







 EdgeViTs是香港中文大学和三星推出的新一代轻量级视觉Transformer,旨在与最佳轻量级CNN竞争。通过引入Local-Global-Local (LGL)瓶颈,该模型在计算效率和准确性之间取得平衡,降低了Self-attention的复杂度。在图像分类、目标检测和语义分割任务中,EdgeViTs在移动硬件上的性能优于其他高效的CNN和ViTs。实验显示,EdgeViTs在延迟和能源效率方面具有优势。
EdgeViTs是香港中文大学和三星推出的新一代轻量级视觉Transformer,旨在与最佳轻量级CNN竞争。通过引入Local-Global-Local (LGL)瓶颈,该模型在计算效率和准确性之间取得平衡,降低了Self-attention的复杂度。在图像分类、目标检测和语义分割任务中,EdgeViTs在移动硬件上的性能优于其他高效的CNN和ViTs。实验显示,EdgeViTs在延迟和能源效率方面具有优势。
EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
CVPR2022
论文: https://arxiv.org/abs/2205.03436
超越MobileViT!港中文&三星提出EdgeViT:轻量级视觉Transformer新工作,可与最好的轻量级CNN竞争!
Introduction
在计算机视觉领域,基于Self-attention的模型(ViTs)已经成为CNN之外的一种极具竞争力的架构。
