






hadoop.aoache.org


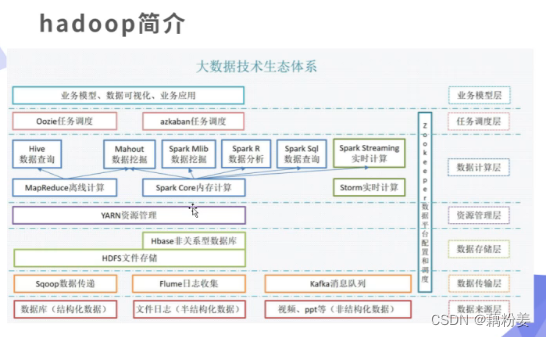
 SRE是懂运维的资深开发工程师
SRE是懂运维的资深开发工程师

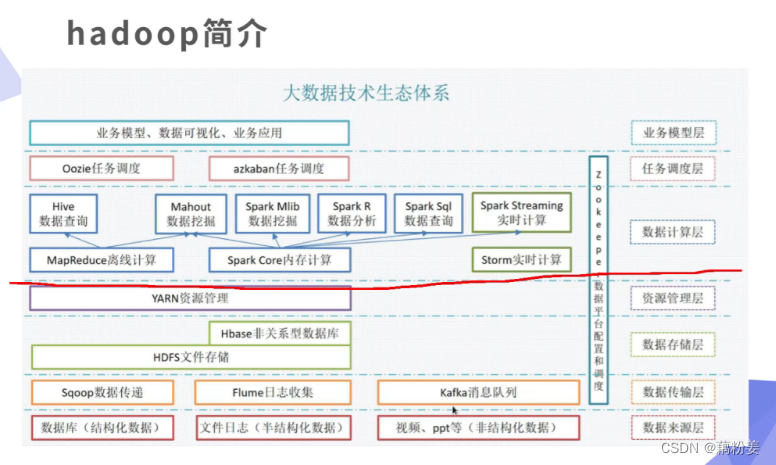
红线以下都是运维做的

进入官网

在这里下载版本
server1
tar zxf hadoop-3.2.1.tar.gz
tar zxf jdk-8u181-linux-x64.tar.gz
ln -s hadoop-3.2.1 hadoop
ln -s jdk-8u181/ java
cd hadoop
ls
cd etc/
ls
cd hadoop/
ls
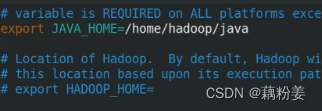
vim hadoop-env.sh#定义环境变量
cd ..
cd ..
cd /home/hadoop/hadoop
bin/hadoop 然后直接回车
mkdir input
cd etc/hadoop/*.xml input
ls input/
bin/hadoop jar
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
cd output/
ls
cat *
伪分布式模式,比如说我们这边没那么多节点,但是集群是在分布式上运行的。但是又没那么多节点,就在本机localhost上把分布式节点全部开启,运行的时候用分布式的方式运行,但是节点只有一个
cd ..
cd etc/
cd hadoop/
ls
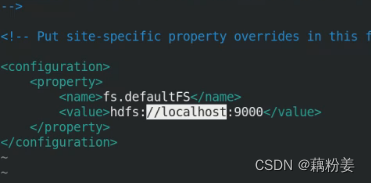
vim core-site.xml 核心的设置,定义作为分布式master是谁
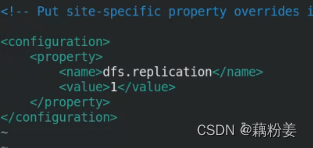
vim hdfs-site.xml 设置副本数
cat workers
ssh-keygen
cd
echo westos | passwd --stdin hadoop
su - hadoop
ssh-copy-id localhost
ssh localhost #免密
logout
cd hadoop
ls
bin/hdfs namenode -format #格式化
ls sbin/启动脚本
sbin/start-dfs.sh 表示只启动分布式管理系统,不启动管理器
cd
vim .bash_profile

