







一、执行计划查看
示例:执行计划是 SQL 语句的执行方式,由查询优化器为语句设计的执行方式,交给执行器去执行。在 SQL 命令行使用 EXPLAIN 可以打印出语句的执行计划。
1.操作符
操作符是SQL执行的基本单元,所有的SQL语句最终都是转换成一连串的操作符最后在服务器上执行,得到需要的结果,操作符也是读懂执行计划的基础。
这些操作符是SQL查询数据的原始来源,SQL里面出现的基表,都会出现在这些操作符的描述中,通过这些操作符来确定对应的表在执行计划中在何时以什么样的方式进入。
常见的操作符有
CSCN :基础全表扫描(a),从头到尾,全部扫描
SSCN :二级索引扫描(b), 从头到尾,全部扫描
SSEK :二级索引范围扫描(b) ,通过键值精准定位到范围或者单值
CSEK :聚簇索引范围扫描© ,通过键值精准定位到范围或者单值
BLKUP :根据二级索引的ROWID 回原表中取出全部数据(b + a)
SLCT:过滤条件,是对结果集进行过滤,需要注意的是操作符的描述信息,从描述信息中可以看到对于下层操作有哪些可用的过滤条件,这些条件往往是优化方向的来源。
SORT: SORT是做排序操作时使用到的操作符。
HAGR:HASH AGR操作,是最基础的分组方式,对于没有优化条件的分组语句,一般都会按这种方式进行分组,分组原理和HASH INNER JOIN 的方式类似,将原表数据取出,每个计算FOLD,发现有FOLD相同,且满足后续条件的合并为一组。
SAGR: SORTED AGR操作,不同于HASH AGR,由于下层数据有序,同一分组的数据按照顺序取出就行,节省了大量的计算。
更多的操作符解释,可以参考DM7的系统管理员手册或者查看动态视图 V$SQL_NODE_NAME视图。
2.多表连接操作符
在做多表连接查询时,存在以下集中SQL操作符:
- NEST LOOP INNER JOIN(嵌套循环连接) :最基础的连接方式,将一张表的一个值与另一张表的所有值拼接,形成一个大结果集,再从大结果集中过滤出满足条件的行。
- HASH JOIN(哈希连接):没有索引的情况下,大多数连接的处理方式,将一张表的连接列做成HASH表,另一张表的数据向这个HASH表匹配,满足条件的返回。
- INDEX JOIN(索引连接): 将一张表的数据拿出,去另外一张表上进行范围扫描找出需要的数据行,需要右表的连接列上存在索引。
- MERGE JOIN(归并连接):两张表都扫描索引,按照索引顺序进行归并。
3.查看执行计划
CREATE TABLE T1(C1 INT,C2 CHAR);
CREATE TABLE T2(D1 INT,D2 CHAR);
CREATE INDEX IDX_T1_C1 ON T1(C1);
INSERT INTO T1 VALUES(1,'A');
INSERT INTO T1 VALUES(2,'B');
INSERT INTO T1 VALUES(3,'C');
INSERT INTO T1 VALUES(4,'D');
INSERT INTO T2 VALUES(1,'A');
INSERT INTO T2 VALUES(2,'B');
INSERT INTO T2 VALUES(5,'C');
INSERT INTO T2 VALUES(6,'D');

explain select a.c1+1,b.d2 from t1 a, t2 b where a.c1 = b.d1;

控制流从上向下传递,数据流从下向上传递。
类似[0, 16, 9]的三个数字,分别表示: 估算的操作符代价、处理的记录行数 和 每行记录的字节数。
同一层次中的操作符,如本例中的 CSCN2 和 SSEK2,由父节点NEST LOOP INDEX JOIN2 控制它们的执行顺序。
该计划的大致执行流程如下:
- CSCN2: 扫描 T2 表的聚集索引,数据传递给父节点索引连接;
- NEST LOOP INDEX JOIN2: 当左孩子有数据返回时取右侧数据;
- SSEK2: 利用 T2 表当前的 D1 值作为二级索引 IDX_T1_C1 定位查找的 KEY,返回结果给父节点;
- NEST LOOP INDEX JOIN2: 如果右孩子有数据则将结果传递给父节点 PRJT2,否则继续取左孩子的下一条记录;
- PRJT2: 进行表达式计算 C1+1, D2;
- NSET2: 输出最后结果;
- 重复过程 1) ~ 4)直至左侧 CSCN2 数据全部取完。
二、查询计划重用
如果同一条语句执行频率较高,或者每次执行的语句仅仅是常量值不同,则可以考虑使用计划重用机制。避免每次执行都需要优化器进行分析处理,可以直接从计划缓存中获取已有的执行计划,减少了分析优化过程,提高执行率。
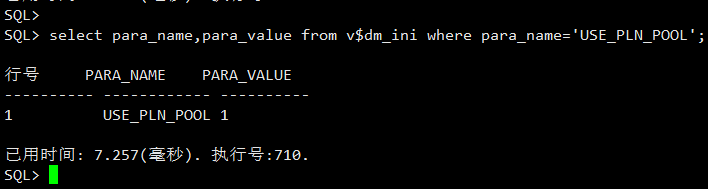
对于计划重用,达梦数据库提供了 INI 参数 USE_PLN_POOL 来控制,默认为启动。当置为非 0 时,会启用计划重用。
select para_name,para_value from v$dm_ini where para_name='USE_PLN_POOL';
三、 自适应计划
在 DM 优化器进行代价估算时,如果子节点是一个复杂查询,可能使得对于子节点的代价估算不准确,导致最终选择的计划在执行时并非最优计划。因此,DM 引入了自适应计划机制。
将 INI 参数 OPTIMIZER_MODE 设置为1, ADAPTIVE_NPLN_FLAG 置为 3,启用自适应计划机制。此时,优化器会自动判断在某些情况下,复杂查询的子节点可能导致代价估算不准确,则会为该节点生成一个备用计划节点。在实际执行到该节点时,根据准确的代价信息确定是否需要采用备用计划。
select para_name,para_value from v$dm_ini where para_name='OPTIMIZER_MODE';
select para_name,para_value from v$dm_ini where para_name='ADAPTIVE_NPLN_FLAG';

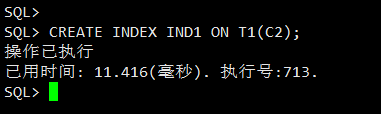
在之前的测试表上在创建一个索引:
CREATE INDEX IND1 ON T1(C2);
查看执行计划:
explain select * from t1 ,t2 ,t1 t3 where t2.d1= t3.c1 and t1.c2=t2.d2;

执行计划中有一个 ACTRL 操作符,它说明优化器为这一条 SQL 语句生成了备用计划。ACTRL 是控制备用计划转换的操作符,其上面一层 NEST LOOP INDEX JOIN2 为默认的主计划,再上面一层 HASH2 INNER JOIN 则为备用计划。ACTRL 操作符计算下层孩子节点的代价,决定采用默认主计划还是备用计划。
注意:MPP 和并行查询不支持自适应计划。















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