尽管越来越强的变种具有越来越高的识别精度,但由于Self-attention的二次复杂度,现有的ViT在计算和模型大小方面都有较高的要求。
虽然之前的CNN的一些成功的设计选择(例如,卷积和分层结构)已经被引入到最近的ViT中,但它们仍然不足以满足移动设备有限的计算资源需求。
这促使人们最近尝试开发基于最先进的MobileNet-v2的轻型MobileViT,
但MobileViT与MobileNet-v2仍然存在性能差距。
本文引入了EdgeViTs,一个新的轻量级ViTs家族,也是首次使基于Self-attention的视觉模型在准确性和设备效率之间的权衡中达到最佳轻量级CNN的性能。
引入一个基于Self-attention和卷积的最优集成的高成本的local-global-local(LGL)信息交换瓶颈来实现。对于移动设备专用的评估,不依赖于不准确的FLOPs的数量或参数,而是采用了一种直接关注设备延迟和能源效率的实用方法。
在图像分类、目标检测和语义分割方面的大量实验验证了EdgeViTs在移动硬件上的准确性-效率权衡方面与最先进的高效CNN和ViTs相比具有更高的性能。
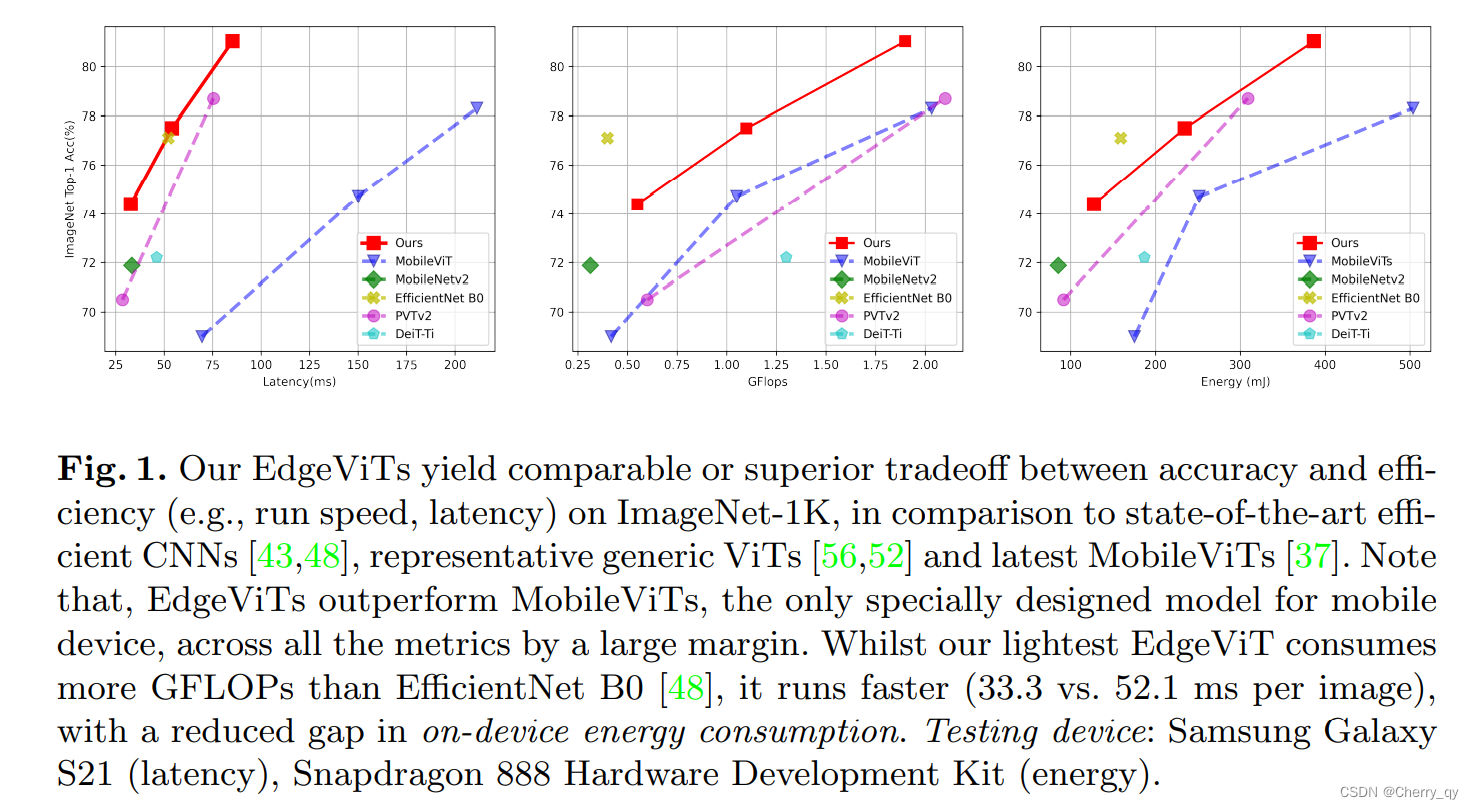
EdgeViTs
1.1 总体架构
为了设计适用于移动/边缘设备的轻量级ViT,作者采用了最近ViT变体中使用的分层金字塔结构(图2(a))。Pyramid Transformer模型通常在不同阶段降低了空间分辨率,同时也扩展了通道维度。每个阶段由多个基于Transformer Block处理相同形状的张量,类似ResNet的层次设计结构。