Java耗内存,至少1024
source .bash_profile
jps拿到三个java经常
cat /etc/hosts java 主机名解析一定要做
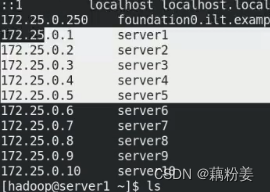
cd hadoop/
rm -fr output/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar
bin/hdfs dfs -report
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -ls #列出之前创建的用户目录
bin/hdfs dfs -put input
rm -fr input/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount input output #input是分布式系统里的目录,这个时候你是个客户端,它会自动调用,会自动读取etc,会在默认情况下会连接9000端口
172.25.0.1:9870
完全分布式
sbin/stop-dfs.sh #先停掉之前的进程。
jps
ps ax
1做Master ,2,3做worker
server1
ll /home/hadoop/所有文件都在这个目录下
yum install -y nfs-utils
systemctl enable --now nfs
vim /etc/exports
exportfs -rv

rw可写,来一个需要所有节点写进去的用户,应该是一个数组用户,就是权限问题,可能会涉及到不同的节点去修改,所有的节点修改的话,最好是在集群当中保证一个全平台的一致性,所有节点上面都应该拥有很多个这个用户,而且id一致。
2,3
yum install -y nfs-utils
useradd hadoop
id hadoop
mount 172.25.0.1:/home/hadoop/ /home/hadoop/
su - hadoop
ls
server1
ssh server2
logout
ssh server3
logout
cd hadoop/
cd etc/hadoop/
ls
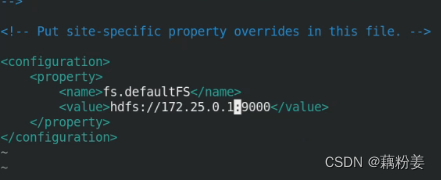
vim core-site.xml定义master
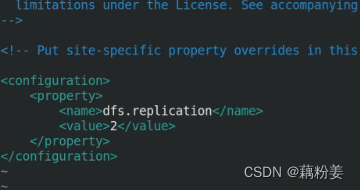
vim hdfs-site.xml 修改副本数为2
vim workers

cd /tmp/
ls
rm -fr *
cd
cd hadoop
ls
bin/hdfs namenode -format
ls /tmp/
sbin/start-dfs.sh
jps
172.25.0.1:9870
bin/hdfs dfs -ls
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -ls
bin/hdfs dfs -mkdir input
bin/hdfs dfs -ls
bin/hdfs dfs -put etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
bin/hdfs dfs -cat output/*
扩容节点
server4
yum install -y nfs-utils
useradd hadoop
showmount -e 172.25.0.1
mount 172.25.0.2:/home/hadoop/ /home/hadoop/
su - hadoop
server1
ssh server4
cd hadoop/
cd etc/hadoop/
vim workers增加节点server4
cd ..
cd ..
bin/hdfs --daemon start datanode
启动Yarn管理器,一般是用于分布式计算用的,是任务调度的管理器,专门做集群管理
cd etc/hadoop/
ls
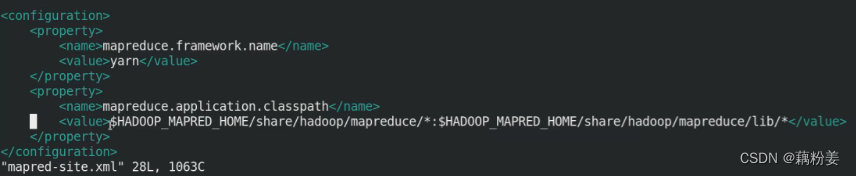
vim /mapred-site.xml
vim hadoop_env.sh
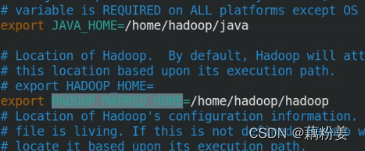
vim yarn-site.xml

