






导入模块
import pandas as pd
import numpy as np读取CSV或TXT文本文件中的数据
1.创建一个.csv文件,命名‘data.csv’,内容如下:
A,B,C,D,animal
1,3,2,5,cat
2,3,5,2,dog
3,4,6,3,horse
2,7,4,3,duck
4,5,6,3,mouse
用read_csv()函数来读取.csv文件
csvframe = pd.read_csv('data.csv')
csvframe也可以用read_table()函数指定分隔符来读取.csv文件
pd.read_table('data.csv',sep = ',')返回

2.若csv文件没有表头,‘data1.csv’内容如下:
1,3,2,5,cat
2,3,5,2,dog
3,4,6,3,horse
2,7,4,3,duck
4,5,6,3,mouse
用read_csv()函数读取:
pd.read_csv('data1.csv',header=None)结果返回:

还可以直接指定表头
pd.read_csv('data1.csv',names=['A','B','C','D','animal'])返回

3.创建一个.txt文件,命名‘data.txt’,内容如下:
A B C D
1 3 2 5
2 3 5 3
3 4 6 3
用read_table()函数指定分隔符来读取.txt文件
pd.read_table('data.txt',sep='\s+')返回

若txt文件中有字母和数字揉在一起,需要抽取数字部分
创建一个.txt文件,命名‘data1.txt’,内容如下:
0sdA1PJgs2yu3
4gyu5HYV6iii7
8osgy9c10sA11
pd.read_table('data1.txt',sep='\D+',header=None,engine='python')返回

若要读取.txt文件排除指定行,创建一个.txt文件,命名‘data2.txt’,内容如下:
33vjedvy
srthtsh
trhsbtst
A B C D
1 3 2 5
nssrthh
2 3 5 3
3 4 6 3
pd.read_table('data.txt',sep='\s+',skiprows=[0,1,2,5])返回

4.从txt文件读取部分数据
创建一个.txt文件,命名‘data3.txt’,内容如下:
A B C D
1 3 2 5
nssrthh
2 3 5 3
3 4 6 3
33vjedvy
srthtsh
trhsbtst
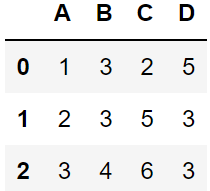
pd.read_table('data.txt',sep='\s+',skiprows=[2],nrows=3)
#跳过第3行(行索引为2);共读取3行数据(不算表头)返回
5.将数据写入csv文件
frame = pd.DataFrame(np.arange(16).reshape((4,4)),
index = ['red','blue','yellow','white'],
columns = ['ball','pen','pencil','paper'])
frame.to_csv('output.csv')输出一个csv文件:
,ball,pen,pencil,paper
red,0,1,2,3
blue,4,5,6,7
yellow,8,9,10,11
white,12,13,14,15
若存在空值,需要用指定值来替换,使用na_rep选项
frame = pd.DataFrame([[3,np.nan,np.nan,np.nan],
[9,np.nan,8,2],
[np.nan,np.nan,3,np.nan],
[8,3,1,np.nan]
],
index = ['red','blue','yellow','white'],
columns = ['ball','pen','pencil','paper'])
frame.to_csv('output1.csv',na_rep='0') #用0来替换空值输出一个csv文件:
,ball,pen,pencil,paper
red,3.0,0,0,0
blue,9.0,0,8.0,2.0
yellow,0,0,3.0,0
white,8.0,3.0,1.0,0
参考:
法比奥·内利. Python数据分析实战:第2版.北京:人民邮电出版社, 2019.11.















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