基于Transformer Block严重依赖于具有二次复杂度的Self-attention操作,其复杂度与视觉特征的空间分辨率呈2次关系。通过逐步聚集空间Token,Pyramid Transformer可能比各向同性模型(ViT)更有效。
在这项工作中,作者引入了一个Local-Global-Local(LGL) Bottlneck(图2(b))。LGL通过一个稀疏注意力模块进一步减少了Self-attention的开销(图2(c)),实现了更好的准确性-延迟平衡。
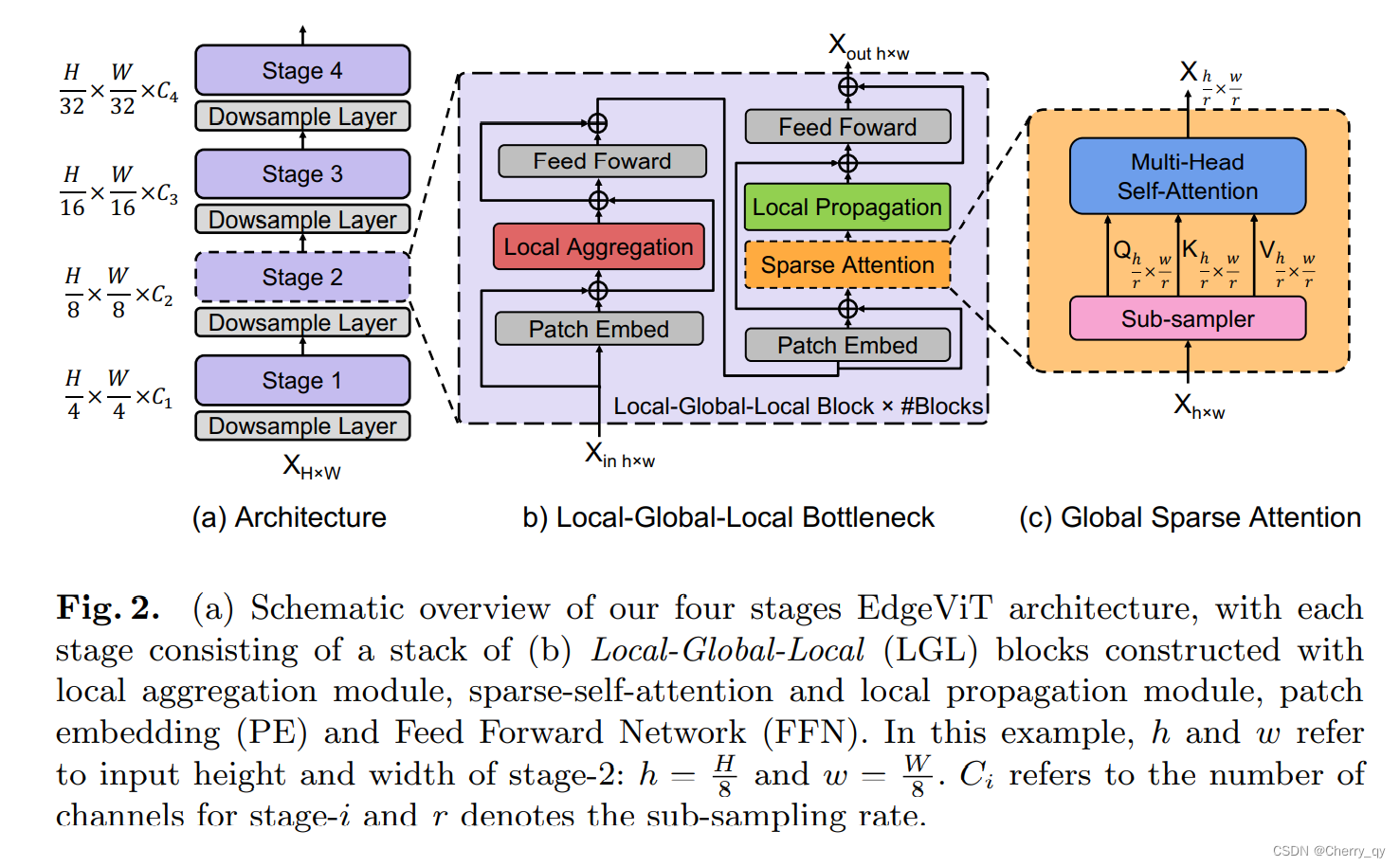
1.2 Local-Global-Local bottleneck
Self-attention是非常有效的学习全局信息或长距离空间依赖性的方法。
由于图像具有高度的空间冗余(例如,附近的Patch在语义上是相似的),将注意力集中到所有的空间Patch上是低效的。
因此,与以前在每个空间位置执行Self-attention的Transformer Block相比,LGL Bottleneck只对输入Token的子集计算Self-attention。
为了实现这一点,作者将Self-attention分解为连续的模块,处理不同范围内的空间Token(图2(b))。
这里引入了3种有效的操作:
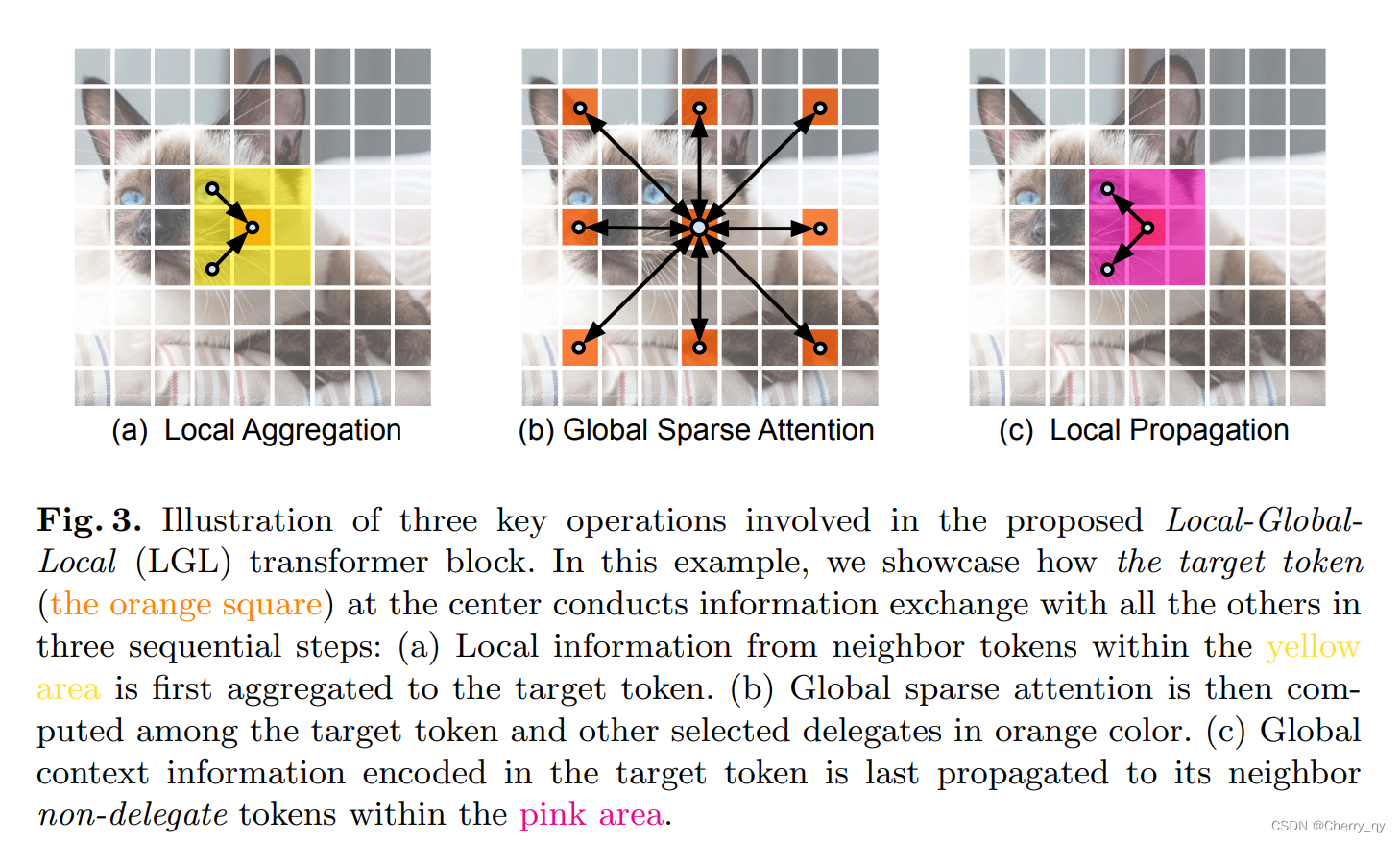
