






整篇文章大多数是介绍论文,少部分是在Java实现HotRing上面的扩展。若看起来太枯燥直接看文末的测试数据,看完后如果对HotRing的优化感到好奇再来阅读整个文章🐶也可以直接去阅读原论文🐶
问题
线上大部分的请求都只会访问很少的数据,热点现象很严重,那么热点现象带来什么问题?
比如redis我们经常用来做缓存,假如在热点场景,需要从中读取,多热点时可能hash值相同会导致链表过长,每次访问时需要访问整个链表,如果这个热点数据放在最末尾则需要每次访问内存降低性能。
可能说可以用LRU,但是LRU是一个将最近最少使用的数据淘汰的热点检测算法,如果在热点过程中有一些批量数据操作,会把热点数据刷掉,也会导致效率下降,造成缓存污染。
LFU也有同样的缺点,根据次数检测热点,一个是需要记录次数,也会造成内存开销,一个是如果很热的数据在后续时间都没有访问,但是由于这是一个热数据,会一直存在缓存中也会存在缓存污染。 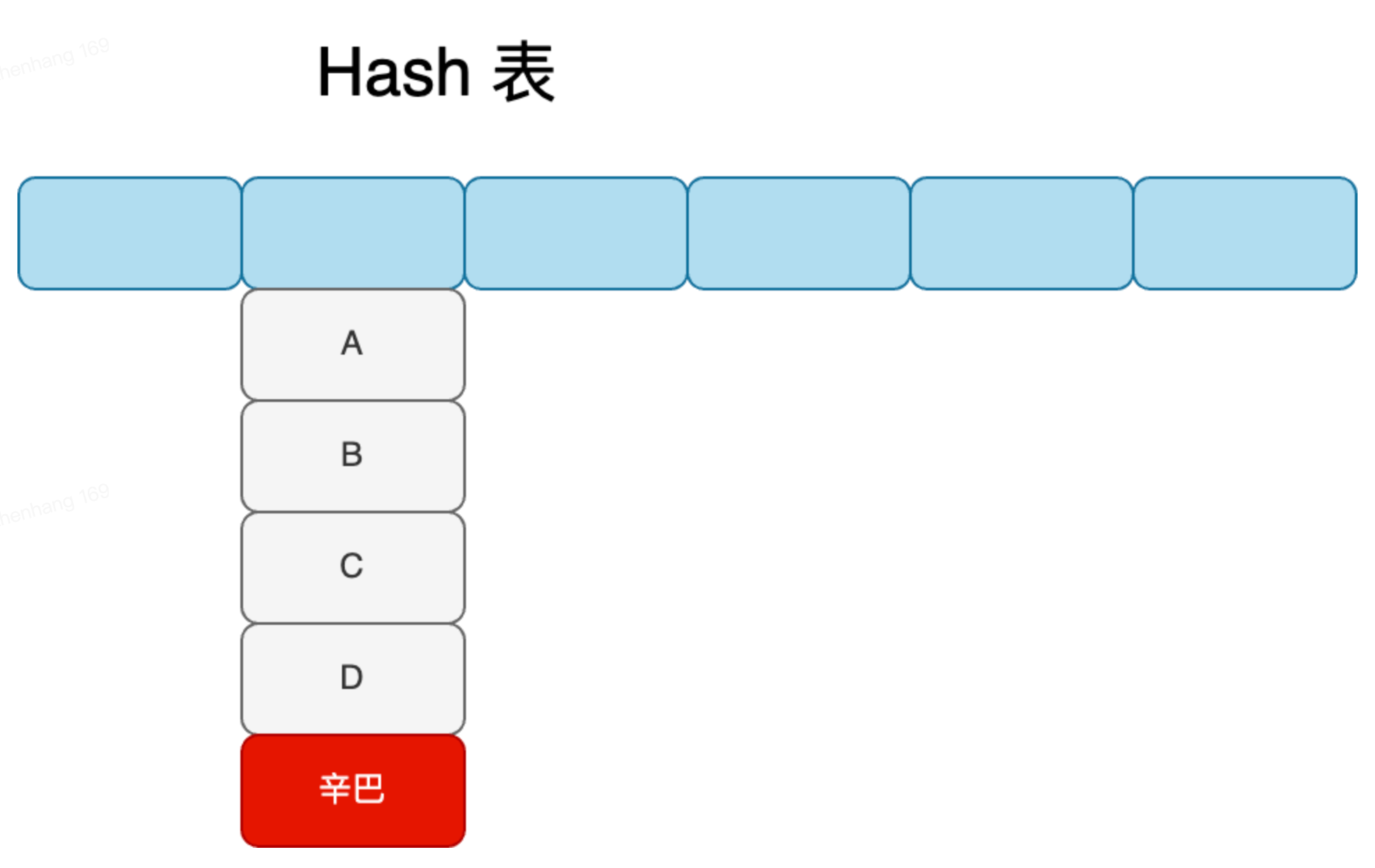 如上图,支付极端场景辛巴和一堆卖家id都产生了collision,但是辛巴的item存放在链表底端,而99%的请求都是访问我巴哥,导致每次都需要遍历整个链表,空间+时间消费都很高。 背景
如上图,支付极端场景辛巴和一堆卖家id都产生了collision,但是辛巴的item存放在链表底端,而99%的请求都是访问我巴哥,导致每次都需要遍历整个链表,空间+时间消费都很高。 背景
-
关于Paper 《HotRing: A Hotsport-Aware In-Memory Key-Value Store》发表于2020年,主要研究的是使用链表结构解决哈希冲突时,访问热点数据存在一定额外开销的问题。论文提出的HotRing结构支持热点数据发现,并且可通过使环状链表的头部指针指向hot item,减少读取所需遍历的路径,达到提升访问效率的目的。
当前许多数据结构用于KV存储服务,例如skip list、hashmap、mastree等,但是都没有意识到热点概念,而在支付场景其实有很多热点数据,当前没有统计过支付内部数据访问分布,HotRing收集了阿里生产环境中内存KVS的访问量分布。数据的访问规律呈现很严重的幂律分布(Zipfian Distribution) ,从论文提供的图可以看出 50%(日常情况)到90%(极端情况)的访问仅仅触及总数据的1%。故而在热点场景下保证系统的可用性非常重要。
Hash Collision解决方案
Open Addressing
开放地址法是将冲突的Item放到hash表内部,查找对应的Item元素的过程叫探测
-
相邻的空位--线性探测 -
间隔1、4、9、16的空位--平方探测 -
多次hash计算空位 解决方案简单,但是缺点也很明显,就是需要保证hash表比数据集更大,而探测时如果当前未知没有探测到,会一直探测下去,导致遍历路径很长,性能下降。
Collision Chain
链表法将Item存储在hash表之外,每个item通过hash定位到的hash桶存放着指向链表头部的指针,通过顺序遍历链表来找到该元素是否存在。 和开放地址法相比,其允许Item元素大于hash表,在负载因子增长的情况下,其查询时间复杂度随着链表长度线性增长 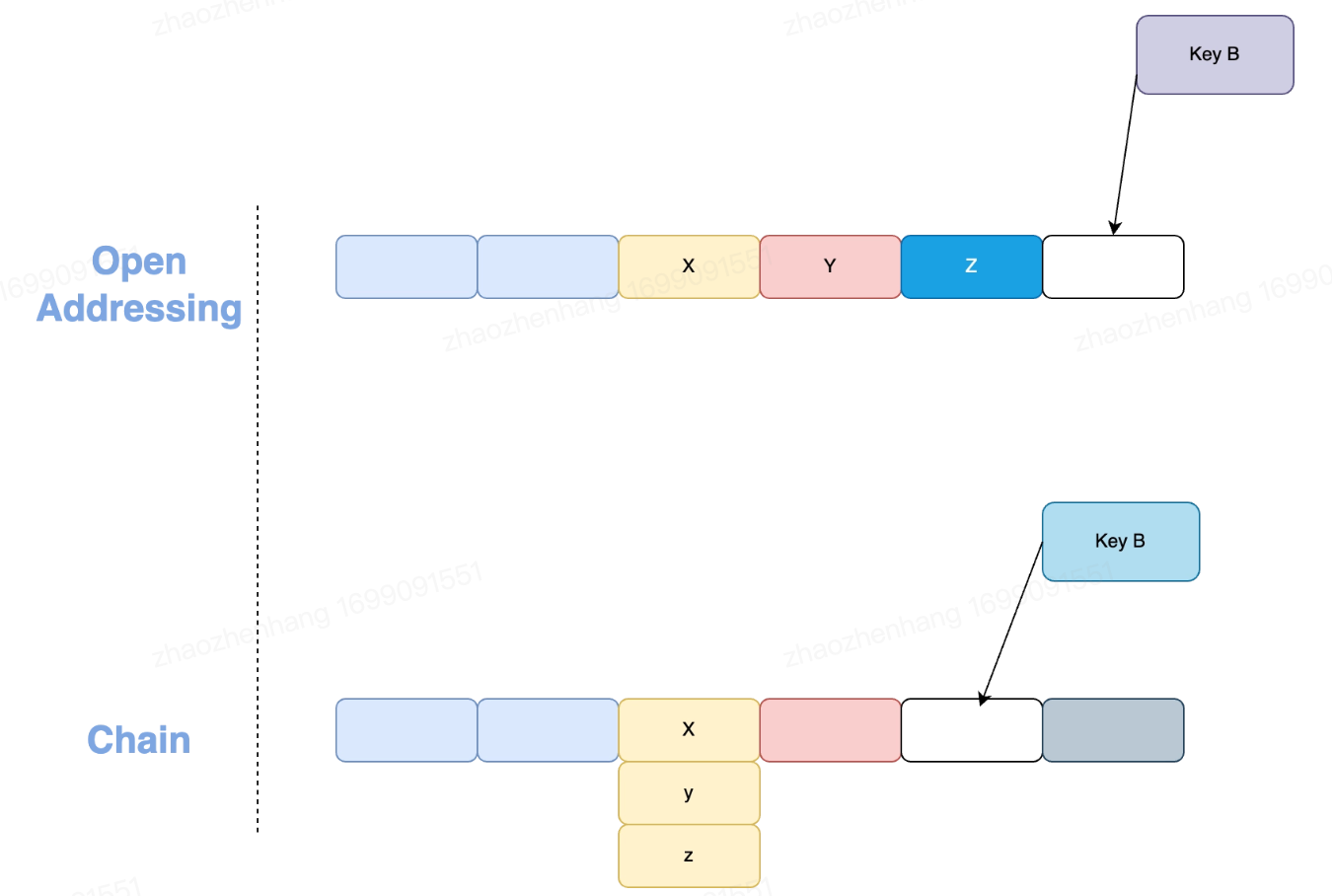 对于链表法的热点数据访问,简化模型其查找次数如下