cd ..
cd ..
sbin/ TAB键
sbin/start-yarn.sh
rm是资源管理器,nm是节点管理器
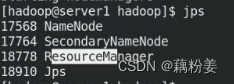
jps查看
master上有
worker上有
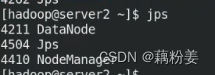
这些都是占资源的,生产环境中可以分离开
迁移数据快还是迁移计算快?迁移计算快。比如说,计算调度到serevr2上,运算可以在server3和4,因为数据离2近,它是数据分布式存储的。
在设计hadoop迁移计算的成本要远远地狱迁移数据存储
我们的计算和数据节点在一块是可以的,这样管理器也就起来了。
172.25.0.1:8088
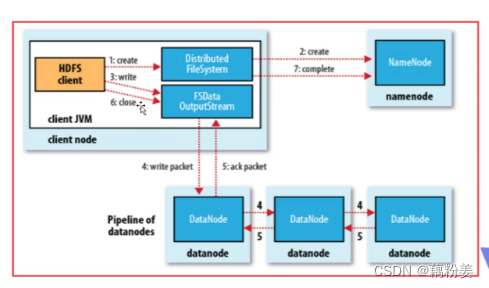
工作机制
mfs的使用方式是通过mount挂载的,我们在这个里面去写,就相当于本地的目录一样,但是hadoop是通过epi的方式访问的,会结合eclipse等工具加开发的客户端,在windows平台只需要卸载很多插件,就直接可以连接了。比如可以连接分布式文件系统,或者是运算
比如计算一个东西,这个里面会涉及到数据存储的问题,需要把计算内容推行到分布式文件系统中。
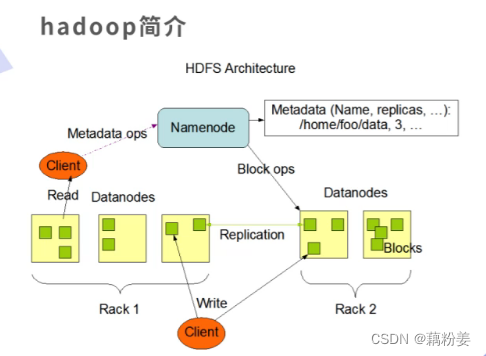
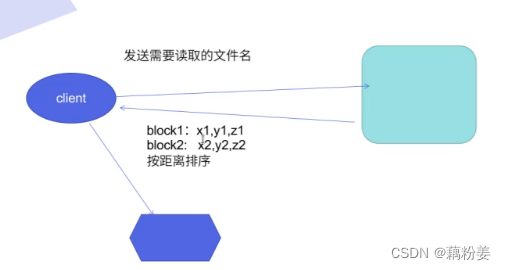
首先他会去向名称节点nn请求,如果要存储,他要分blog,因为nn上缓存了整个分布式文件系统的Node情况以及block情况,客户端回忆数据流的方式去写一个block,默认情况下block是128M,在block写完以后,在写一个节点的时候,可能会设置为多个副本,比如三个副本,他就会去复制其它的这个节点,这个复制不需要客户端走,而是集群自动的、预设的副本数,是由客户端设置的。

整个dhfs属于Master和slave结构,这个需要去做个哦可用,不然master挂了之后,就废了,默认存储机制是三份,对于容量的消耗,如果写1t的数据,就会消耗3t的存储和3t的带宽。系统也会提供相应的容错机制,有多个副本,容错机制就比较健全,只要其中有一个副本存在,就可以自动进行自动恢复,保证系统的高可用。它默认会把文件分成多个block,每个block的大小是可以设置的,我们默认是128M,也可以设置为256M,主要是看往分布式文件系统里面写的这个文件的大小,小文件太多会导致内存负担很重,对染hdfs支持压缩特性,hdfs不想mfs可以随便去进行变更,hdfs是针对海量大数据的,像离线的日志文件,我们不用修改它,hdfs针对的就是一次写入,朵儿服务的这种访问模型。

