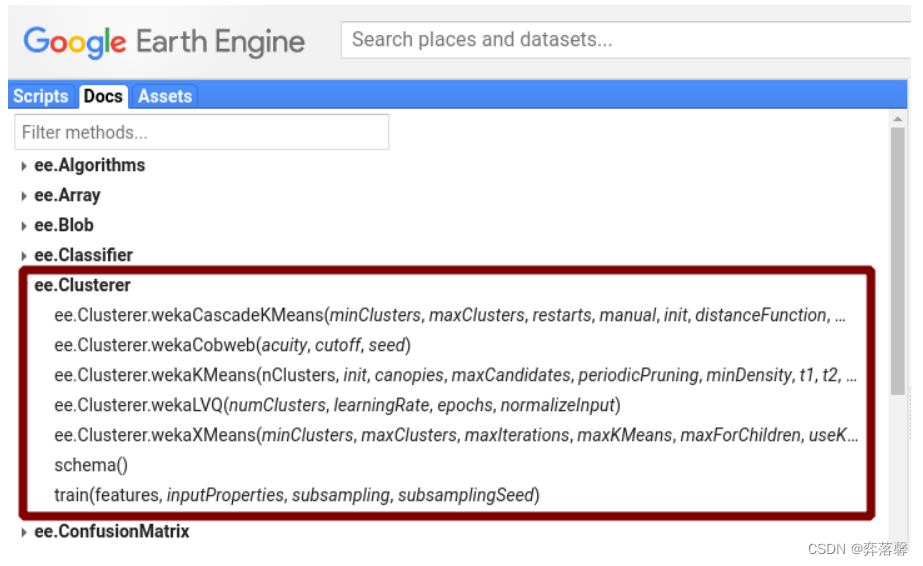
下面就来详细介绍一下,在geemap中如何进行遥感影像的非监督分类~
二、geemap中非监督分类详细步骤
本文列举的非监督分类案例主要包括以下八个部分:1)加载可交互地图底图;2)加载研究区影像数据;3)检查影像属性;4)选取训练数据集;5)训练集群(聚类中心点);6)影像分类;7)类别图例绘制及修改,分类结果可视化;8)分类结果修改。
1. 加载地图底图
首先,需要在jupyter notebook中加载可交互地图地图数据,详细代码如下所示:
# part 01 加载可交互地图底图数据
import ee
import geemap
Map = geemap.Map()
Map
2. 加载研究区影像数据
本案例的研究区选在了山东省东营市黄河三角洲国家级自然保护区中,加载研究区2020.08.01-2020.10.31植被生长季云量最少(云量筛选)的Landsat-8 SR影像,参与后续的非监督分类,详细代码如下:
#part 02 在地图上加载影像数据
point = ee.Geometry.Point([118.7719, 37.8799])
image = (
ee.ImageCollection('LANDSAT/LC08/C01/T1_SR')
.filterBounds(point)
.filterDate('2020-08-01', '2020-10-31')
.sort('CLOUD_COVER')
.first()
.select('B[1-7]')
)
vis_params = {'min': 0, 'max': 3000, 'bands': ['B5', 'B4', 'B3']}
#将某个点作为中心点进行缩放
Map.centerObject(point, 8)
Map.addLayer(image, vis_params, "Landsat-8")
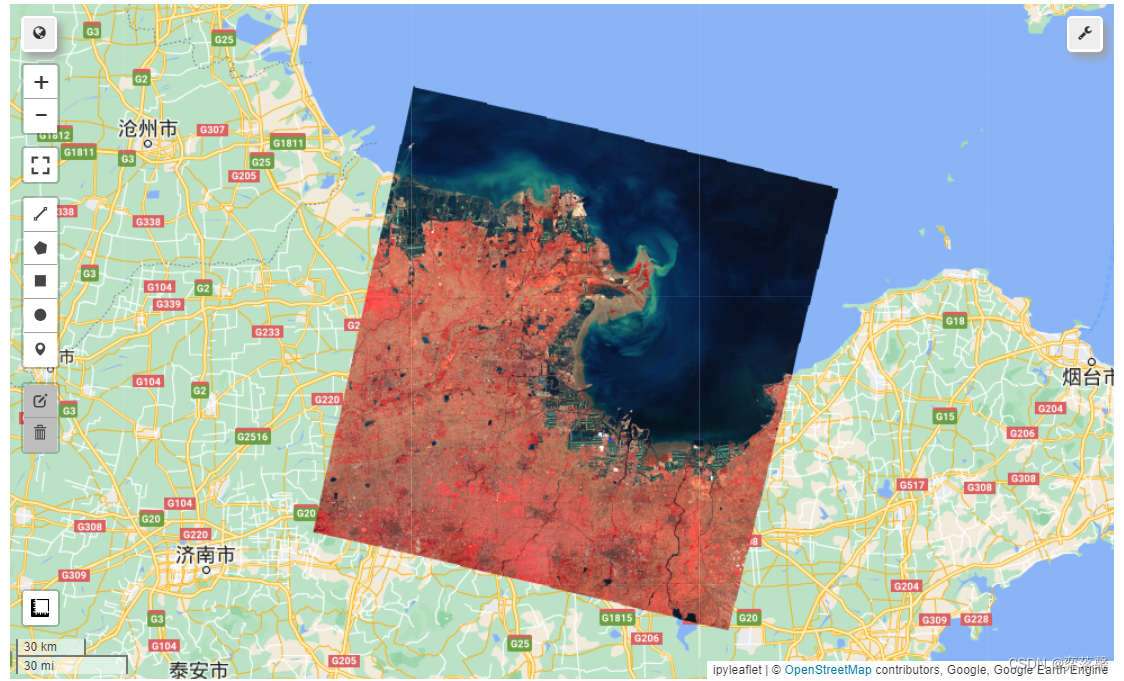
这里以筛选出研究区生长季云量最小的Landsat-8影像,进行假彩色可视化展示。
3. 检查影像属性
上文加载的云量最小的Landsat-8影像,并不知道影像的详细信息,如影像日期,影像编号,云量大小等信息,这里可以通过下述代码了解影像属性:
#part 03 检查影像属性
props = geemap.image_props(image)
props.getInfo()

