







研究背景
线性方程组,也就是线性代数中矩阵的意义,m×n的矩阵即m个式子,解n个未知数,求解方法有将矩阵化为上三角的高斯消去法,通法硬求的克莱姆法则等,这些称为直接法,通过有限次的计算直接求得方程组的精确解。
但随着目前计算机视觉和虚拟世界的飞速发展,计算机求解的矩阵越来越大,上述求精确解的方法需要耗费大量计算资源和内存,并且很多大型稀疏矩阵用直接法求解十分复杂,数学家又研究了一种能让计算机在多次执行中不断逼近真实值的方法—迭代法。
一些概念
范数
两个值我们可以直接比较大小,如果是两个向量甚至两个矩阵我们如何进行比较呢?基于该问题提出了范数。这个概念可以用于衡量大小,比较误差,将向量甚至矩阵与实数映射起来,记作||A||比如向量的取模长,根据映射规则的不同也有多种计算方法:
向量的范数:
1范数,为向量各元素绝对值之和,记作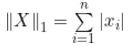 ;
;
2范数,为向量模长,即各元素绝对值的平方和再开根号,记作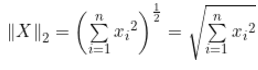
无穷范数,为向量绝对值的最大值,记作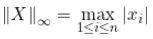
矩阵的范数
1范数,为矩阵绝对值的最大列和,记作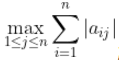
2范数,为
λ
\sqrt{\lambda }
λ,
λ
\lambda
λ为
A
A
T
AA^{T}
AAT的最大特征值
无穷范数,为矩阵最大绝对值行和,与1范数相同。
相关详细信息可见该文章。
谱半径
定义为矩阵特征值绝对值集合的上确界,其实就是矩阵特征值绝对值的最大值,几位 ρ ( A ) = max 1 ≤ j ≤ n ∣ λ j ∣ \rho (A)=\max_{1\le j \le n } \left | \lambda _{j} \right | ρ(A)=max1≤j≤n∣λj∣。
和矩阵范数的关系为:
ρ
(
A
)
≤
∣
∣
A
∣
∣
\rho (A)\le \left | \left | A \right | \right |
ρ(A)≤∣∣A∣∣,即谱半径为范数的下界,因为矩阵2范数定义为
A
A
T
AA^{T}
AAT最大特征值的开根号,但实对称矩阵谱半径与2范数相等。
方程组的性态与误差分析
方程组求解的误差可能来自两方面:
1,求解方法不当
2,方程组性态不好
方法是我们后续要学习的内容,这里先介绍方程组的性态问题。其性态不好具体表现在 A x = b Ax=b Ax=b中,A或b的一个小扰动会引起解的很大变化,称之为病态,A为病态矩阵,否则称之为良态,那该如何量化定义矩阵的病态程度呢?该过程就要借助范数。
探索过程如下:
A无扰动,b有扰动,表现为
A
(
δ
x
+
x
)
=
b
+
δ
b
A(\delta x+x)=b+\delta b
A(δx+x)=b+δb,化简一步得
A
δ
x
+
A
x
=
b
+
δ
b
A\delta x+Ax=b+\delta b
Aδx+Ax=b+δb,其中AX=b抵消,得
A
δ
x
=
δ
b
A\delta x=\delta b
Aδx=δb,化简得
δ
x
=
A
−
1
δ
b
\delta x=A^{-1} \delta b
δx=A−1δb,两端同时取范数,可得
∣
∣
δ
x
∣
∣
=
∣
∣
A
−
1
δ
b
∣
∣
≤
∣
∣
A
−
1
∣
∣
∣
∣
δ
b
∣
∣
\left |\left | \delta x \right | \right |= \left | \left | A^{-1}\delta b \right | \right | \le \left | \left | A^{-1} \right | \right | \left | \left | \delta b \right | \right |
∣∣δx∣∣=
A−1δb
≤
A−1
∣∣δb∣∣。
中间不记得了,反正最后推出决定方程病态程度是条件数— ∣ ∣ A ∣ ∣ ∣ ∣ A − 1 ∣ ∣ \left | \left | A \right | \right | \left | \left | A^{-1} \right | \right | ∣∣A∣∣ A−1 ,表示为 c o n d ( A ) = ∣ ∣ A ∣ ∣ ∣ ∣ A − 1 ∣ ∣ cond(A)=\left | \left | A \right | \right | \left | \left | A^{-1} \right | \right | cond(A)=∣∣A∣∣ A−1 ,矩阵A的条件数越大越病态。