对于链表法的热点数据访问,简化模型其查找次数如下 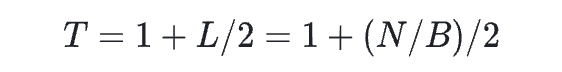 L代表hash桶对应的链表长度,N为总的Item数,B为hash桶数量 但是如果可以让热点Item处于链表头长度,那其访问的复杂度就贴近于O(1),不过对于链表的item位置调整,类似于LRU的实现,在操作元素上面的开销并不低,而实际情况中除了少数hot item的位置,其余item的顺序其实并没有那么重要。因此期望有这么一种数据结构
L代表hash桶对应的链表长度,N为总的Item数,B为hash桶数量 但是如果可以让热点Item处于链表头长度,那其访问的复杂度就贴近于O(1),不过对于链表的item位置调整,类似于LRU的实现,在操作元素上面的开销并不低,而实际情况中除了少数hot item的位置,其余item的顺序其实并没有那么重要。因此期望有这么一种数据结构
-
能够加速热点item的访问 -
及时发现热点 -
以很低的开销将热点移动到便于访问的位置
-
-
支持并发高性能操作 -
高效率的rehash
HotRing 设计概览
-
感知热点转移 -
用HotRing 有序环代替链表 -
访问时,头指针会移动到最近访问项/热点项(热点访问可以显著降低内存读取次数) -
有轻量的策略在运行时检测热点的转移
-
-
随机移动策略 -
统计采样策略
-
-
支持并发 -
无锁化处理:基于CAS、RCU、Hazard Pointers等 -
支持其他并发操作,热点转移检测、头指针移动、rehash等
-
在设计上,HotRing是一个环状的链表结构,在热点数据很多时,HotRing能够让hash桶中的头指针始终指向hot item或者能够高效访问hot item的位置,比起调整链表中item的位置,修改头指针的指向会更高效简洁。有序环主要是为了防止死循环,如果无序环状链表要么遍历所有元素,要么快慢指针进行遍历直到重合退出,但是这两种效果都不好。故而论文中采用有序环进行排序,虽然写入增加了开销,但是在查找时能够更加快速的定位到item或结束遍历。
查询策略
在比较时为了避免两个大长key比较代价较高,增加了一个tag标记位,任意一个Item(k)按照它的(tag, key)值进行字典序排序,即 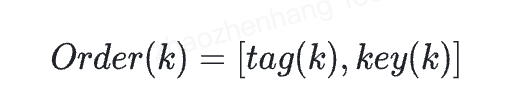 对于目标元素Item(k) 结束的标志如下
对于目标元素Item(k) 结束的标志如下
-
Item存在,则满足 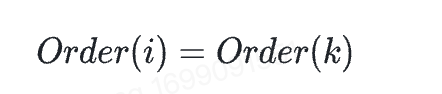
-
Item 不存在,则满足 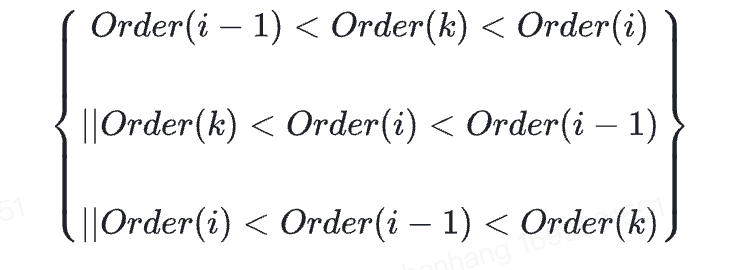
公式难以理解,贴一张论文的图 
