







 本文介绍了Pyramid Vision Transformer (PVT)的升级版PVTv2,如何通过改进处理高分辨率输入、增强局部连续性和灵活性,以及CPVT的条件位置编码和Twins系列(如SVT)中空间注意力机制的创新。这些改进使得PVT在密集预测任务上取得显著提升,与Swin Transformer等竞争。
本文介绍了Pyramid Vision Transformer (PVT)的升级版PVTv2,如何通过改进处理高分辨率输入、增强局部连续性和灵活性,以及CPVT的条件位置编码和Twins系列(如SVT)中空间注意力机制的创新。这些改进使得PVT在密集预测任务上取得显著提升,与Swin Transformer等竞争。
PVT:《Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions》
论文: https://arxiv.org/abs/2102.12122
源码:https://github.com/whai362/PVT
把金字塔结构引入Transformer,简单地堆叠多个独立的Transformer encoder,
在每个Stage中通过Patch Embedding来逐渐降低输入的分辨率。
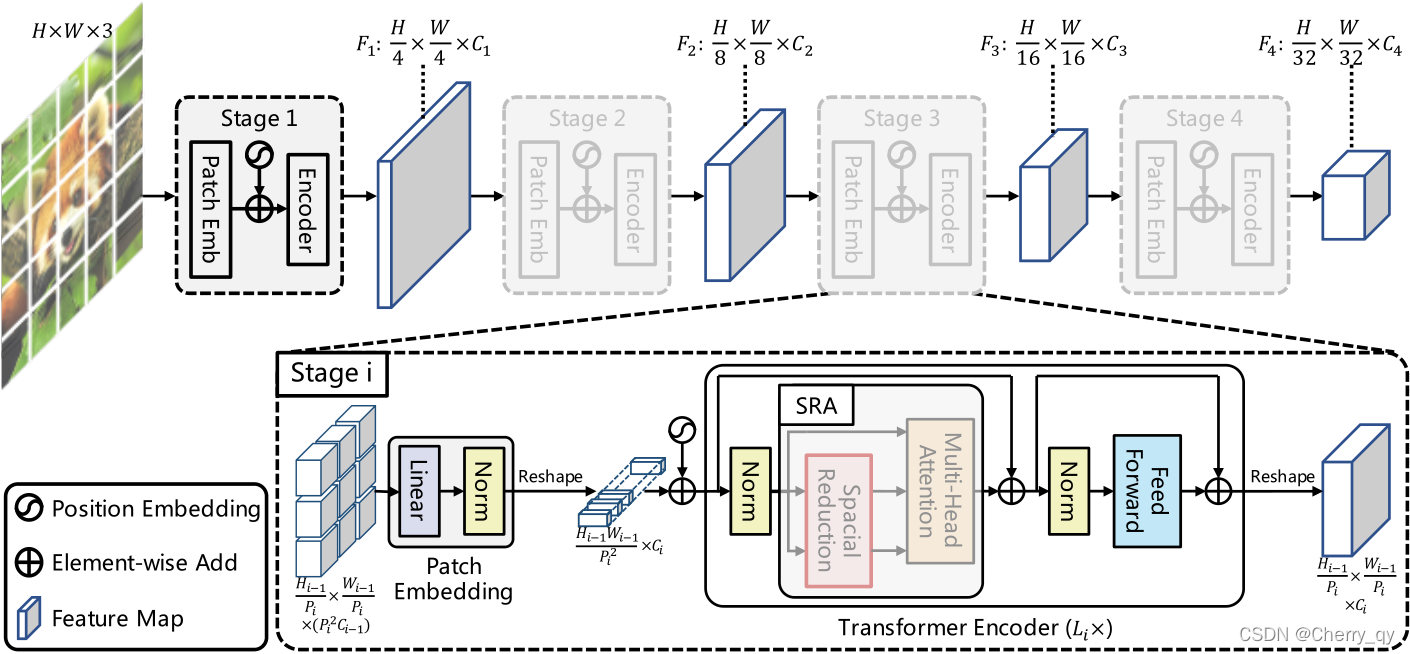
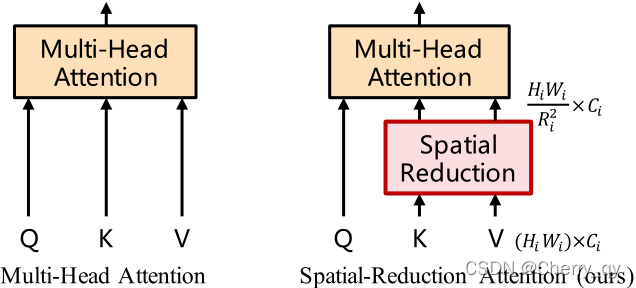
为了可以以更小的代价处理高分辨率(4-stride或8-stride)的feature map,我们对Multi-Head Attention也做了一些调整。为了在保证feature map分辨率和全局感受野的同时降低计算量,我们把key(K)和value(V)的长和宽分别缩小到以前的1/R_i。通过这种方法,我们就可以以一个较小的代价处理4-stride,和8-stride的feature map了。