条件数计算并没有指定什么范数,其性质如下:
1,一个矩阵的条件数具有一致性,多种范数的趋势也一致。
2,条件数依赖于范数,范数彼此等价,选取不同范数的条件数不会产生本质差别。
3,A为实对称矩阵时,1和无穷范数相等,谱半径与2范数相等,
c
o
n
d
2
(
A
)
=
∣
λ
1
∣
∣
λ
2
∣
cond_{2} (A)=\frac{\left | \lambda _{1} \right | }{\left | \lambda _{2} \right | }
cond2(A)=∣λ2∣∣λ1∣,其中
λ
\lambda
λ分别表示A的最大最小特征值。
条件数的性质:
1,范数不小于1,即
c
o
n
d
(
A
)
≥
1
cond (A)\ge 1
cond(A)≥1
2,逆的条件数等于自身的条件数,
c
o
n
d
(
A
−
1
)
=
c
o
n
d
(
A
)
cond(A^{-1})=cond(A)
cond(A−1)=cond(A)
3,矩阵乘实数后的条件数等于自身,
α
∈
R
,
α
≠
0
,
c
o
n
d
(
A
)
=
c
o
n
d
(
α
A
)
=
∣
∣
α
A
−
1
∣
∣
∣
∣
A
∣
∣
\alpha ∈R,\alpha ≠0,cond(A)=cond(\alpha A)=\left | \left | \alpha A^{-1} \right | \right | \left | \left | A \right | \right |
α∈R,α=0,cond(A)=cond(αA)=
αA−1
∣∣A∣∣。
4,有正交矩阵U,
c
o
n
d
2
(
U
)
=
1
cond_{2}(U)=1
cond2(U)=1,
c
o
n
d
2
(
A
)
=
c
o
n
d
2
(
U
A
)
=
c
o
n
d
2
(
A
U
)
cond_{2}(A)=cond_{2}(UA)=cond_{2}(AU)
cond2(A)=cond2(UA)=cond2(AU)
定义:
A为n阶非奇异矩阵,
x
^
\hat{x}
x^为Ax=b的近似解,有残余
r
=
b
−
A
x
^
r=b-A\hat{x}
r=b−Ax^,
1
c
o
n
d
(
A
)
∣
∣
r
∣
∣
∣
∣
x
∣
∣
≤
∣
∣
x
−
x
^
∣
∣
∣
∣
x
∣
∣
≤
c
o
n
d
(
A
)
∣
∣
r
∣
∣
∣
∣
b
∣
∣
\frac{1}{cond(A)}\frac{\left | \left | r\right | \right | }{\left | \left | x \right | \right | }\le\frac{\left | \left | x-\hat{x} \right | \right | }{\left | \left | x \right | \right | }\le cond(A)\frac{ \left | \left | r\right | \right | }{\left | \left | b \right | \right | }
cond(A)1∣∣x∣∣∣∣r∣∣≤∣∣x∣∣∣∣x−x^∣∣≤cond(A)∣∣b∣∣∣∣r∣∣,可推出,近似解
x
^
\hat{x}
x^的精度不仅依赖于r的大小,还依赖A的条件数。
线性方程组的迭代解法
Jacobi雅可比迭代法
由线性方程组格式
a
11
x
1
+
a
12
x
2
+
.
.
.
+
a
1
n
x
n
=
b
1
a_{11}x_{1}+a_{12}x_{2}+...+a_{1n}x_{n}=b_{1}
a11x1+a12x2+...+a1nxn=b1,可得
x
1
=
1
a
n
(
−
a
12
x
2
−
a
13
x
3
−
.
.
.
−
a
n
x
n
+
b
1
)
x_{1}=\frac{1}{a_{n}} (-a_{12}x_{2}-a_{13}x_{3}-...-a_{n}x_{n}+b_{1})
x1=an1(−a12x2−a13x3−...−anxn+b1),同理x2、x3等均可转化为这种形式。
故迭代形式直接取左边为k+1,右边为k,则转化为
x
1
k
+
1
=
1
a
n
(
−
a
12
x
2
k
−
a
13
x
3
k
−
.
.
.