如图所示,比如图中的B节点,满足Tag(A) < Tag(B) < Tag(C),所以B没有命中。 同时,有序环的首尾指针有个明显的情况,head指针索引小于tail指针,故而两种边界情况,小于head指针和大于tail指针的都无法命中,比如图中的G和H节点。 这儿和传统链表区别在于传统链表时间复杂度是O(n),而有序环的时间复杂度在幂律分布场景下,99%的请求时间复杂度都是O(1)。 但是论文并没有说这个tag如何构造,如果新增对象去记录tag,需要浪费存储空间不说,还要额外保存tag和对应key的引用,明显得不偿失,这儿我是用位运算来完成tag的取值的,我们在进行查找时,可以通过key获取这个key的hash值,那么我直接对hash值取反
int hashVal = hash(key);
int tag = ~hashVal
这样就只要hash值不同,tag值肯定不同,而且无需引入新的对象来存储tag,实时通过位运算获取。原理就是,比如我某个key的hash值的二进制是 101010,那取反操作后的二进制就是010101,tag哈hash值通过位运算关联。
热点转移策略
随机移动策略
基本思想就是将head指针移动到一个潜在的热点key上面,不需要记录任何历史数据,每个线程都分配了一个ThreadLocal记录执行次数,每R次请求后判断线程是否执行头指针移动操作。如果第R个访问就是热点那不移动,否则就移动头指针到该Item节点。不过参数R影响反应延迟和识别精度,如果使用很小的R,反应延迟高但是会导致频繁且无效的移动头指针,如果太高也会导致热点检测不出来,默认情况下将参数设置为5,这是当前的一个经验,可以提供低的反应延迟和可忽略的性能影响。 这儿有种LFU的感觉了,区别在于一个是链表一个是有序环,为了避免缓存污染问题可以自行加上超时来进行避免。
统计采样策略
为了避免上面的问题和获取更高的性能,设计了一种统计采样策略用来提供更高的反应延迟和更准确的热点识别。 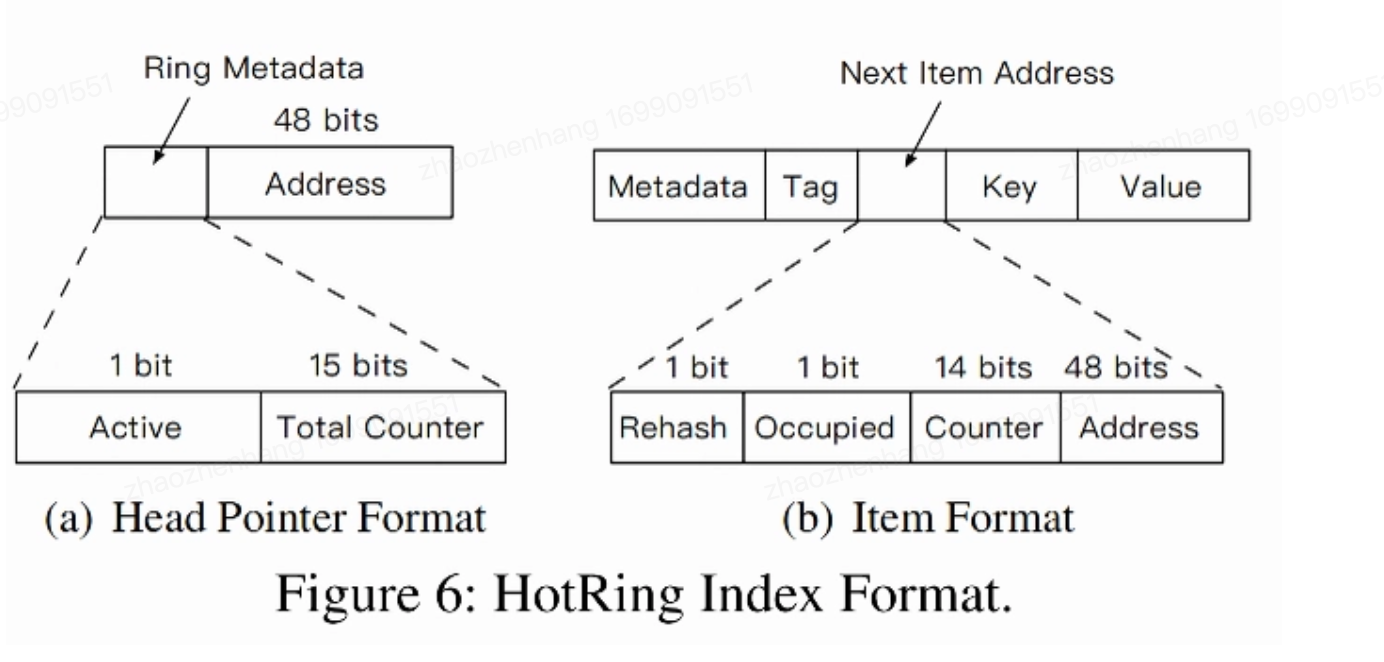
索引格式
计划记记录每个collision ring的数据进入频率。现代机器的物理地址仅仅占用48位,所以我们用余下的16位来记录元数据。在HotRing中,每个头指针都由三部分组成,如上图所示,一个Active位,一个总计数器(15位)和地址(48位)。Active用来控制统计采样以识别热点的标志。总计数器记录对应collision ring的访问次数。然后一般数据项如图b所示,rehash控制rehash的标志,Occupied用于确保并发的正确性,使用下一个数据项的其余14位记录每个数据项的访问计数。因为是个环形链表,所以每个item都有一个指针指向自己。通过环级别和item级别的统计信息进行访问频率的计算。 这儿其实在Java很难实现这个操作
-
Java屏蔽了指针这个东西,无法直接操作 -
无法人为控制GC,GC时内存地址会变 因此Java就无法实现了 但发现active、rehash、occupied都占用1bit,total counter占用15bit,counter占用14bit,加起来刚好32bit,既然原来的方式无法实现,那就新增一个int来存储,int刚好32bit,占用也是降到了最低,而第一个active就占用int的第一个bit,rehash第二个,occupied第3个,total counter占用3-18个,counter占用19-32个。存储结构如图: 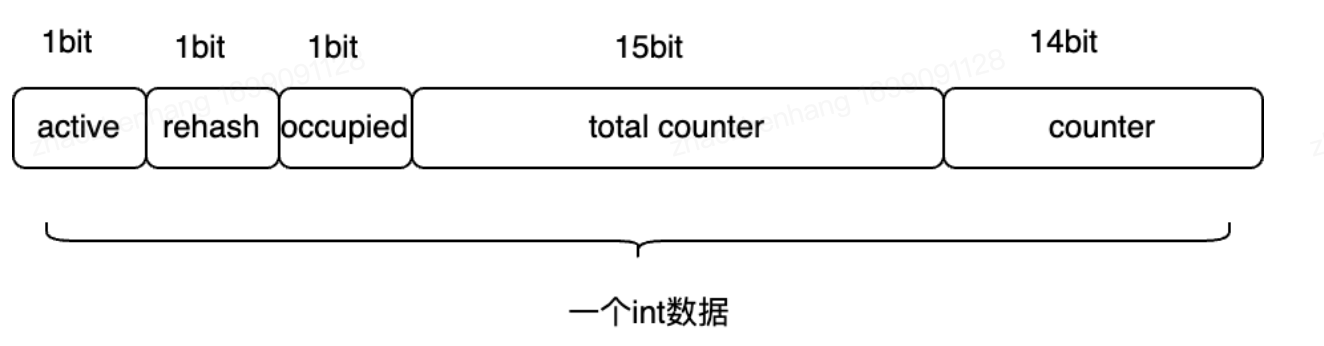 这时候通过位运算去操作对应的bit就能够完成对应参数的记录了,具体位运算过程看代码吧,文章底有代码链接。这儿就不贴了。