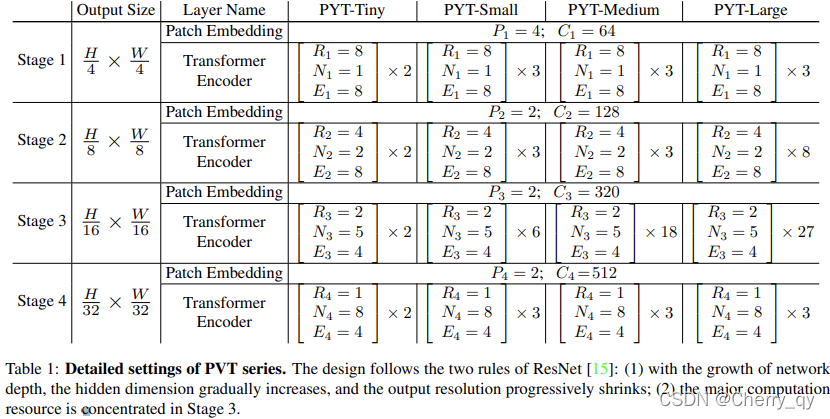
PVT v2:《Improved Baselines with Pyramid Vision Transformer》
论文: https://arxiv.org/abs/2106.13797
源码:https://github.com/whai362/PVT
PVTv1的主要局限性:(1)在处理高分辨率输入时计算复杂度大、(2)将图像视为不重叠的patch序列,一定程度上损失了图像的局部连续性、(3)不灵活的固定位置编码
对PVTv1改进:
Linear Spatial Reduction Attention
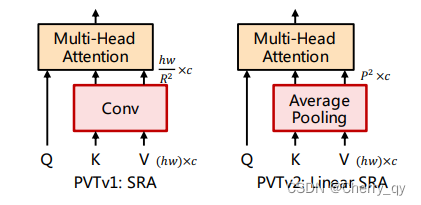
用LinearSRA替代SRA。这里需要说明的一个问题,作者在PVTv1中说自己没用到卷积,但是在压缩K、V的时候使用的是Conv2D(参见github中代码)。在PVTv2中使用平均池化替代Conv2D。
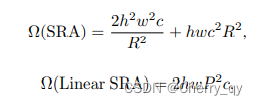
Overlapping Patch Embedding
为了对局部连续性信息进行建模,利用重叠的方式进行PE。扩大补丁窗口,使相邻的窗口重叠一半的区域,并对特征图进行零填充以保持分辨率。
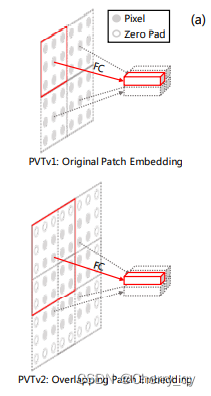
Convolutional FeedForward
在前馈网络中删除固定大小位置编码,并引入零填充位置编码。我们添加一个padding为1的深度卷积放置在第一个(FC)层和GELU之间。