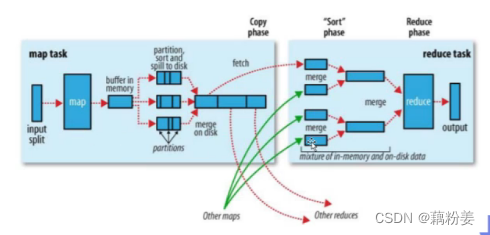
工作原理

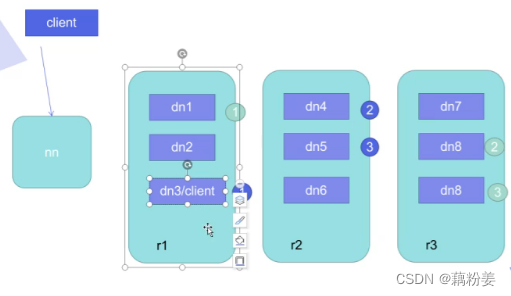
客户端分为两种,第一种是集群外的,第二种是可能和某个dn是在一块的。在这个返回列表的时候,是按照距离的远近来返回的。
如何判断?
对于客户端,它和dn是在一起的,那么它的第一个副本就一定和他的本机在一起,就是第一个副本肯定是存在本机的,因为本机最近,第二个副本要个第一个副本处于不同的机架上,上图中,r1,r2,r3代表不同的机架,有机架感应技术,可以得到节点是处于哪个机架的,这是为了得到机架的故障冗余,如果第一个机架出现故障,还有第二个机架能理解,这就是冗余,第三个副本和第二个副本要在同一个机架,但不能在同一个节点。不同的dn处于同一个机架上面,因为如果第二个副本出现故障的时候,第三个副本可以快速地去进行接管,为什么在同一个机架上,因为这样,就不用再出去了,直接在同一个机架上找另外一个dn就行,离得更近。这前三个副本是按照离我们的客户端远近顺序返回。
如果客户端是在集群外的,那它第一个副本就是随机分的,第二个副本和第三个副本和第一个副本不在同一台机架上,第三个副本和第二个副本在同一个机架上,对于客户端,拿到dn列表,就会找到第一个副本,将文件往上存,在存储的时候,要把一个大文件切成不同的block的小文件,这个文件要继续保持多少副本,是要在客户端上进行提交,这个在客户端配置文件中都写了,只要我们设置好就可以,开始发送第一个Block,是用数据包package的方式来发送,会把dn列表和数据一起发送到我们的dn上,当第一个列表发生故障的时候,就会把文件发生给第二个列表,假设dn接收完了,就会发生第二个block,直到文件发送完毕,在发送完第一个block时,就已经开始集群,自动同步到其他的dn上。
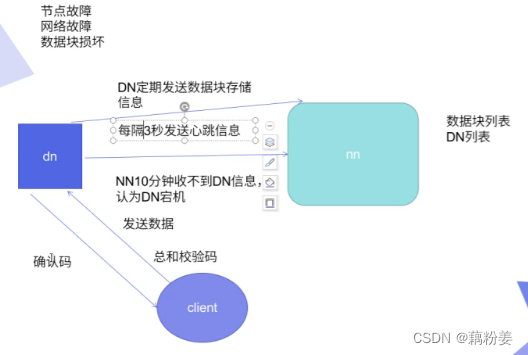
一个节点,每隔三秒心跳,如果十分钟收不到的话,就认为宕机了,通信故障这里会有一个响应确认,客户端会给钉钉发送数据,他会给我们一个确认码,客户端在传输数据的时候,会把总和校验码也发给dn,dn就可以通过总和校验码来确认数据的块的损坏情况,
rm的工作机制
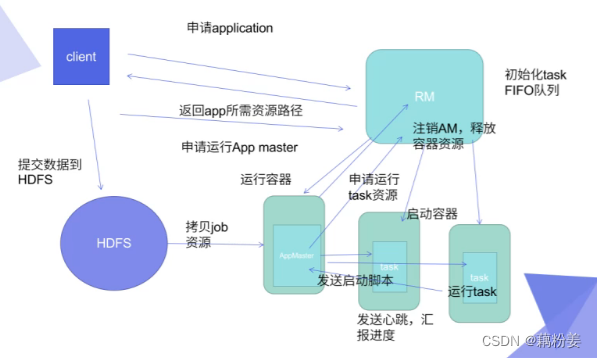