这时候通过位运算去操作对应的bit就能够完成对应参数的记录了,具体位运算过程看代码吧,文章底有代码链接。这儿就不贴了。
统计抽样
业务的hashTable会非常大,比如包含227 ~ 230个bucket,如果所有环都同时更新计数的话性能会下降,所以HotRing通过周期性采样完成。和随机移动一样,每个线程都会维护一个thread-local的变量,用于记录处理的请求数量,每当R个请求完成时:
-
如果第R个请求访问的就是hot item,则说明当前热点识别仍然精准,无需重新采样 -
否则,说明hot item已经转移,需要重新采样。 重新采样时会把Active设置为1,然后对后续访问都要记录到Total Counter和Counter计数器中,并更新CAS操作。为了缩短采样时间,将样本数量设置为对应环的item数量。
整体步骤:
-
每个线程维护一个变量,记录执行了多少次请求 -
每隔R个请求就判断是否需要移动头指针 -
若第R个请求就是hot item,则无需移动 -
否则,需要移动头指针并打开采样 -
CAS修改Active -
后续请求记录到Total Counter和Counter(CAS),也是采样R次
-
-
热点调整 基于采样数据,可以确定新的热门商品,并根据商品的访问频率移动头部指针。采样完成后,最后一个访问线程负责频率计算和热点调整。首先,线程会使用CAS的方式原子方式重置Active位,从而确保仅一个线程来指执行后续任务。然后该线程计算环中每个item的访问频率。访问节点开销和节点到头节点的距离成正比,把总开销摊到n次访问上,选取开销最低的作为头节点。 步骤如下:
-
CAS重置Active -
遍历整个collision环,计算每一项的访问频率n(k) / N,N是head节点记录的总计数,n(k)是item(k)的访问计数 计算每个节点的收益W(t) 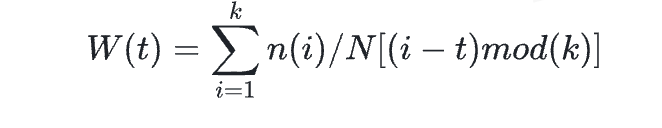 当头指针指向某个数据项item(t) (0 < t < k) 时,相应的收入W(t)计算如上述公式
当头指针指向某个数据项item(t) (0 < t < k) 时,相应的收入W(t)计算如上述公式
-
然后使用CAS将头指针指向具有min(W(t))的item作为热点item。 -
最后重置所有计数器方便下次采样
优化部分
使用RCU优化写密集热点
什么是RCU(Read-Copy-Update)? RCU是linux中数据同步的一种方式,直白点就是更新数据时先复制一份副本,在副本上完成修改,再一次性的替换旧数据,有点类似COW(Copy-On-Write)。 RCU实际上是一种改进的读写锁,它读不加锁,不实用原子指令,在大多数架构上也不需要使用内存栅栏,因此不会导致锁竞争、内存延迟、流水线停滞等问题。