如果只想知道其中某个属性情况,可参考以下代码:
① 获取影像日期信息
props.get('IMAGE_DATE').getInfo()

② 获取影像云量信息
props.get('CLOUD_COVER').getInfo()

4. 选取训练数据(聚类中心点)
非监督分类中初始聚类中心的选取也是非常重要的环节,对分类过程和分类结果均有重要影响,较好的初始聚类中心方法既能提高分类的效率又能提高分类的精度。具体的选取训练数据集的代码如下:
① 有四种方法可以创建用于生成训练数据集的区域范围。
# part 04 训练数据集
# 下面有几种方法可以创建用于生成训练数据集的区域。
# 1、在地图上画一个形状(如矩形)
# region = Map.user_roi
region = ee.Geometry.Rectangle([118.947946, 37.589509, 119.489846, 37.96002]) # 2、定义一个几何形状
# region = ee.Geometry.Point([118.7719, 37.8799]).buffer(10000) # 3、在中心点周围建立一个缓冲区
# 4、也可以直接在整个影像中选取训练数据随机点
② 训练数据选取,这里的训练样本随机点数量选择5000个点。
training = image.sample(
**{
'region': region, # 上面选择的训练样本点选择的区域(范围)
'scale': 30,
'numPixels': 5000,
'seed': 0,
'geometries': True, # Set this to False to ignore geometries
}
)
Map.addLayer(training, {}, 'training', False)
Map

5. 训练集群(聚类中心点)
选择训练数据集之后,需要对其进行聚类分析,这里的聚类器选择K-mean方法,聚类的类别为5类,具体代码如下:
# part 05 实例化聚类器并进行训练,利用K-mean聚类方法进行非监督分类
n_clusters = 5
clusterer = ee.Clusterer.wekaKMeans(n_clusters).train(training)
6. 影像分类
利用训练好的聚类器cluster,对整个选择的研究区进行分类,分成五个类别,详细的代码如下:
# part 06 影像分类
# 使用训练过的聚类对输入roi影像进行分类。
result = image.cluster(clusterer)
resultclip = result.clip(region)
# #使用随机颜色展示分类结果
Map.addLayer(resultclip.randomVisualizer(), {}, 'clusters')
Map