−
a
n
x
n
k
+
b
1
)
x_{1}^{k+1}=\frac{1}{a_{n}} (-a_{12}x_{2}^{k}-a_{13}x_{3}^{k}-...-a_{n}x_{n}^{k}+b_{1})
x1k+1=an1(−a12x2k−a13x3k−...−anxnk+b1),由此只要有初值
x
0
x_{0}
x0就可得
x
1
x_{1}
x1,由此往复无穷多次就趋近于真解,
lim
k
→
∞
x
k
=
x
∗
\lim_{k \to \infty} x^{k}=x^{*}
limk→∞xk=x∗。
该近似解与初值无关,所以初值可任意取值,且并非解任意方程组均收敛。
一道例题可见该文章,该文章用的方法虽然不完全一样,但一定程度可体现相同的迭代思想。
雅可比迭代法的矩阵形式
A
x
=
b
Ax=b
Ax=b中的矩阵A可拆解为三个矩阵,分别为对角阵D、负三角阵L和负上三角阵U,即
A
=
D
−
L
−
U
A=D-L-U
A=D−L−U ,原式转化为
(
D
−
L
−
U
)
x
=
b
=
>
D
x
=
(
L
+
U
)
x
+
b
(D-L-U)x=b=>Dx=(L+U)x+b
(D−L−U)x=b=>Dx=(L+U)x+b,最后推出
x
=
D
−
1
(
L
+
U
)
x
+
D
−
1
b
x=D^{-1}(L+U)x+D^{-1}b
x=D−1(L+U)x+D−1b,转化为矩阵形式:
x
k
+
1
=
D
−
1
(
L
+
U
)
x
k
+
D
−
1
b
x^{k+1}=D^{-1}(L+U)x^{k}+D^{-1}b
xk+1=D−1(L+U)xk+D−1b,
其中 D − 1 ( L + U ) D^{-1}(L+U) D−1(L+U)为迭代矩阵,该迭代矩阵对角元素一定为零,记为 M 1 M_{1} M1,该矩阵决定算法的敛散性,。
Gauss-Seidel高斯赛德迭代法
该算法是Jacobi迭代法的改进,第一步时我们计算出 x 1 k + 1 x_{1}^{k+1} x1k+1,高斯赛德迭代法直接把该结果带入 x 2 k + 1 x_{2}^{k+1} x2k+1的计算中,可以加速收敛过程。
需要注意的是虽然高斯赛德迭代法是雅可比迭代法的改进,但二者收敛性并无必然相关性,且只有都收敛时高斯赛德才加快收敛速度。
G·S迭代法的矩阵形式为
x k + 1 = ( D − L ) − 1 U x k + ( D − L ) − 1 b x^{k+1}=(D-L)^{-1}Ux^{k}+(D-L)^{-1}b xk+1=(D−L)−1Uxk+(D−L)−1b
其中 ( D − L ) − 1 U (D-L)^{-1}U (D−L)−1U为迭代矩阵,该迭代矩阵第一列为零。
迭代法的收敛性分析
一般性收敛条件
如 x ∗ x^{*} x∗为 A x = b Ax=b Ax=b的解, x ∗ = M x ∗ + f x^{*}=Mx^{*}+f x∗=Mx∗+f, ε k + 1 = x k + 1 − x ∗ \varepsilon^{k+1}=x^{k+1}-x^{*} εk+1=xk+1−x∗
定理1:
x
k
+
1
=
M
x
k
+
f
x^{k+1}=Mx^{k}+f
xk+1=Mxk+f时,对任意
x
0
x^{0}
x0均有迭代法收敛的充要条件:
lim
k
→
∞
M
k
=
0
\lim_{k \to \infty} M^{k}=0
limk→∞Mk=0
定理2:
x
k
+
1
=
M
x
k
+
f
x^{k+1}=Mx^{k}+f
xk+1=Mxk+f时,对任意
x
0
x^{0}
x0均有迭代法收敛的充要条件:
ρ
(
M
)
<
1
谱半径小于
1
\rho(M) <1 谱半径小于1
ρ(M)<1谱半径小于1
推论:
Jacobi的收敛条件:
ρ
(
D
−
1
(
L
+
U
)
)
<
1
\rho(D^{-1}(L+U))<1
ρ(D−1(L+U))<1
G·S法的收敛条件:
ρ
(
(
D
−
L
)
−
1
U
)
<
1
\rho((D-L)^{-1}U)<1
ρ((D−L)−1U)<1
总结:
收敛条件
迭代矩阵k次为0或谱半径<1
例题,Ax=b,其中A=[[1,2,-2],讨论Jacobi迭代法的敛散性
[1,1,1]
[2,2,1]]
解:A=D-L-U D=[[1,0,0] L=[[0,0,0] U=[[0,-2,2]
[0,1,0] [-1,0,0] [0,0,-1]
[0,0,1]] [-2,-2,0]] [0,0,0]]
迭代矩阵D-1(L+U)=[[0,-2,2]
[-1,0,-1]
[-2,-2,0]]
特征值r1=r2=r3=0 谱半径为0,收敛
定理3:
ρ
(
M
)
≤
∣
∣
M
∣
∣
\rho(M)\le\left | \left | M \right | \right |