总结:结合这些改进,PVTv2可以(1)获得更多的图像和特征图的局部连续性;(2)更灵活地处理变量分辨率输入;(3)具有与CNN相同的线性复杂度。
效果:PVTv2在分类、检测和分割等基本视觉任务上取得了显著的改进。值得注意的是,PVTv2与Swin Transformer等最近的作品相比,不相上下的性能。
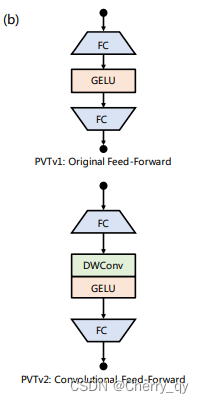
CPVT:《Conditional Positional Encodings for Vision Transformers》
论文地址: https://arxiv.org/abs/2102.10882
项目地址:https://github.com/Meituan-AutoML/CPVT
在PVT的基础上改进了位置编码,从原来的显式位置编码改成了隐式的根据输入而变化的可变长度位置编码(条件位置编码CPE)。CPE可以通过简单的位置编码生成器PEG来实现,并可以直接集成到Transformer框架中。
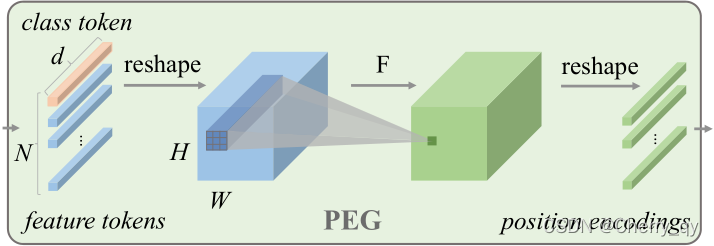
在 PEG 中,将上一层 Encoder 的 1D 输出变形成 2D,再使用变换模块F学习其位置信息,最后重新变形到 1D 空间。这里的变换单元(F)可以是 Depthwise 卷积、Depthwise Separable 卷积或其他更为复杂的模块。
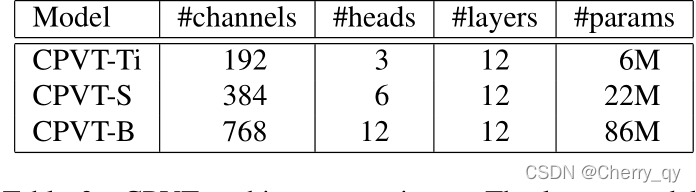
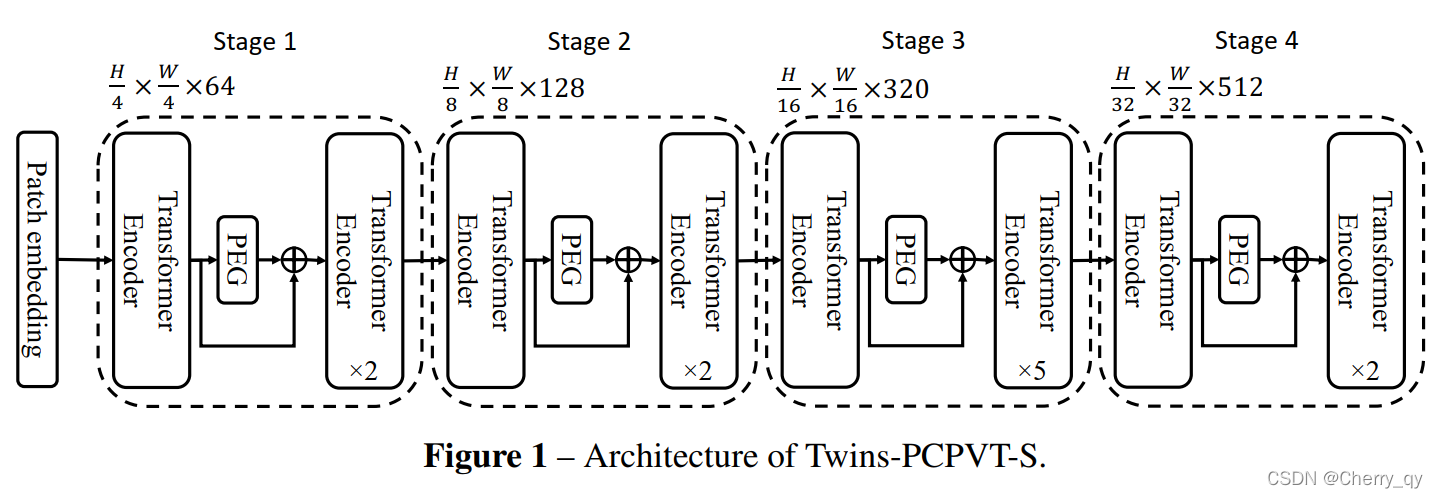
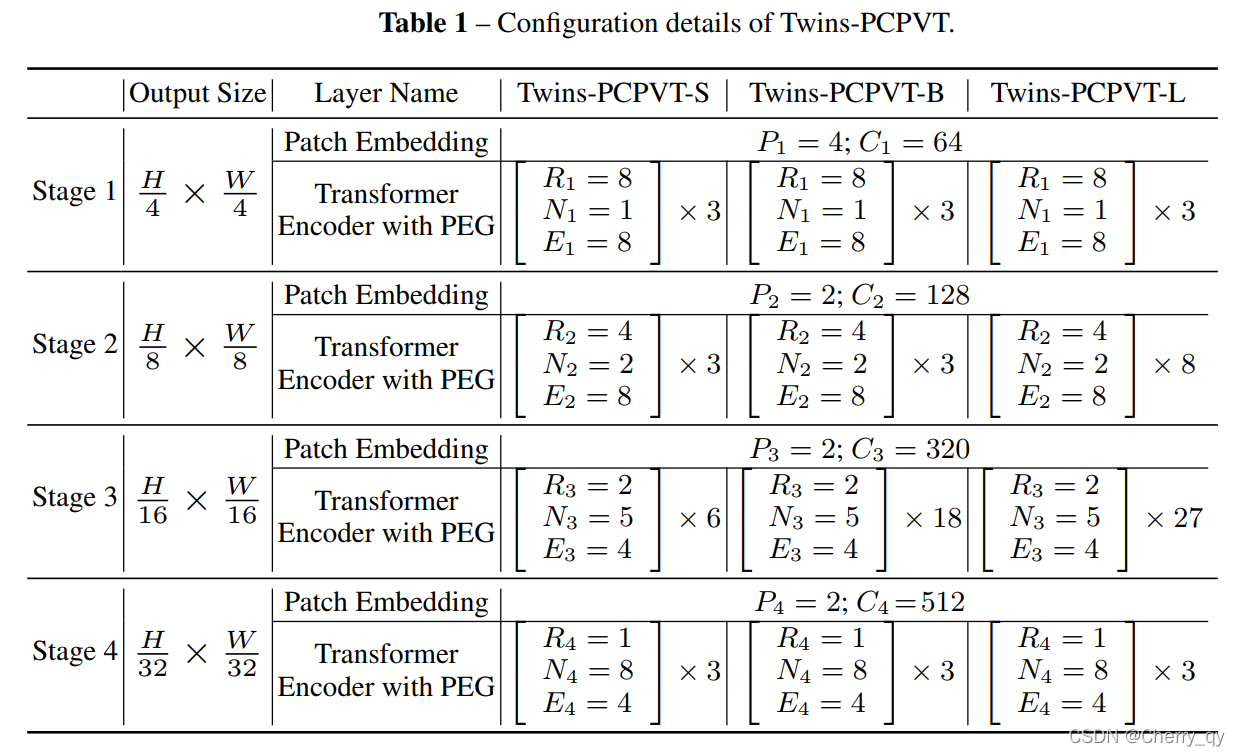
Twins-PCPVT