对于现代计算机来说,大部分都是64位处理器,那么总线位宽就是64位宽,8字节,故而对于8字节以内数据总线可一次性传输,超过就得多次传输,这种场景下读取和更新可以看作是一样的操作。但是对于大量数据的更新,就是用了RCU来进行优化,更新时需要修改前一项的指针,故而会导致前一项跟着变热点item,因此修改一个hot Item时,在此时对统计抽样作了一些修改。对于RCU更新直接更新前一项计数器,而非更改本次修改的计数器,那么由于前者item变成一个hot item,头指针指向前者,这时就无需每次都需要进行遍历来进行找到修改hot item的前节点了。 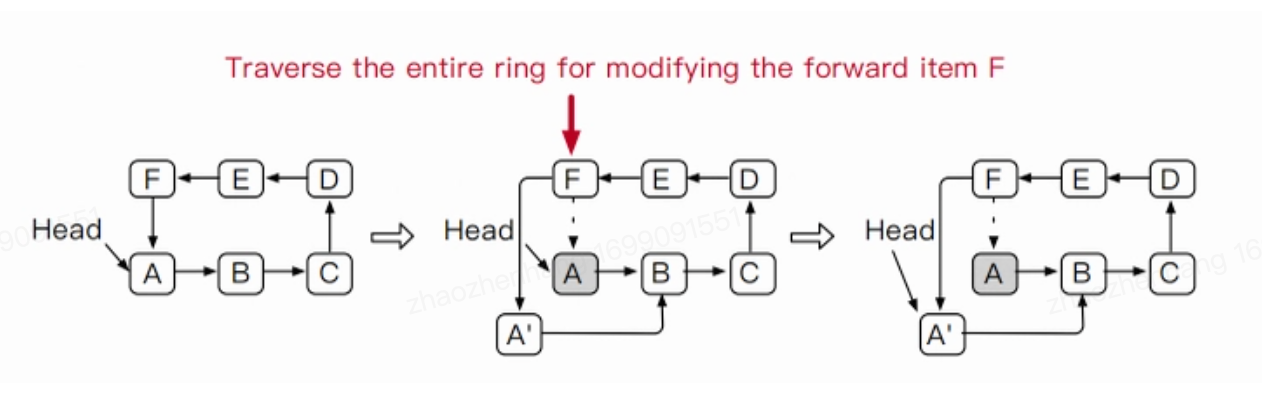 上图(论文Figure 7: Updating hot item A with RCU makes item F hot.) 如图所示,当使用RCU进行修改时,需要找到前节点F,这时候由于是单项链表,所以需要遍历整个环,但如果修改时item指向了F,无需遍历可直接定位到F对象。
上图(论文Figure 7: Updating hot item A with RCU makes item F hot.) 如图所示,当使用RCU进行修改时,需要找到前节点F,这时候由于是单项链表,所以需要遍历整个环,但如果修改时item指向了F,无需遍历可直接定位到F对象。
热点继承
当RCU操作更新或者删除头指针的数据项时可能会发生一个问题,那就是头指针会指向一个非热点项,这会导致热点识别策略一直触发。
-
如果环只有一项,直接CAS修改头指针就行 -
如果有多个项,更新和删除处理不同 -
更新 和之前一样,更新的节点大概率是热点对象,那头指针指向前一个节点也很容易找到下一个热点对象 -
删除,对于删除数据项当前处理是直接将指针移动到下一个项(为什么这么做,可能是论文做了相关benchmark,这么做性能影响不大)
-
并发操作
头指针的移动会导致无锁设计变得复杂
-
头指针移动可能会和其他线程并发,因此,需要考虑头指针移动和其他修改操作的并发的安全性 -
更新和删除时需要判断头指针是否指向该项,并正确修改指针指向 HotRing的核心就是CAS 读操作 对于读操作,HotRing采用之前的有序环查找算法可保证无需加锁并且可正确读取到数据 插入操作 对于插入操作,像上图的a图,插入一个C项,则需要这么几步
-
找到C的位置,链接C项的next指针 -
将前一项的next指针指向C项(CAS) 如果同时有两个插入,会通过CAS保证只有一个成功,而另外一个需要重试 更新操作 对于不同值提供了两种策略,少于8字节,可以通过CAS保证原子操作,不影响其他数据。但是对于超过8字节的就无法通过CAS保证原子性了,这时候分三个情况 -
RCU-update & insert 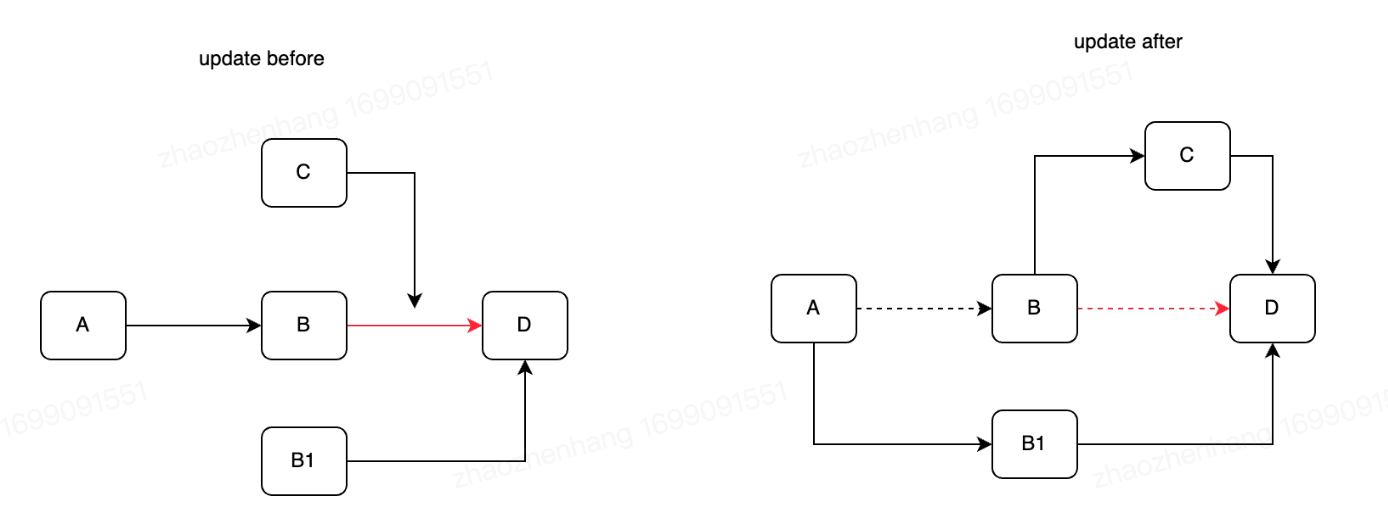 如图所示,会2个线程同时更新B和插入C,修改前一项next时需要CAS,两个操作都会成功,但是不成环了
如图所示,会2个线程同时更新B和插入C,修改前一项next时需要CAS,两个操作都会成功,但是不成环了
-
RCU-update & update 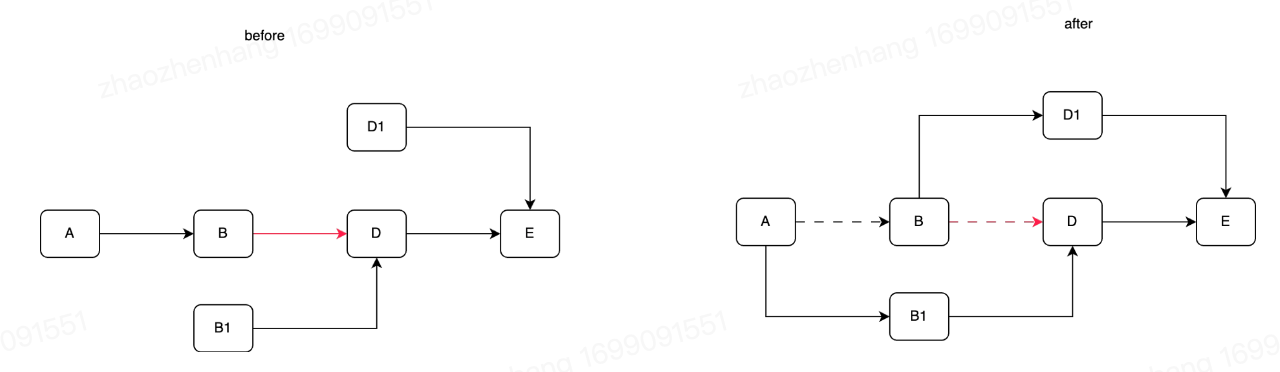 如图所示,两个线程的next的CAS操作都可以成功,但是会导致不成环,而且B1的next指针还是一个无效指针。