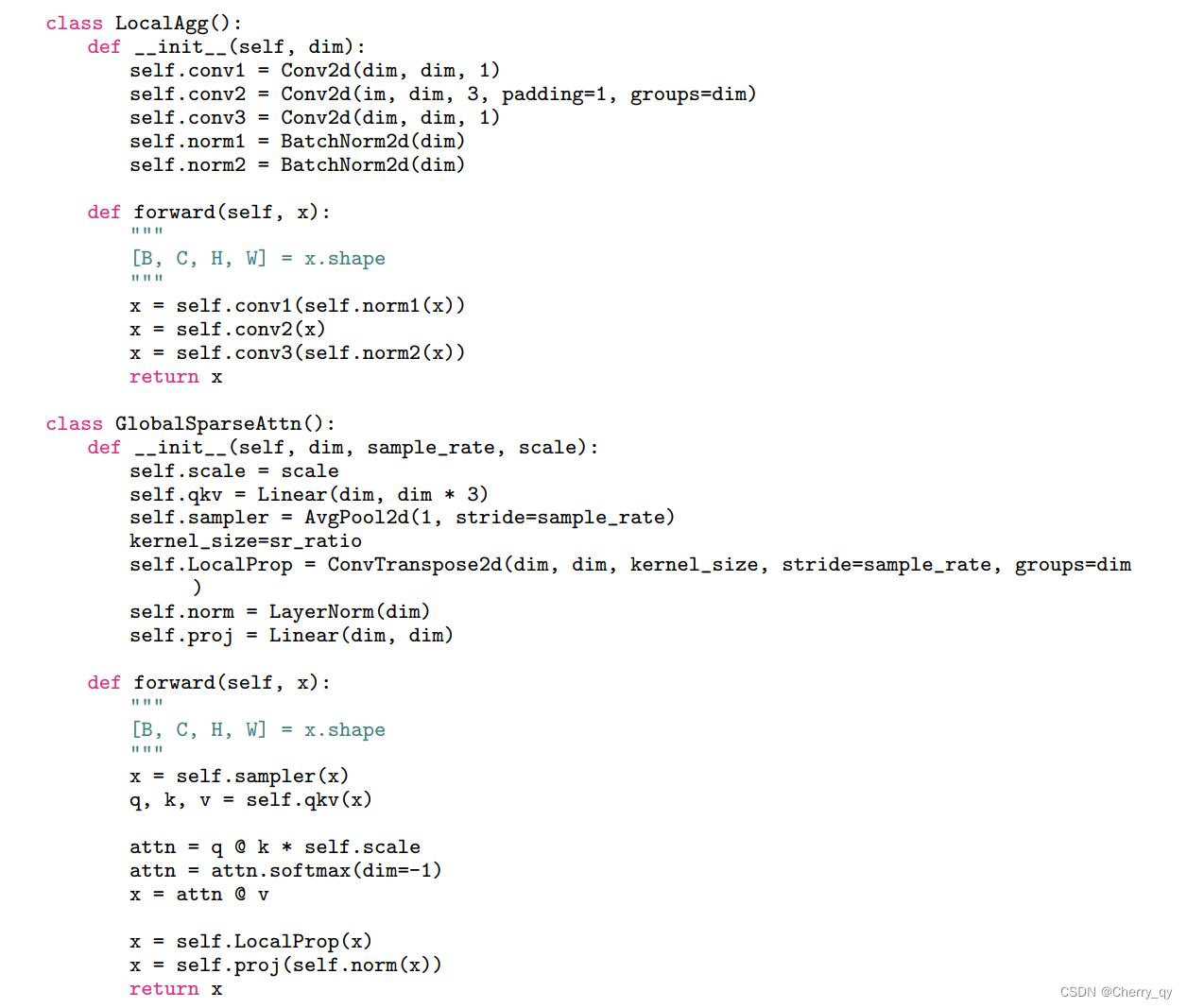
Local aggregation:仅集成来自局部近似Token信号的局部聚合,通过point-wise和depth-wise卷积在大小为k×k的局部窗口中聚合信息。
Global sparse attention:建模一组代表性Token之间的长期关系。对均匀分布在空间中的稀疏代表性Token集进行采样,每个r×r窗口有一个代表性Token。只对这些被选择的Token应用Self-attention。由四个阶段采样率为(4,2,2,1)的平均池化和标准MHSA组成。
Local propagation:将代表性Token中编码的全局上下文信息传播到它们的相邻的Token中,通过深度可分离转置卷积实现,其kernel大小和步长等于全局稀疏注意力中使用的采样率。
将这些结合起来,LGL Bottleneck就能够以低计算成本在同一特征映射中的任何一对Token之间进行信息交换。LGL bottleneck可以表达为:
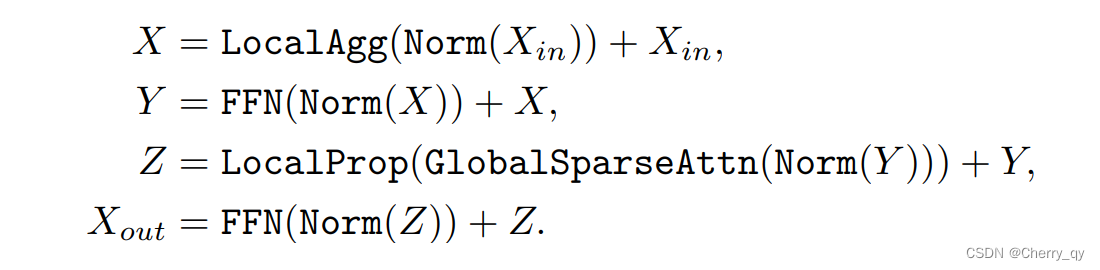
Norm是Layer Normalization操作。FFN由两个线性层组成,其中GeLU非线性激活函数位于两者之间。LocalAgg表示局部聚合算子。GlobalSparseAttn是全局稀疏Self-attention。LocalProp是局部传播运算符。
1.3 与其他经典结构的对比