https://arxiv.org/abs/2104.13840
https://github.com/Meituan-AutoML/Twins
作者发现,拥有全局注意力、高分辨率、大感受野的PVT在dense prediction tasks性能却不如不如Swin-Transformer这种基于局部滑动窗口的模型,原因是PVT使用了absolute positional encodings。这种绝对位置编码在处理不同大小的输入图片时遇到了困难(这在密集预测任务中很常见),而且这种绝对位置编码也破坏了translation invariance(平移不变性);而Swin-Transformer则使用了relative positional encodings避开了上述问题。
因此,Twins-PCPVT转而使用了CPVT中的 conditional position encoding(条件位置编码CPE)来替代PVT中的绝对位置编码。CPE以输入为条件,可以避免绝对编码的上述问题。PEG位置编码生成器会生成条件位置编码CPE并将其置于每个阶段的第一个encoder block之后,本文使用了最简单的PEG形式,即不需要带有batch normalization的二维深度卷积。
对于图像分类任务而言,和CPVT一样,删除class token并在最后使用GAP全局平均池化。
对于其他视觉任务而言,Twins-PCPVT模仿了PVT的设计,且继承了PVT和CPVT的优点。
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
# 在传统 PVT 中,位置编码为 0
class PosCNN(nn.Module): #本文使用的条件位置编码