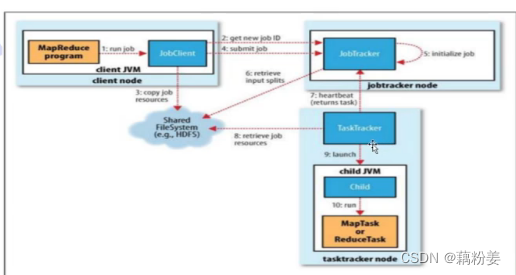
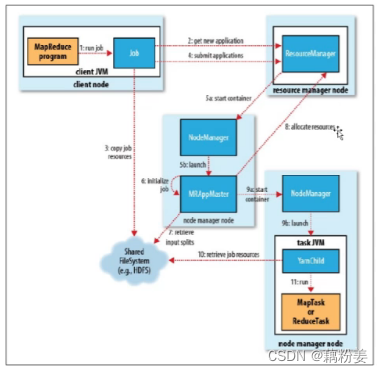
客户端,就是java开发工具,可以直接连接集群,在写完代码之后,可以直接提交申请,编码结束之后,需要运算一下,看有没有问题,连接好集群之后,rm开始初始化任务队列,会将客户端返回app所需的资源路径,客户端会把提交的数据方法hdfs,这样就分不到整个分布式文件系统上,客户端首先要向rm申请运行am资源,am就是java代码,会去申请am的运行的容器,这个容器和docker不同,是在java层面抽象出来的,是为了限制java的资源,就是运行am,分配的资源是通过这个容器来进行隔离的,就是限制做相应的限制,rm去申请,rm会给任务调度器给后端的某一个nm上面,nm会开启一个容器,来运行am代码,这个代码可以从dhfs分布式文件系统里面拷过来。
am是一个任务,跑这个任务需要很多节点,,如果分了两个,它会再次am向rm注册,注册am已经有地址了,因为已经运行了,首先会告诉rm,到时候客户端想要去拿这个任务的这个信息,直接连接am注册的这个地址就可以了,am向rm申请运行的task这个资源,rm会再次把这个任务分发到后端这个健康的nm上,就是Node manager,在节点管理器上启动相应的容器,这个容器任务由节点本身来进行监控和维护的,对于rm这块的资源消耗就是做调度,不像原来那样,就是什么事情都要我来做,相应的在这个调度版本中,rm可以承载更大的集群节点,
高可用
1和5作为高可用节点234作为dn节点,
这个高可用依赖外层的协调服务,zk就是rockyper,这个里面有一个active和standby.
还有一个进程是故障切换控制器。
server1
sbin/stop-all.sh
cd /tmp/
rm -fr *
因为节点数据默认的目录在tmp下,所有要把所有节点上的tmp目录下的文件清除掉。
server5
yum install -y nfs-utils
useradd hadoop
su - hadoop
server1
ssh server5
在234节点上把zk集群拉起来。
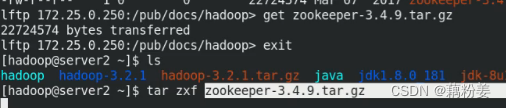
server2
ls