LGL bottleneck与最近的PVTs和Twins-SVTs模型有一个相似的目标,这些模型试图减少Self-attention开销。然而,它们在核心设计上有所不同。
PVTs执行Self-attention,其中Key和Value的数量通过strided-convolutions减少,而Query的数量保持不变。换句话说,PVTs仍然在每个网格位置上执行Self-attention。
本文认为位置级Self-attention是不必要的,并探索由LGL bottleneck所支持的信息交换在多大程度上可以近似于标准的MHSA。
Twins-SVTs结合了Local-Window Self-attention和PVTs的Global Pooled Attention。这不同于LGL bottleneck的混合设计,LGL bottleneck同时使用分布在一系列局部-全局-局部操作中的Self-attention操作和卷积操作。
LGL bottleneck的设计在模型性能和计算开销(如延迟、能量消耗等)之间实现了更好的权衡。
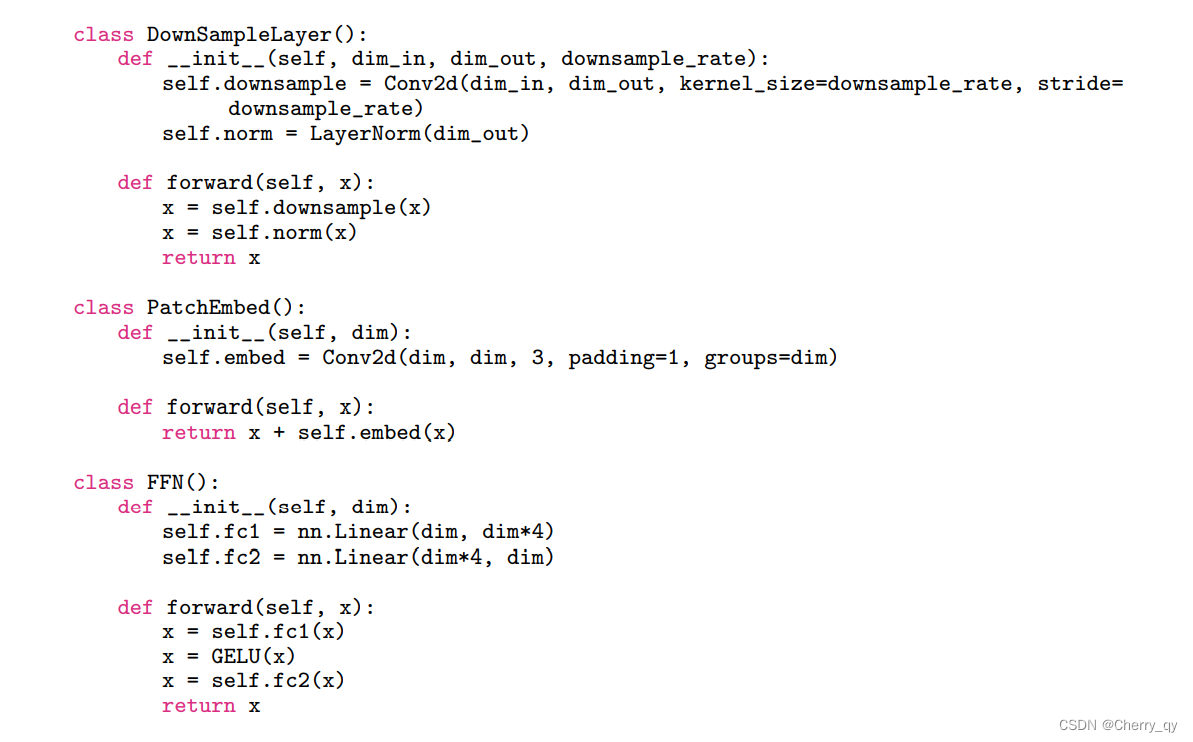
1.4 不同架构
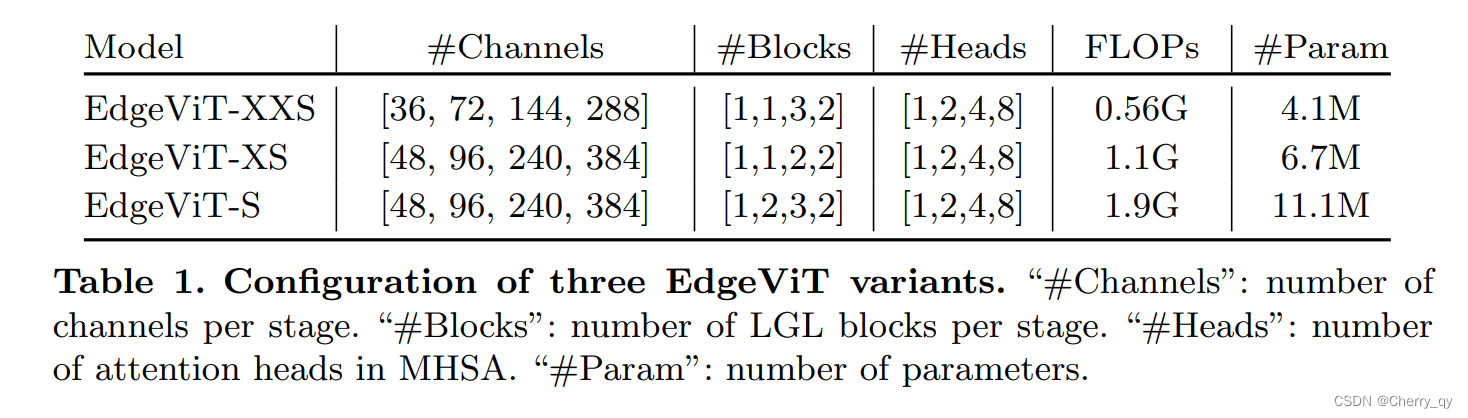
我们在不同的计算复杂度(具体为0.5G、1G和2G)下构建了一系列具有LGL bottleneck的EdgeViTs。
EdgeViTs由四个stage组成,自注意力模块逐渐减少,取而代之的是我们的LGL bottleneck。