def __init__(self, in_chans, embed_dim=768, s=1):
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim), )
#使用的是一个非线性卷积操作
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
x = self.proj(cnn_feat) + cnn_feat #其实位置编码相当于前半部分,由于本函数直接输出 x,所以在内部已经进行了加和
x = x.flatten(2).transpose(1, 2) #回到原来的形状
return x
Twins-SVT
Transformer面临的最大问题是稠密预测导致的大计算量,所以作者进一步提出了一个新的空间注意力机制。
受到了深度可分离卷积(depthwise separable convolution)的启发,将本文的注意力机制命名为空间可分离自注意力[spatially separable self-attention(SSSA)],也就是对特征的空间维度进行分组计算各组的注意力,然后再从全局对分组注意力结果进行融合。
SSSA由两部分组成:
(1)局部分组注意力[locally-grouped self-attention(LSA)] 捕获细粒度和短距离信息
(2)全局子采样注意力[global sub-sampled attention(GSA)] 处理长距离和全局信息
SSSA使用局部-全局注意力交替的机制,可以大幅降低计算量。

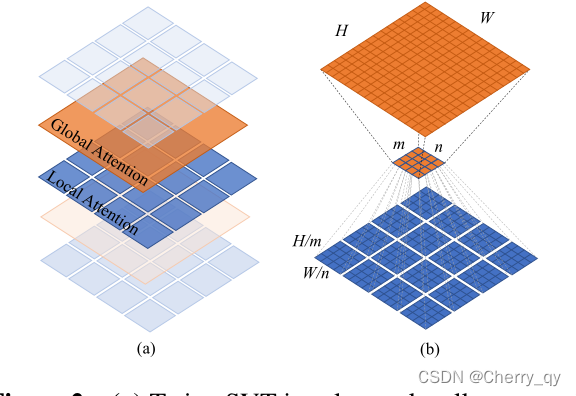
LSA:
将2D特征图划分为m*n个sub-windows,k1=H/m,k2=W/n。