cd zookeerper-3.4.9/
ls
cd conf/
ls
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
mkdir /tmp/zookeeper
vim zoo.cfg
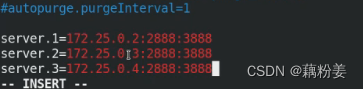
echo 1 > /tmp/zookeeper/myid#每个节点下的myid不同,server3,2,server4,3
cd ..
bin/zkServer.sh start 2,3,4都启动
jps
server1
cd
cd hadoop/
cd etc/hadoop/
vim core-site.xml
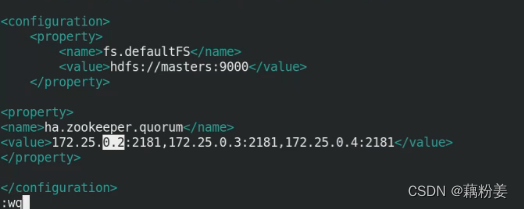
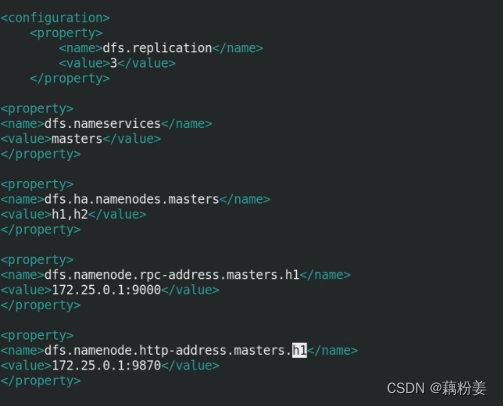
vim hdfs-site.xml
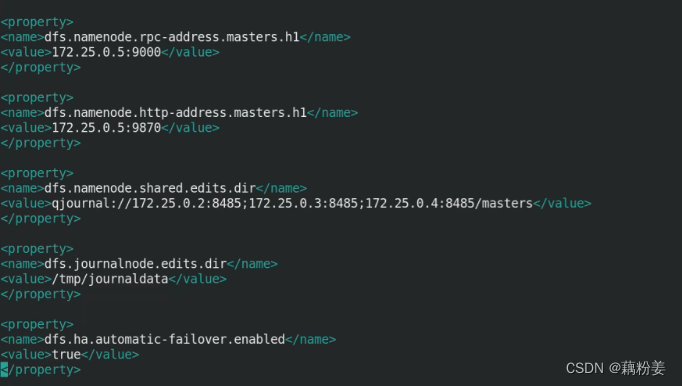
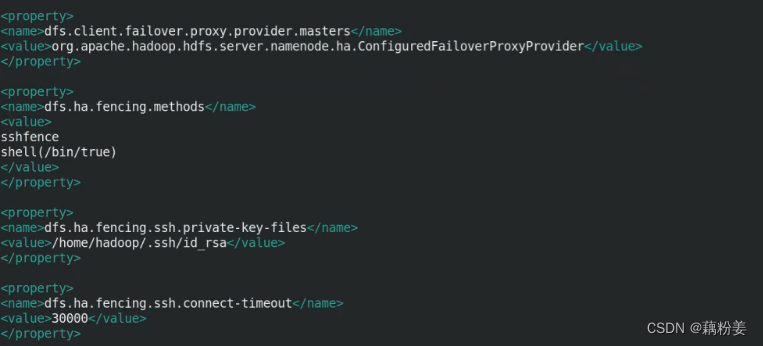
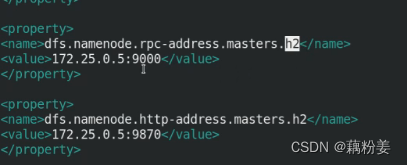
server2,3,4
cd
cd hadoop
bin/hdfs --daemon start journalnode
jps
如果遇到启动的时候没有问题,过了一会这个进程掉了,很可能是内存不够了
server1
cd ..
cd ..
bin/hdfs namenode -format 格式化出现问题了,是因为之前的配置文件
bin/hdfs namenode -format
scp -r /tmp/hadoop-hadoop 172.25.0.5:/tmp
bin/hdfs zkfc -formatZK 只需要在一个节点上做
server2
cd
cd zookeeper-3.4.9/
ls
bin/zkCli.sh
ls
ls /hadoop-ha/masters
get /hadoop-ha/masters
server1
sbin/start-dfs.sh
jps
vim core-site.xml去掉9000
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input
