






TSDB
基于lsm的实现,memtable存储热数据(2h),磁盘存储冷数据 考虑wisckey kv分离,ssd并行写代替顺序io lock-free 基于aep这类的Persistent Memory 代替wal 读写分离 实现高效的内存查询数据结构(avltree、skiplist、红黑树) 基于可插拔式的压缩算法(ZSTD压缩、Snappy压缩) mmap内存拷贝 类似es的倒排索引 垂直写,水平查,序列分流,冷热读写 自定义Marshal编解码 RoaingBitMap 优化 优化的正则查询(fastRegexMatcher)
想尝试写一个tsdb,当然实现较为简单,底层还是基于LSM的方式,如果不了解LSM的可以看下bitcask模型,或者了解下LSM论文,我个人简单实现过一个简单的LSM写操作,基于bitcask模型,代码量很少,可以简单了解下~:https://github.com/azhsmesos/bitcask_db
TSDB: Time Series Database
-
数据点(Point): 时序数据的数据点是一个包含 (Timestamp:int64, Value:float64) 的二元组。 -
时间线(Series): 不同标签(Label)的组合称为不同的时间线
借用Prometheus的格式就是这样:
series1:{"__name__": "cpu.idle", "host": "jvm_host"}
series1:{"__name__": "cpu.idle", "host": "jvm_host"}
数据模型定义
// Point 表示一个数据点 (ts, value) 二元组
type Point struct {
Ts int64 // in seconds
Value float64
}
// Label 代表一个标签组合
type Label struct {
Name string
Value string
}
// Row 一行时序数据 包括数据点和标签组合
type Row struct {
Metric string
Labels LabelSet
Point Point
}
// LabelSet 表示 Label 组合
type LabelSet []Label
数据写入

时序数据库具有垂直写,水平查的特性,比如clickhouse,我们经常将其用来和grafana一起做监控的底层存储,我们很多时候的查询都是基于一段持续时间内的数据点,可能这个数据点的label都是同一个,也可能是多个。
序列分流
由于时序数据库的场景,导致它可能同一条label的数据在某个时间序列上非常大,所以我们考虑序列分流,基于时间维度创建不同的segment,然后基于该时间维度做冷热分离
开始开发
一、One day 写内存
因为我们要兼顾LSM的方式,所以采用的模型比较简单,直接以Row的形式忘chan中写数据,然后异步进行刷盘。
日志存储格式这样:
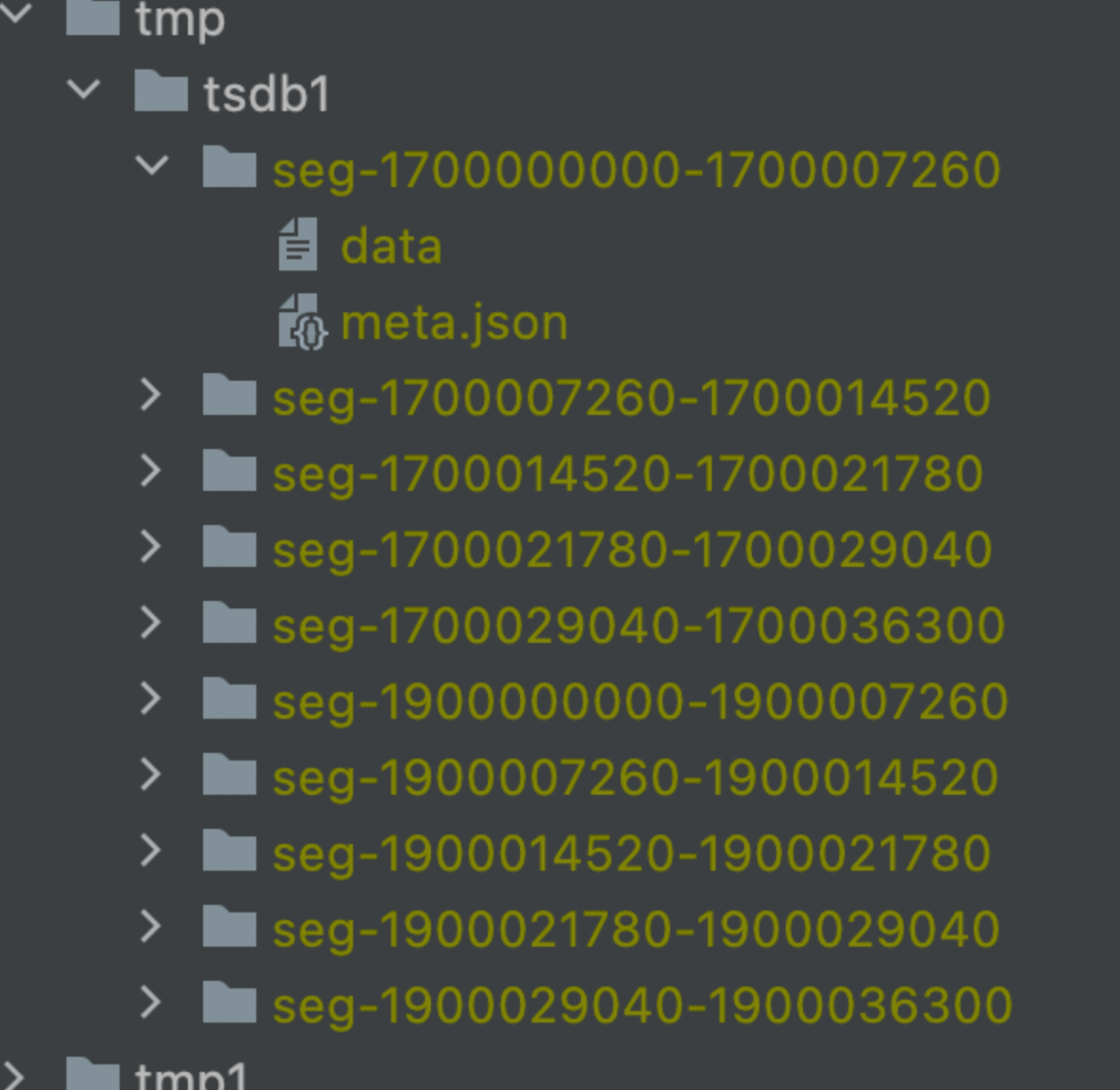
其中一个segment中包含很多个rows,然后由一个meta.json的数据文件描述该segment的时间跨度、数据大小等数据。
tsdb.go方法以及相关对象定义
package tsdb
import (
"context"
"errors"
"github.com/sirupsen/logrus"
"sync"
"time"
)
type options struct {
metaSerializer MetaSerializer // 元数据自定义Marshal接口
bytesCompressor BytesCompressor // 数据持久化存储压缩接口
retention time.Duration // 数据保留时长
segmentDuration time.Duration // 一个segment的时长
writeTimeout time.Duration // 写超时
onlyMemoryMode bool
enableOutdated bool // 是否可以写入过时数据(乱序写入)
maxRowsPerSegment int64 // 每段的最大row的数量
dataPath string // Segment 持久化存储文件夹
}
type TSDB struct {
segments *segmentList
mutex sync.RWMutex
ctx context.Context
cancel context.CancelFunc
queue chan []*Row
wait sync.WaitGroup
}
// Point 一个数据点
type Point struct {
Timestamp int64
Value float64
}
// Label 一个标签组合
type Label struct {
Name string
Value string
}
type LabelList []Label