自注意力只发生在每一个sub-window内。下采样使用卷积。
每个window的自注意复杂度为O(H²W²d / m²n²),所有子窗口的自注意复杂度为O(H²W²d / mn),也可以写成O(k1k2HWd)。划分的子窗口越多,时间复杂度越低,但不能太多。

虽说LSA机制比较computational friendly,但图像是被划分为不重叠的子窗口,这会导致信息被限制在局部处理,这意味着receptive field变小,而对于目标检测和分割这些dense prediction而言,小感受野是不能被接受的,同时也意味着我们不能将所有的standard convolution标准卷积替换为depth-wise convolution深度卷积。因此,为了像Swin-Transformer一样让每个子窗口的自注意矩阵交互,需要引入GSA。
GSA:
考虑到对不同子块进行交互,最简单的解决方式就是在每层local attention block后面,添加一个额外的标准全局Self-attention层。但计算量很大,为O(H²W²d)。
改进:使用一个有代表性的值来代表每个sub-window的重要信息,并用这个值与其他sub-window进行交互,那么全局attention的计算量就是O(H²W²d / k1k2 + k1k2HWd)。一般取k1=k2,作者设定stage1的特征图大小为56*56,故k1=k2=根号下56=7。
从代码来说,GSA 和PVT 里原来的注意力模块一样,上采样下采样操作都存在于 LSA 中。 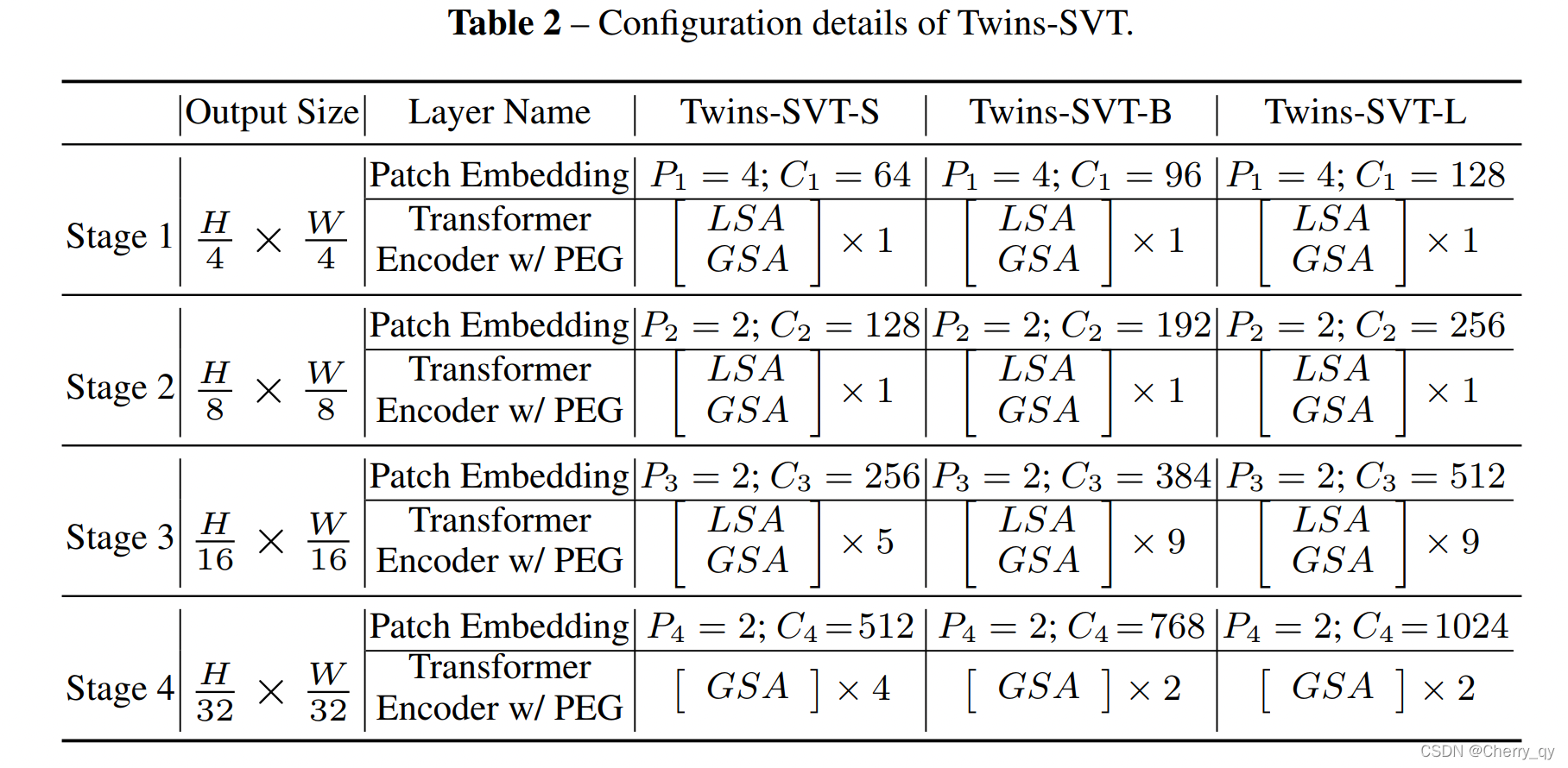



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