每个阶段使用了一个2×2conv层下采样,步长为2,除了第一阶段,我们按×4下采样输入特征,并使用4×4和步长为4的核。
采用了条件位置编码,使用零填充的3×3 depth-wise卷积加上残差连接来实现。
Experiments
我们将EdgeViTs在多个视觉识别任务基准上进行实验。对于设备上的执行,我们在ImageNet上报告了所有相关模型的执行时间(延迟)和能耗。
分类任务
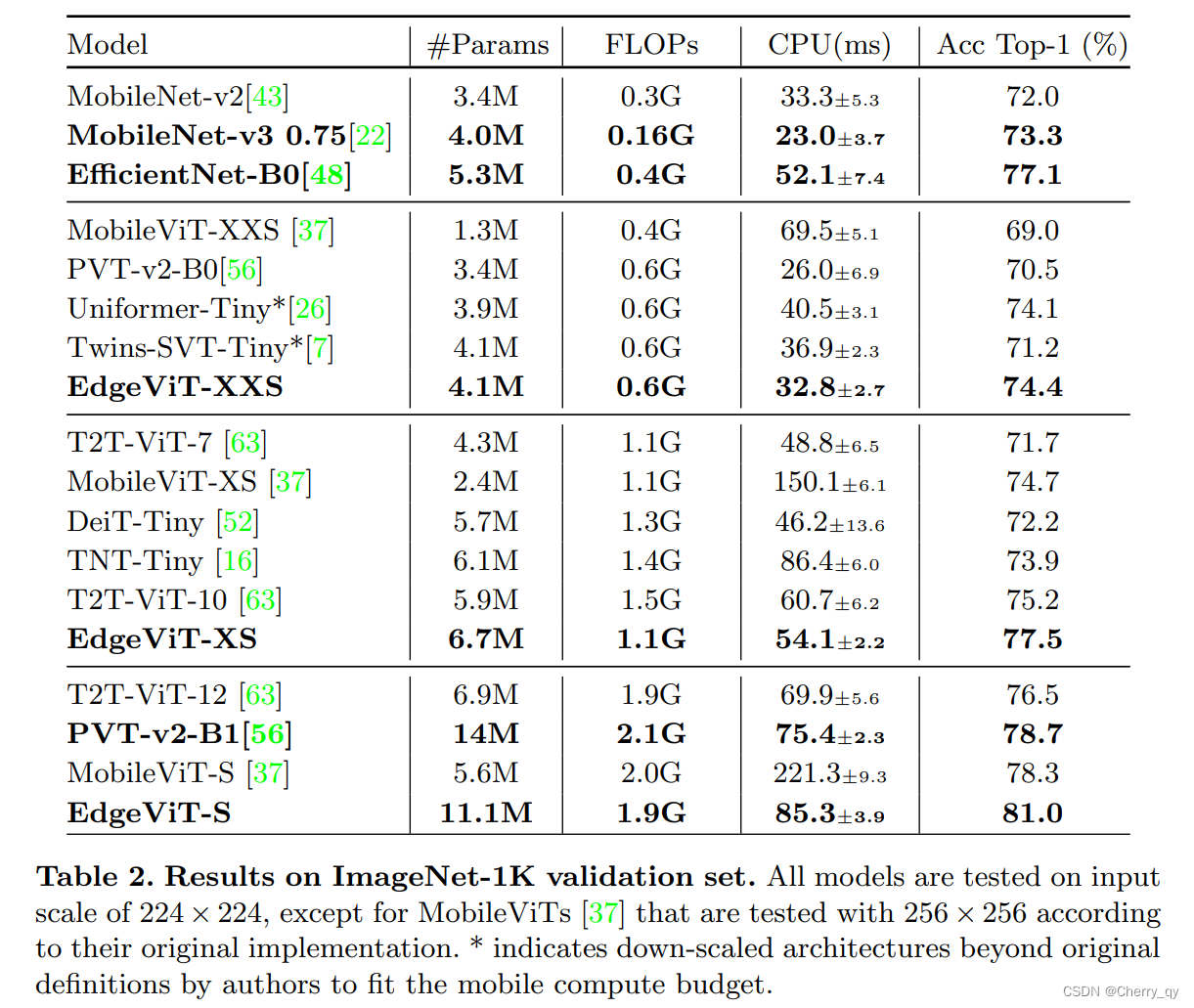
我们将EdgeViTs与各种基线模型进行比较,包括经典的高效CNN,例如MobileNetV2、MobileNetV3、EfficientNet和SOTA ViTs。
我们选择了复杂度小于2G FLOPS的基线,因为 i)在实际应用中,计算成本仍然是首要考虑的问题;ii)FLOPs是延迟的一个间接度量,它是以前工作中使用最多的开销度量。
i)EdgeViTs在GFLOPs复杂度相似的情况下显著优于其他轻量化ViT。和PVT-v2系列相比,我们的EdgeViT-XXS/EdgeViT-S比PVT-v2-B0/PVT-v2-B1提高了3.9%/2.3%。与MobileViTs相比,EdgeViTs在三种复杂度设置下分别实现了5.4%、2.8%和2.7%的收益。
ii)ViTs与CNN:我们的EdgeViTs提升了高效ViTs的性能,使其接近成熟高效CNN的水平。例如,EdgeViT-XXS在模型尺寸相似的情况下,性能优于MobileNet-v2和MobileNet-v3-0.75,但需要更多的GFLOP。