故障切换
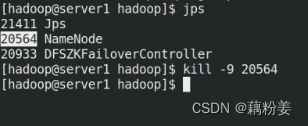
之前1不能访问了,5可以
bin/hdfs --daemon start namenode
实现rm 资源管理器的高可用
server1
cd etc/hadoop/
cat mapred-site.xml
vim yarn-site.xml
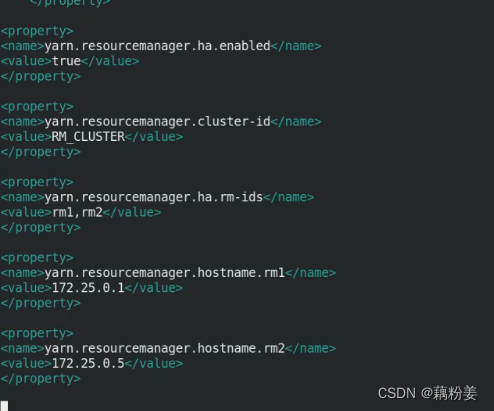
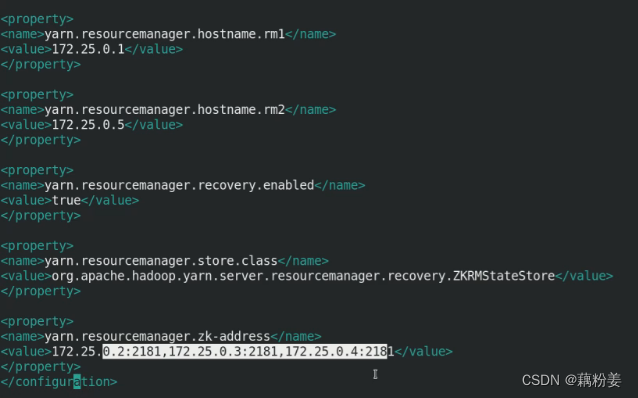
cd ..
cd ..
sbin/start-yarn.sh
jps
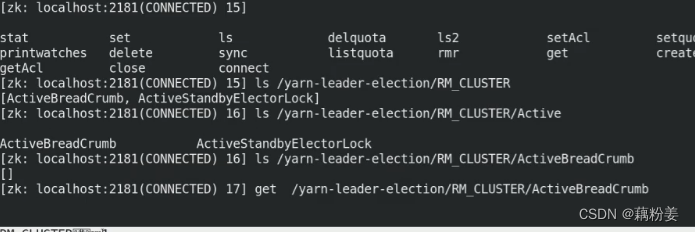
海量的无规则的数据,分析完了之后,会从里面去找他们之间的关心,找出来的数据,可能会存到什么地方,基本上他也会需要用到这种关系数据库
server1
cd hbase-1.2.4/
cd conf/
vim hbase-env.sh
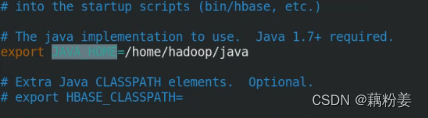
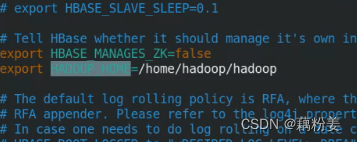
vim hbase-site.xml

vim regionservers
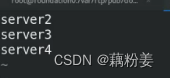
server1
cd
cd hadoop
cd hbase-1.2.4/
bin/start-hbase.sh
server5
cd hbase-1.2.4/
ls
cd bin/
cd ..
bin/hbase-daemon.sh start master
jps
server1
bin/hbase shell
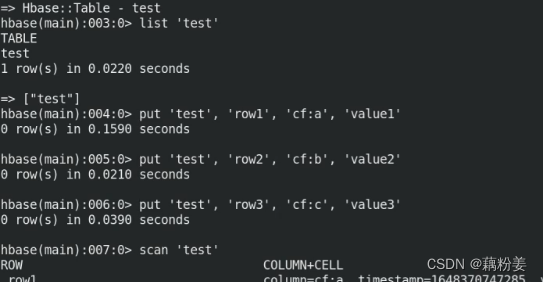
create 'test','cf'
list 'test'

bin/hbase-daemon.sh start master
bin/hbase-daemon.sh stop master















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