如图所示,两个线程的next的CAS操作都可以成功,但是会导致不成环,而且B1的next指针还是一个无效指针。
-
RCU-update & delete 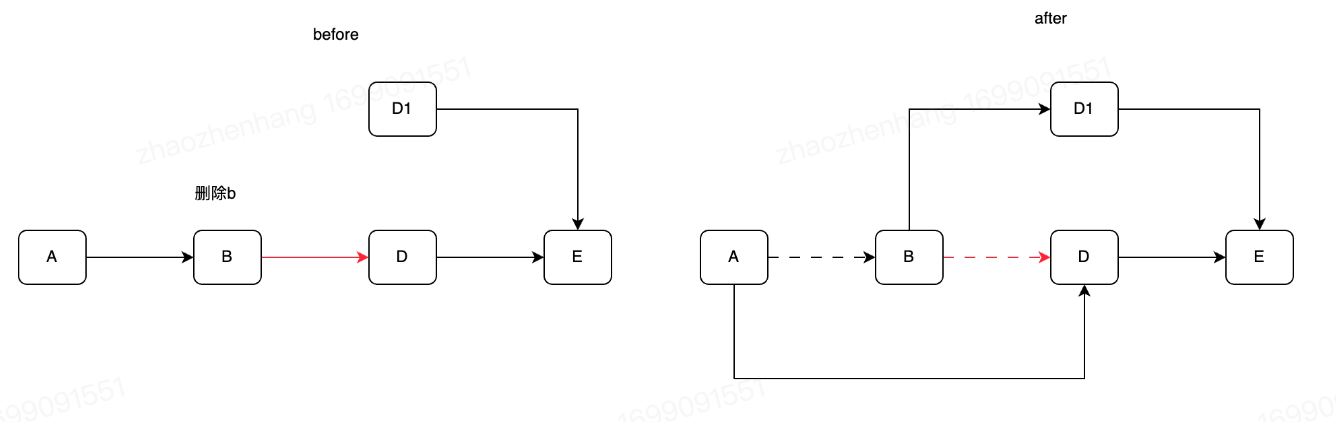 如图所示,两个线程删除B和更新D,他们的next的CAS也可以成功,但最后结果也会无法成有序环,而且A的next是一个无效指针。 因此只有next来进行CAS操作是无法保证原子性的,这儿就引入了next的occupied字段。
如图所示,两个线程删除B和更新D,他们的next的CAS也可以成功,但最后结果也会无法成有序环,而且A的next是一个无效指针。 因此只有next来进行CAS操作是无法保证原子性的,这儿就引入了next的occupied字段。
-
对于RCU-update & insert操作 -
在使用更新或者插入时,使用CAS修改B的next值,且置B.next.occupied = 1 -
然后第二个线程操作时,使用CAS连接前一个节点,发现B.next.occupied = 1,这个时候会操作失败重试 -
操作完成后重置occupied=0
-
-
对于RCU-update & update操作 -
同样的处理,CAS更新occupied值 -
然后判断occupied值来决定是否失败重试 -
操作完成重置occupied 对于RCU-update & delete 和上述一样的结论
-
头指针移动
有三种可能
热点识别导致头指针移动
对于热点识别导致的头指针移动,只需要将移动的新的item的occupied设置为1,确保新的head item不会被更新和删除导致野指针
head item更新导致头指针移动
对于head item更新导致的,设置新版本的occupied位就行,确保在移动过程中不会被其他线程影响,移动完后重置occupied
head item删除导致头指针移动
删除导致的有点特殊,除了设置被删除的头节点的occupied,还需要设置下一项的occupied,因为下一项是新的头节点,需要确保其不被更新/删除,移动完成后重置occupied。
Lock-free Rehash
随着数据的插入,hash collision的数量持续增加,导致的问题就是会访问遍历更多的item,导致系统性能下降,在HotRing中提出了一种无锁rehash的策略,不同于常规的hash表的负载因子(平均链长触发),因为常规的负载因子没有考虑热点的影响。所以HotRing使用访问开销(平均检索项目的平均内存访问次数)来触发rehash。整个策略包含三个步骤:
初始化阶段
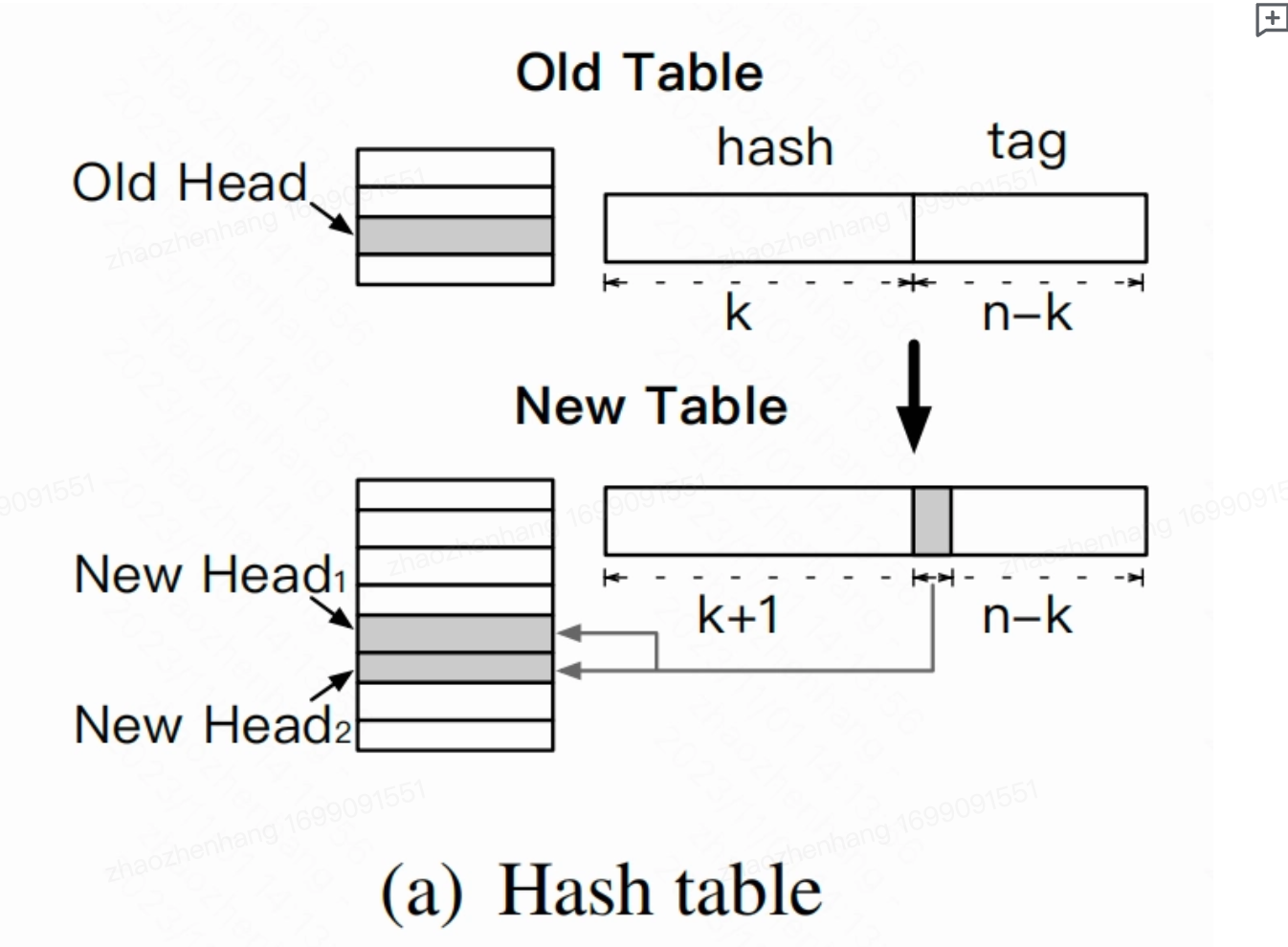 HotRing有一个后台rehash的线程,会初始化一个2倍大小的散列表,这儿重新定义以下key和tag的关系,当扩容两倍时,由于位运算操作,一个item的hash值的前k位会用作hash表索引,后t位作为tag,扩容后索引部分会增加1位,而为了不影响存储空间那么对应的tag位就要减少一位,这儿用到了位运算操作(和之前取tag差不多的方式): index =hashVal & sizeMask tag = hashVal & (~sizeMask) 上面hashVal是key的hash值,通过& sizeMask 确定hash桶范围,与操作的特点对应位是1就是1,否则为0。 ~ 取反操作就是1变0,0变1。 当size变为2倍,sizeMask=size-1.会导致sizeMask位数+1,所以扩容后index位数+1,取反后对应的tag值会减1。