ρ(M)≤∣∣M∣∣若
∣
∣
M
∣
∣
<
1
\left | \left | M \right | \right |<1
∣∣M∣∣<1则说明收敛,该定理为充分条件,谱半径通常难求,故可用该范数方法优先判断。
由 ∣ ∣ x k − x ∗ ∣ ∣ = ∣ ∣ M ∣ ∣ 1 − ∣ ∣ M ∣ ∣ ∣ ∣ x k − x k − 1 ∣ ∣ \left | \left | x^{k}-x^{*} \right | \right | =\frac{\left | \left | M \right | \right | }{1-\left | \left | M \right | \right | }\left | \left | x^{k}-x^{k-1} \right | \right | xk−x∗ =1−∣∣M∣∣∣∣M∣∣ xk−xk−1 :
则有停机标准 ∣ ∣ x k − x k − 1 ∣ ∣ ≤ ε \left | \left | x^{k}-x^{k-1} \right | \right |\le\varepsilon xk−xk−1 ≤ε即 ∣ ∣ x k − x ∗ ∣ ∣ = ∣ ∣ M ∣ ∣ 1 − ∣ ∣ M ∣ ∣ ε \left | \left | x^{k}-x^{*} \right | \right | =\frac{\left | \left | M \right | \right | }{1-\left | \left | M \right | \right | }\varepsilon xk−x∗ =1−∣∣M∣∣∣∣M∣∣ε
原式又有: ∣ ∣ x k − x ∗ ∣ ∣ ≤ ∣ ∣ M ∣ ∣ k 1 − ∣ ∣ M ∣ ∣ ∣ ∣ x 1 − x 0 ∣ ∣ \left | \left | x^{k}-x^{*} \right | \right | \le\frac{\left | \left | M \right | \right |^{k} }{1-\left | \left | M \right | \right | }\left | \left | x^{1}-x^{0} \right | \right | xk−x∗ ≤1−∣∣M∣∣∣∣M∣∣k x1−x0 称为先验估计
ε
\varepsilon
ε给定时解的k可只迭代步数,整理得
k
>
l
n
(
ε
(
1
−
∣
∣
M
∣
∣
)
∣
∣
x
1
−
x
0
∣
∣
)
l
n
(
∣
∣
M
∣
∣
)
k> \frac{ln(\frac{\varepsilon (1-\left | \left | M \right | \right | )}{\left | \left | x^{1}-x^{0} \right | \right | } )}{ln(\left | \left | M \right | \right | )}
k>ln(∣∣M∣∣)ln(∣∣x1−x0∣∣ε(1−∣∣M∣∣))
可知
∣
∣
M
∣
∣
和
ρ
(
M
)
||M||和\rho (M)
∣∣M∣∣和ρ(M)越小收敛越快,收敛速度为
R
(
M
)
=
−
l
n
(
ρ
(
M
)
)
R(M)=-ln(\rho (M))
R(M)=−ln(ρ(M))。
特殊判别法
通过特殊的系数矩阵A判定:
若对角元素大于同行/列的绝对值之和,数学表示为
∑
n
j
=
1
∣
a
i
j
∣
≤
∣
a
i
i
∣
\sum_{n}^{j=1}|a_{ij}|\le|a_{ii}|
∑nj=1∣aij∣≤∣aii∣称为对角行/列对角占优,相关收敛性质如下:
A按行/列严格对角占优,该方程有唯一解,jacobi和GS法均收敛
对称正定矩阵A矩阵有唯一解,且GS法收敛,若2D-A也对称正定,则Jacobi也收敛
收敛性判定方法
故判别流程一般如下:
1,特殊情况匹配,看是否对角占优或对称正定
2,计算迭代矩阵,看范数是否<1,计算时需注意
M
j
=
D
−
1
(
L
+
U
)
M_{j}=D^{-1}(L+U)
Mj=D−1(L+U)对角为零,
M
G
−
S
=
(
D
−
L
−
1
U
)
M_{G-S}=(D-L^{-1}U)
MG−S=(D−L−1U)第一列为零。
3,求谱半径,<1收敛,>1发散。
总结
本章学习了线性方程组的近似数值解法,主要用Jacobi和改进GS两种迭代方法,流程是根据已有矩阵构建
x
1
.
.
.
x
n
x_{1}...x_{n}
x1...xn的相关表达式,带入计算迭代求解,GS法只是将前面已算好的k+1阶带入后续变量求解,加快收敛速度。
该方法的收敛性判别主要分三步:
特殊情况(对角占优或对称正定)、计算迭代矩阵范数、求谱半径。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