7. 分类结果类别颜色和图例修改
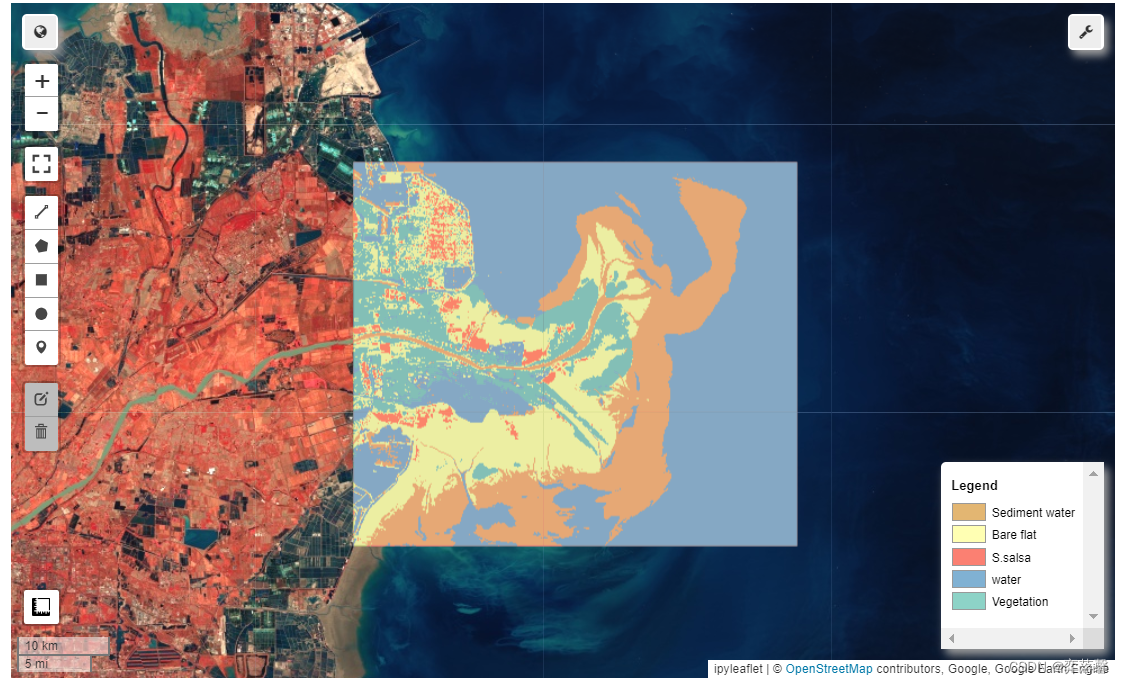
① 研究区通过非监督分类的五类类别分别为:纯净水体、浑浊水体、绿色植被、盐地碱蓬和光滩,根据类别的特点,修改对应类别的颜色,并添加图例,以达到较好的可视化效果,详细代码如下:
# part 7 分类图例修改
legend_keys = ['Sediment water', 'Bare flat', 'S.salsa', 'water', 'Vegetation']
# legend_colors = [ '#FB8072','#8DD3C7', '#FFFFB3', '#BEBADA', '#80B1D3']
legend_colors = [ '#E3B672','#FFFFB3', '#FB8072', '#80B1D3','#8DD3C7']
# Reclassify the map
result = resultclip.remap([0, 1, 2, 3, 4], [1, 2, 3, 4, 5])
Map.addLayer(
result, {'min': 1, 'max': 5, 'palette': legend_colors}, 'Labelled clusters'
)
Map.add_legend(
legend_keys=legend_keys, legend_colors=legend_colors, position='bottomright'
)
Map
② 为进一步增强分类结果的可视化效果,可以修改其分类结果的透明度,详细代码如下:
# 透明度可视化结果
print('Change layer opacity:')
cluster_layer = Map.layers[-1]
cluster_layer.interact(opacity=(0, 1, 0.1))

8. 分类结果导出
将非监督分类结果导出带自己的本地电脑中存储,详细代码如下:
# 将非监督分类结果图导出
import os
out_dir = os.path.join(os.path.expanduser('~'), 'Downloads')
out_file = os.path.join(out_dir, 'cluster.tif')
geemap.ee_export_image(result, filename=out_file, scale=90)

这里导出的路径为默认路径,也可以自行修改存储位置,存储路径中最好不要有中文。
总结
以上就是今天要讲利用geemap进行非监督分类的案例介绍啦,后续会继续更新利用geemap进行遥感影像监督分类的案例,尽请期待~















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