var (
timerPool sync.Pool
defaultOpts = &options{
metaSerializer: newBinaryMetaSerializer(),
bytesCompressor: newNoopBytesCompressor(),
segmentDuration: 2 * time.Hour, // 默认两小时
retention: 7 * 24 * time.Hour,
writeTimeout: 30 * time.Second,
onlyMemoryMode: false,
enableOutdated: true,
maxRowsPerSegment: 19960412, // 该数字可自定义
dataPath: ".",
}
)
// Row 一行时序数据库,包括数据点和标签组合
type Row struct {
Metric string
Labels LabelList
Point Point
}
// InsertRows 插入rows
func (tsdb *TSDB) InsertRows(rows []*Row) error {
timer := getTimer(defaultOpts.writeTimeout)
select {
case tsdb.queue <- rows:
putTimer(timer)
case <-timer.C:
putTimer(timer)
return errors.New("failed to insert rows to database, write overload")
}
return nil
}
func getTimer(duration time.Duration) *time.Timer {
if value := timerPool.Get(); value != nil {
t := value.(*time.Timer)
if t.Reset(duration) {
logrus.Error("active timer trapped to the pool")
return nil
}
return t
}
return time.NewTimer(duration)
}
func putTimer(t *time.Timer) {
if !t.Stop() {
select {
case <-t.C:
default:
}
}
}
list.go内存中的排序链表
// List 排序链表结构
type List interface {
}
segment.gosegment格式定义
import "sync"
type Segment interface {
InsertRows(row []*Row)
}
type segmentList struct {
mutex sync.RWMutex
head Segment
list List
}
compressor.go数据压缩文件定义
// noopBytesCompressor 默认不压缩
type noopBytesCompressor struct {
}
// BytesCompressor 数据压缩接口
type BytesCompressor interface {
Compress(data []byte) []byte
Decompress(data []byte) ([]byte, error)
}
func newNoopBytesCompressor() BytesCompressor {
return &noopBytesCompressor{}
}
func (n *noopBytesCompressor) Compress(data []byte) []byte {
return nil
}
func (n *noopBytesCompressor) Decompress(data []byte) ([]byte, error) {
return nil, nil
}
metadata.go描述segment的meta信息
type metaSeries struct {
Sid string
StartOffset uint64
EndOffset uint64
Labels []uint32
}
type seriesWithLabel struct {
Name string
Sids []uint32
}
type Metadata struct {
MinTimestamp int64
MaxTimestamp int64
Series []metaSeries
Labels []seriesWithLabel
}
type binaryMetaserializer struct {
}
// MetaSerializer 编解码Segment元数据
type MetaSerializer interface {
Marshal(Metadata) ([]byte, error)
Unmarshal([]byte, *Metadata) error