HotRing有一个后台rehash的线程,会初始化一个2倍大小的散列表,这儿重新定义以下key和tag的关系,当扩容两倍时,由于位运算操作,一个item的hash值的前k位会用作hash表索引,后t位作为tag,扩容后索引部分会增加1位,而为了不影响存储空间那么对应的tag位就要减少一位,这儿用到了位运算操作(和之前取tag差不多的方式): index =hashVal & sizeMask tag = hashVal & (~sizeMask) 上面hashVal是key的hash值,通过& sizeMask 确定hash桶范围,与操作的特点对应位是1就是1,否则为0。 ~ 取反操作就是1变0,0变1。 当size变为2倍,sizeMask=size-1.会导致sizeMask位数+1,所以扩容后index位数+1,取反后对应的tag值会减1。
原hash的tag取值为(0,T)(T = 2 ^ t),扩容后变成2 ^ t−1 ,刚好可以按照(0,T/2)和(T/2, T)划分为两个新的环。 同时rehash线程会创建一个rehash 节点,这个节点包含两个item,分别作为新环的临时头节点(Hazard Pointers),并将rehash bit 设置 为 1 代表不存储真实KV键值对,而这两个item的tag就设置为0和T/2。
分裂阶段
分裂阶段就是将两个rehash item插入环来进行拆分环。遍历原有环,根据扩容值计算环的tag范围找到边界,然后完成rehash item的插入工作。此时新hash表开始生效,后续访问如果来自新表就根据tag值来选择对应的head指针,而旧的访问则通过识别rehash项来进行,此时就不影响并发读取和写入了。(此时还没删除节点,逻辑上分成两个环,其实只是一个环,新表通过tag区分,旧表通过rehash区分)
删除阶段
在次阶段,rehash线程删除rehash节点,不过在删除需要保证旧表上的访问要终止,RCU宽限期(Grace Period)(在读取过程中,另外一个线程删除了一个节点。删除线程可以把这个节点从链表中移除,但它不能直接销毁这个节点,必须等到所有的读取线程读取完成以后,才进行销毁操作。),确保所有旧表访问完成后rehash线程就可以安全删除旧hash表和rehash节点了。这个过程只会阻塞rehash线程,不会阻塞主线程。
benchmark
github链接:https://github.com/azhsmesos/hotring(除了tag和引入额外的4字节来存储active、occupied、rehash、counter等标记位之外,其余实现思想和论文一致) 论文给的测试数据: 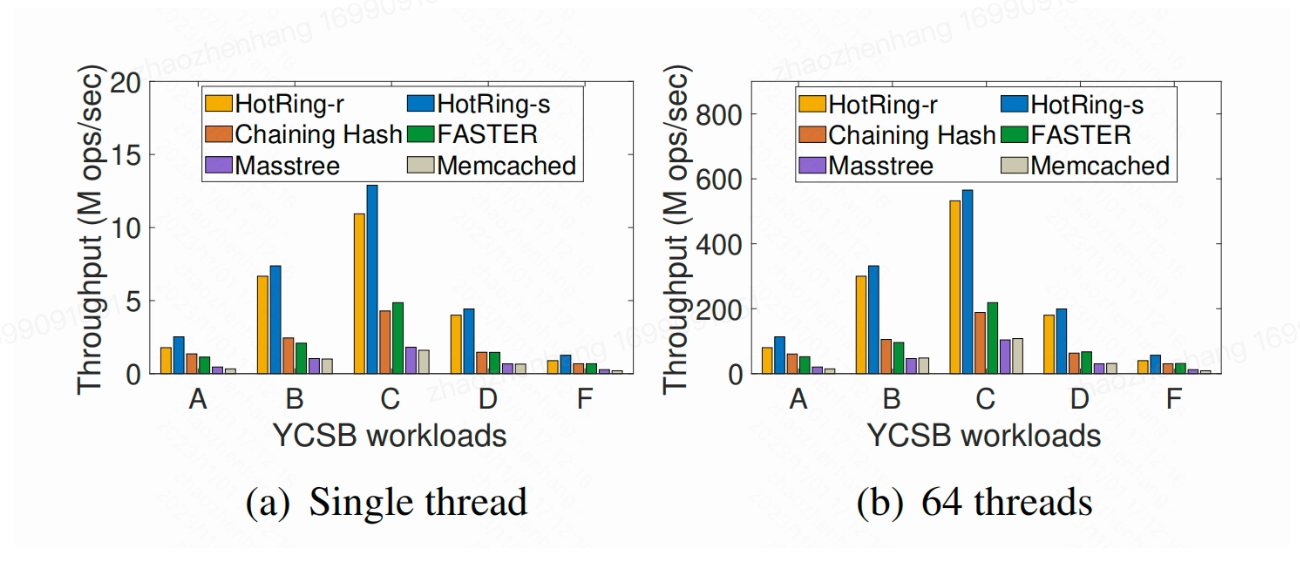 下面是个人实现的测试数据(代码写的很丑,也比较烂导致性能耗时没有降低,但是在幂律分布场景工作负载不均衡下,其访问内存的开销相比java官方的hashmap大概降低了一半) 因为时间问题,还没有完全实现完,比如RCU、Hazard Pointers、CAS等还没写好(但也实现了一部分)