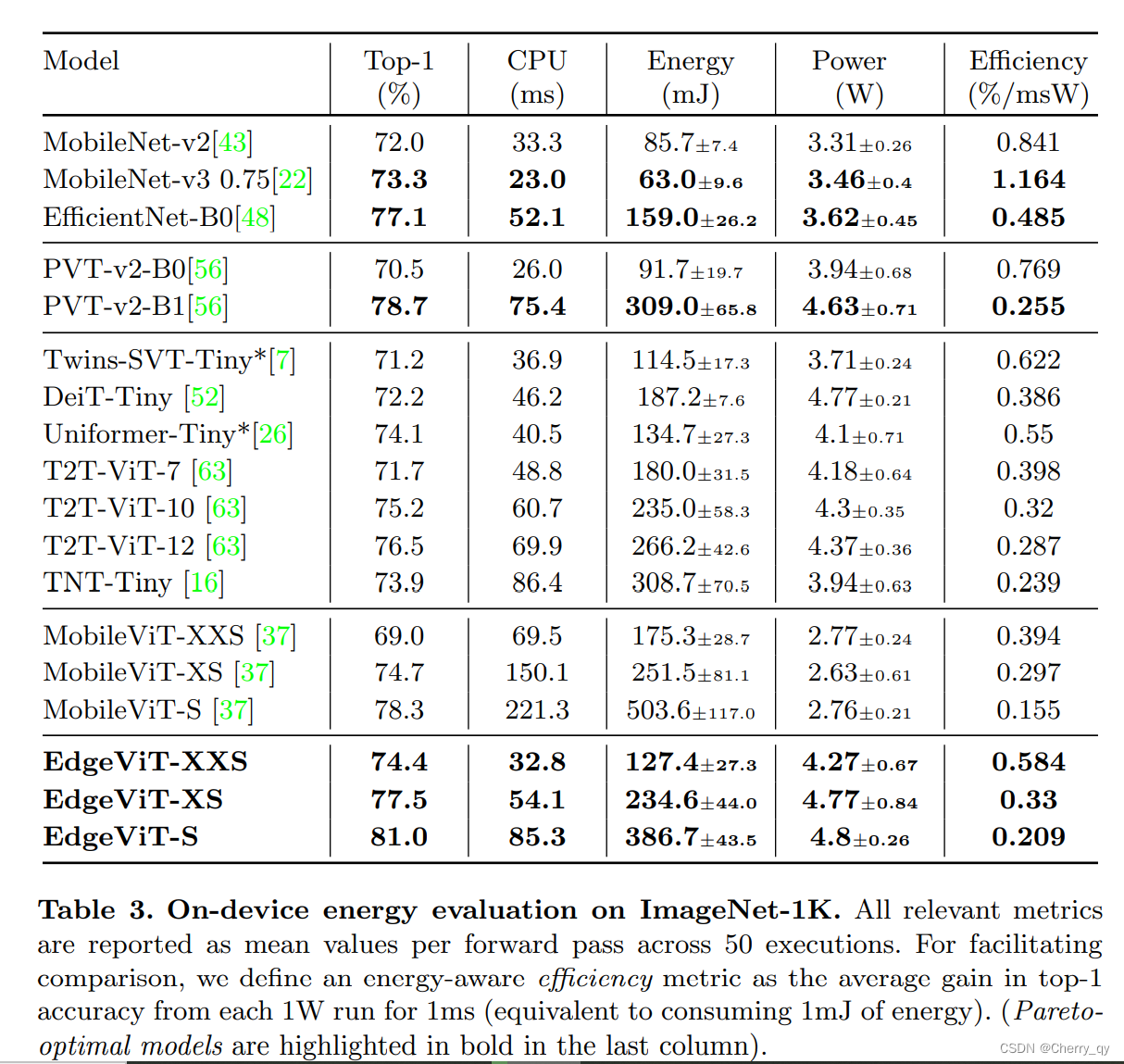
能量结果见表3。除了原始能量和功率数之外,为了比较简单起见,我们定义了一个能量感知度量参数efficiency,定义为每消耗1毫焦的能量实现的top1精度的平均增益。我们首先观察到,不太准确的模型往往更有效。这并不奇怪,因为精度的提高与模型复杂度成非线性关系。这也意味着,比较具有非常不同top1精确度的模型的效率,可能会产生严重的偏差。因此,我们将我们的比较限制在识别帕累托最优模型中。
我们可以看到,我们的EdgeViT能够优于几乎所有其他的ViTs,唯一的例外是PVTv2-B1,它的准确性和效率在我们的EdgeViT-S 和 EdgeViT-XS之间。
与cnn相比,我们的EdgeViTs可以与MobileNet-v3和Efficientnet-B0相竞争,虽然它们都更有效,但准确性也稍低。
EdgeViT模型尽管不如算法中最好的cnn有效,但实现了效率和准确性之间的最佳权衡,达到了相当高的准确度,而不牺牲效率。
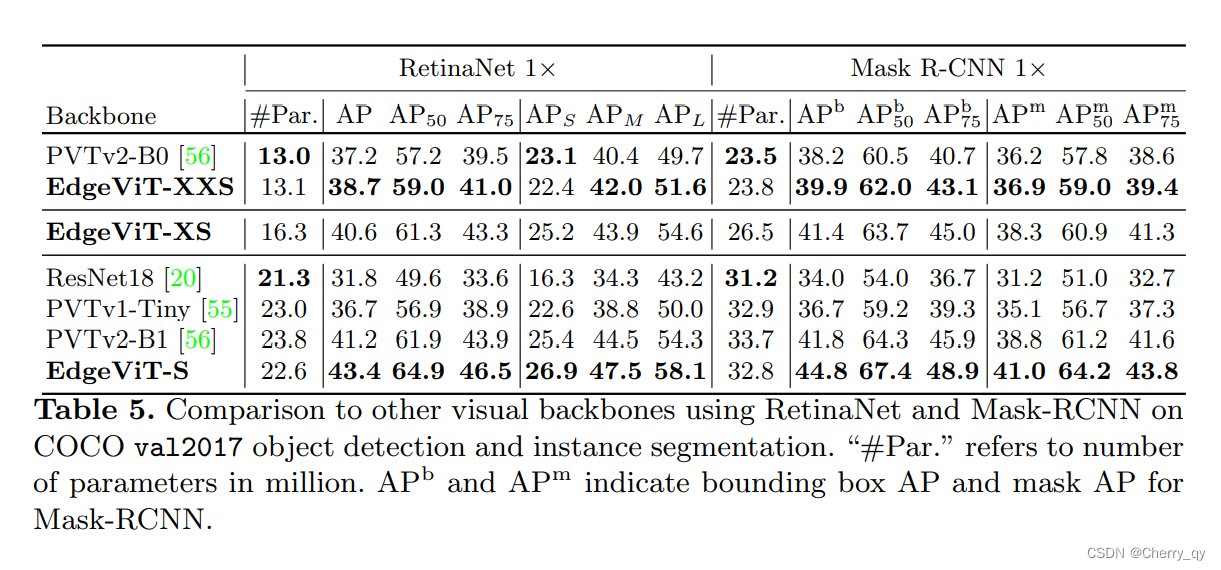
目标检测
使用EdgeViTs作为主模型的特征提取器,并使用之前实验中获得的ImageNet1K预训练权重对其进行初始化。
COCO目标检测/实例分割。EdgeViTs优于其他视觉骨干下的RetinaNet和Mask R-CNN。
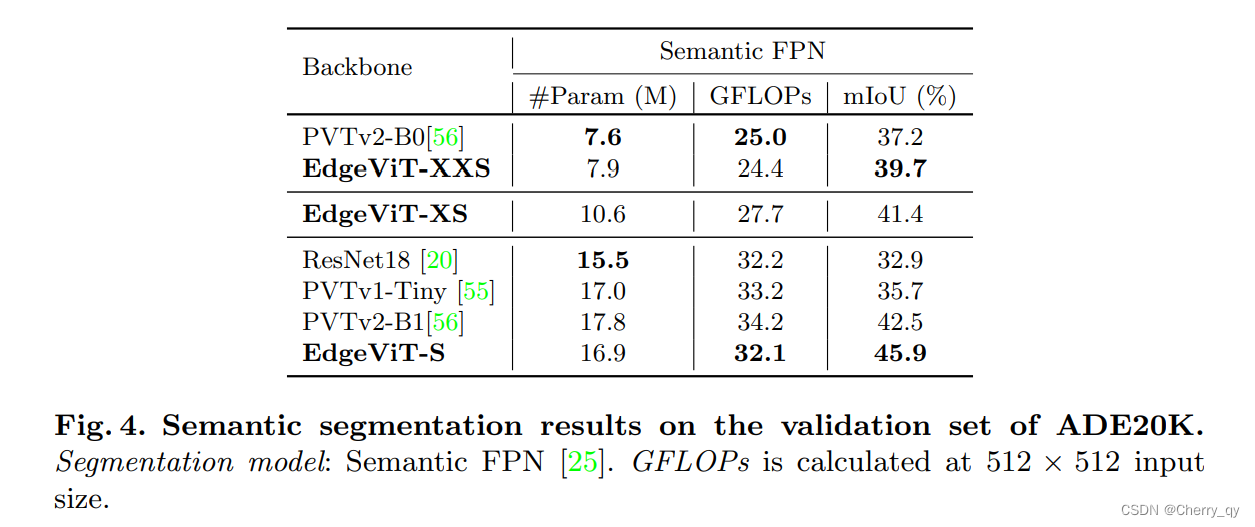
语义分割