}
func newBinaryMetaSerializer() MetaSerializer {
return &binaryMetaserializer{}
}
func (b *binaryMetaserializer) Marshal(meta Metadata) ([]byte, error) {
return nil, nil
}
func (b *binaryMetaserializer) Unmarshal(data []byte, meta *Metadata) error {
return nil
}
可以看到,核心就是将数据以row数组的形式批量刷新到chan中去,然后由我们的chan进行异步刷盘操作...
待定~
二、实现启动函数和压缩算法
数据压缩算法,目前是两个算法,ZSTD和Snappy两种,也是直接调用的库函数,实现比较简单
package tsdb
import (
"github.com/golang/snappy"
"github.com/klauspost/compress/zstd"
)
type BytesCompressorType int8
const (
// NoopBytesCompressor 默认不压缩
NoopBytesCompressor BytesCompressorType = iota
// ZSTDBytesCompressor 使用ZSTD压缩算法
ZSTDBytesCompressor
// SnappyBytesCompressor 使用snappy压缩算法
SnappyBytesCompressor
)
// noopBytesCompressor 默认不压缩
type noopBytesCompressor struct{}
type zstdBytesCompressor struct{}
type snappyBytesCompressor struct{}
// BytesCompressor 数据压缩接口
type BytesCompressor interface {
Compress(data []byte) []byte
Decompress(data []byte) ([]byte, error)
}
// 默认压缩算法
func newNoopBytesCompressor() BytesCompressor {
return &noopBytesCompressor{}
}
func (n *noopBytesCompressor) Compress(data []byte) []byte {
return data
}
func (n *noopBytesCompressor) Decompress(data []byte) ([]byte, error) {
return data, nil
}
// ZSTD 压缩算法
func newZSTDBytesCompressor() BytesCompressor {
return &zstdBytesCompressor{}
}
func (n *zstdBytesCompressor) Compress(data []byte) []byte {
encoder, _ := zstd.NewWriter(nil, zstd.WithEncoderLevel(zstd.SpeedFastest))
return encoder.EncodeAll(data, make([]byte, 0, len(data)))
}
func (n *zstdBytesCompressor) Decompress(data []byte) ([]byte, error) {
decoder, _ := zstd.NewReader(nil)
return decoder.DecodeAll(data, nil)
}
// snappy 压缩算法
func newSnappyBytesCompressor() BytesCompressor {
return &snappyBytesCompressor{}
}
func (n *snappyBytesCompressor) Compress(data []byte) []byte {
return snappy.Encode(nil, data)
}
func (n *snappyBytesCompressor) Decompress(data []byte) ([]byte, error) {
return snappy.Decode(nil, data)
}
可以看到,核心就是将数据以row数组的形式批量刷新到chan中去,然后由我们的chan进行异步刷盘操作...
下一篇实现可插拔的压缩算法和启动tsdb的具体实现
本文由 mdnice 多平台发布















 9563
9563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