下面是个人实现的测试数据(代码写的很丑,也比较烂导致性能耗时没有降低,但是在幂律分布场景工作负载不均衡下,其访问内存的开销相比java官方的hashmap大概降低了一半) 因为时间问题,还没有完全实现完,比如RCU、Hazard Pointers、CAS等还没写好(但也实现了一部分)
工作负载偏度 theta = 2 ,theta:幂律分布因子,theta=2说明工作负载及其不平衡(巴哥直播场景) 数据量级 10 ^ 7 数据 测试指标:
-
总的查找次数 反应完成任务的系统开销 -
平均查找次数 -
总耗时
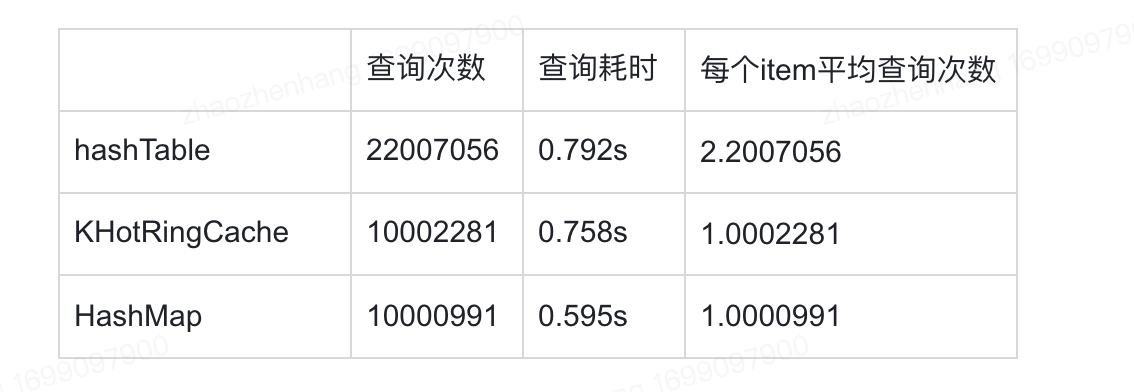
theta = 2
theta = 1
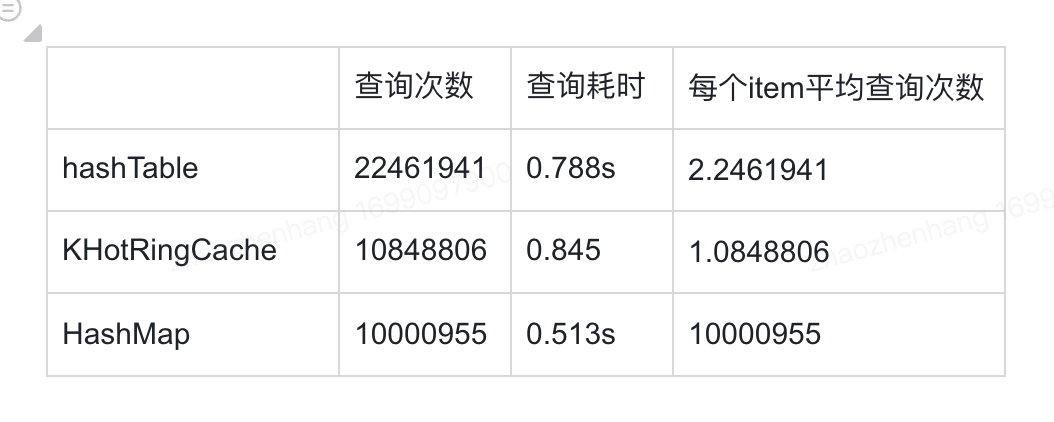
theta = 0

结论 当theta=2时,和jdk官方hashmap比较,由于jdk官方hashmap我不方便统计其红黑树的访问次数,仅仅访问了其get(方法的次数),也基本和khotRingCache持平,如果将其红黑树内部的item元素的遍历访问次数加上,肯定比KHotRingCache要多,从链表和红黑树时间复杂度来看,大概在10^7次方数据下,theta=2时,KHotRingCache基本查询是O(1)复杂度,查询次数比hashmap少了300-500w次。这也说明KHotRingCache在工作负载不均衡,也就是有热点数据区间时,其查找次数要低于没有热点检测的map结构。至于耗时问题,可能我的链表增删改查实现和jdk官方还有很大差距,所以导致耗时会高上50%左右。
但是当theta=0时,发现KHotRingCache耗时最高,那是因为KHotRingCache要做热点偏移,会耗费一些性能,但耗费不是很多,执行次数和HashTable的链表的方式也区别不大,因此hotRing适合于在热点分布很高(幂律分布)下使用。
官方结论
当键-桶比率为2时,与Chaining Hash和FASTER相比,其读取吞吐量为1.93和1.31倍。当比率变为16时,性能差距将分别增加到4.02和3.91倍。这是因为HotRing将热点放在头部附近,因此需要较少的内存访问。这种设计对缓存更友好,其中仅头部指针和热点项目需要缓存,从而提供更高的性能。因此,我们得出结论,由于HotRing具有热点感知设计,因此它具有更好的性能和可伸缩性。 在高度倾斜的工作负载中相比,该方法可以实现2.58倍提高。 引用
当前淘宝的tair应该已经在生成环境大规模使用了,官方论文给出的数据,在高度负载的环境下,相比于memcached、masstree、faster、chaining hash等KVS平均有2.58倍的性能提升。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