将EdgeViTs与语义FPN框架内的CNN(ResNet-18)和基于Transformer的主干(PVT)进行了比较。EdgeViTs以同样的计算成本实现了比所有对手更好的性能。
消融实验
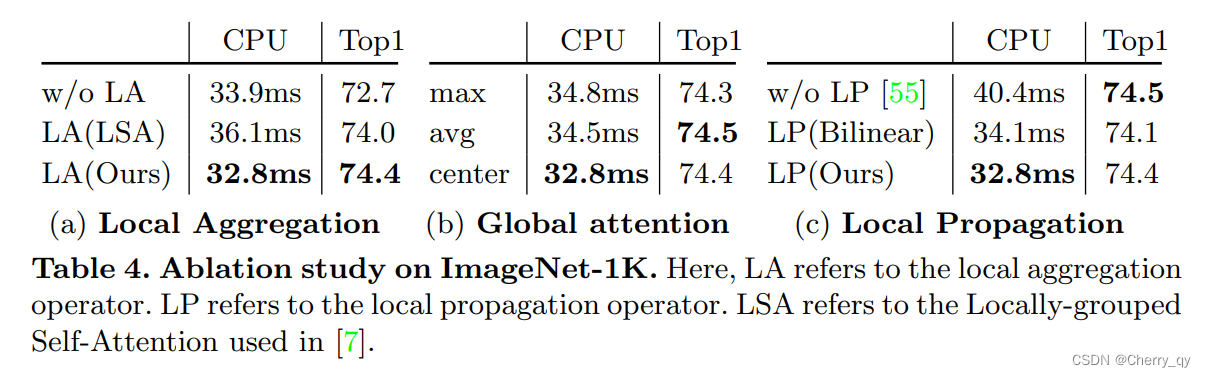
Local aggregation:
比较了不使用LA、使用LSA、使用本文的LA三种情况。实验证明选择深度卷积来实现LA是有效的并且效果最好。
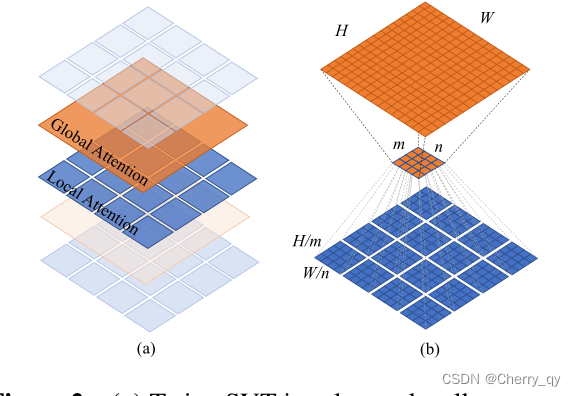
LSA指Twins提出的局部分组注意力[locally-grouped self-attention(LSA)]
LSA:将2D特征图划分为m*n个sub-windows,k1=H/m,k2=W/n。
自注意力只发生在每一个sub-window内。下采样使用卷积。
Global sparse attention:
比较max、avg和center三种选择,精确度相近,center在速度上有微弱的优势。
Local propagation:
Without LP:只对key和value进行降采样,query不进行下采样,从而保持空间分辨率不变。此时不需要LP。
bilinear:利用双线性插值来对delegate tokens进行上采样。
LP:采用本文中使用的深度可分离转置卷积。精确度与without LP相近,速度1.2倍提升。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









