






Word Representation方法,Word2Vec, GloVe, fastText等对每个单词仅有一种表示,而通常单词的含义依赖其上下文会有所不同,而且每个单词不仅有一方面特征,而应有各方面特征如语义特征,语法特征等,
集中讨论contextual word representation,主要比较了ELMO,GPT与BERT模型。
EMLo
在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。ELMo的整体图如下图,它使用了多层LSTM,且增加了后向语言模型(backward LM)。
对于多层lstm,每层的输出都是隐向量htht,在ELMo里,为了区分,前向lstm语言模型的第j层第k时刻的输出向量命名为hLMk,j−→−hk,jLM→。
对于后向语言模型,跟前向语言模型类似,除了它是给定后文来预测前文。我们设定后向lstm的第j层的第k时刻的输出向量命名为hLMk,j←−−hk,jLM←。

ELMO缺点
首先,一个非常明显的缺点在特征抽取器选择方面,ELMO 使用了 LSTM 而不是新贵 Transformer,Transformer 是谷歌在 17 年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响,很多研究已经证明了 Transformer 提取特征的能力是要远强于 LSTM 的。如果 ELMO 采取 Transformer 作为特征提取器,那么估计 Bert 的反响远不如现在的这种火爆场面。另外一点,ELMO 采取双向拼接这种融合特征的能力可能比 Bert 一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
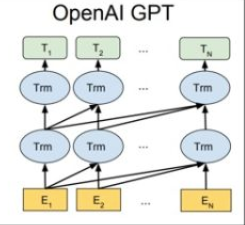
OpenAI GPT
OpenAI Transformer是一类可迁移到多种NLP任务的,基于Transformer的语言模型,其利用Transformer的结构来进行单向语言模型的训练,它主张用Transformer结构。
优点
循环神经网络所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。
计算速度比循环神经网络更快,易于并行化
实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点
对于某些类型的任务需要对输入数据的结构作调整
BERT
模型的全称是:BidirectionalEncoder Representations from Transformer。从名字中可以看出,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation,即:文本的语义表示,然后将文本的语义表示在特定NLP任务中作微调,最终应用于该NLP任务。
BERT模型训练文本语义表示的过程就好比我们在高中阶段学习语数英、物化生等各门基础学科,夯实基础知识;而模型在特定NLP任务中的参数微调就相当于我们在大学期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
优点
用的是Transformer,也就是相对rnn更加高效、能捕捉更长距离的依赖。对比起之前的预训练模型,它捕捉到的是真正意义上的bidirectional context信息。模型有两个 loss,一个是 Masked Language Model,另一个是 Next Sentence Prediction。
缺点
BERT算法还有很大的优化空间,例如我们在Transformer中讲的如何让模型有捕捉Token序列关系的能力,而不是简单依靠位置嵌入。
每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢。BERT的成功还有一个很大的原因来自于模型的体量以及训练的数据量,但BERT的训练在目前的计算资源下很难完成。















 636
636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









