







 本文介绍一种基于字符级的语言模型,该模型在命名实体识别等序列标注任务上表现出色,达到93.09的F1值,超越BERT。模型通过预训练在无标签数据上获取字符表示,并在特定任务上微调。实验证明,加入额外的词向量如Glove或字符级特征并无显著提升。
本文介绍一种基于字符级的语言模型,该模型在命名实体识别等序列标注任务上表现出色,达到93.09的F1值,超越BERT。模型通过预训练在无标签数据上获取字符表示,并在特定任务上微调。实验证明,加入额外的词向量如Glove或字符级特征并无显著提升。
原文链接:https://www.aclweb.org/anthology/C18-1139
今天看的论文是COLING 2018的一篇论文,介绍了一种新的粒度的语言模型,基于 character级别的语言模型。作者实验发现character-level的语言模型在sequence labeling任务,比如命名实体识别、词性标注等任务上表现较好,在CoNLL2013命名实体识别任务上打到了state-of-the-art性能F1值93.09,超过了BERT的性能。
首先介绍一下目前主流的几种词向量类型:
- 传统的词向量。在大规模的语料上进行训练,以获得句法和语义相似度。例如Glove[1]、Word2Vec等。
- character-level特征。该词向量是未经过预训练,而是在特定任务上训练,以获得任务相关的subword特征。
- 上下文相关的词向量,比如Elmo[2]。该词向量能够根据上下文的不同而获得不同的词向量表示。
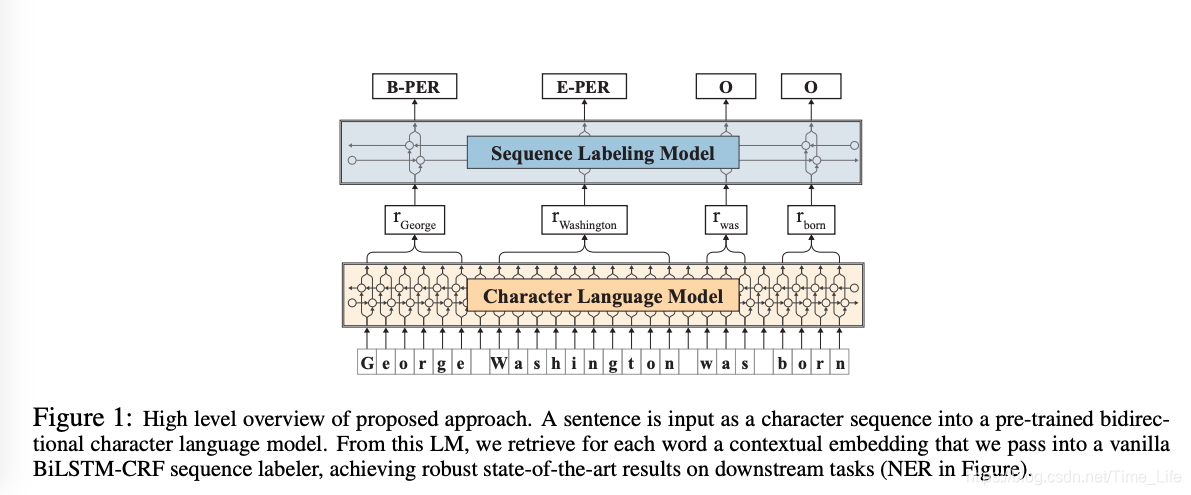
作者使用的模型很简单,但是却很有效,模型结构图如下图所示。主要有几个关键的地方:
- 在无标签的数据上对characer级别输入进行语言模型预训练。(正是因为是在无标签的数据上,所以数据量大效果会比较好)
- 把每个token中的最后一个character的由前向LSTM(Long Short Term Memory Network)和后向LSTM的隐状态拼接动态得到该token的表示,既可以解决一词多义问题,又可以解决OOV(out of vocabulary)问题。
采用LSTM对句子进行编码。在预训练语言模型时,作者采用把character序列作为句子输入,在character-level去预测下一个character。
P
(
x
0
:
T
)
=
∏
t
=
0
T
P
(
x
t
∣
x
0
:
t
−
1
)
P(x_{0:T}) = \quad \prod_{t=0}^T P(x_t|x_{0:t-1})
P(x0:T)=t=0∏TP(xt∣x0:t−1)
在LSTM中,
t
t
t时刻的隐状态
h
t
h_t
ht作为序列
x
0
:
t
−
1
x_{0:t-1}
x0:t−1的表示,因此上式等价于:
P
(
x
0
:
T
)
≈
∏
t
=
0
T
P
(
x
t
∣
h
t
;
θ
)
P(x_{0:T}) \approx \quad \prod_{t=0}^T P(x_t|h_{t};\theta)
P(x0:T)≈t=0∏TP(xt∣ht;θ)
其中
θ
\theta
θ为LSTM的参数。
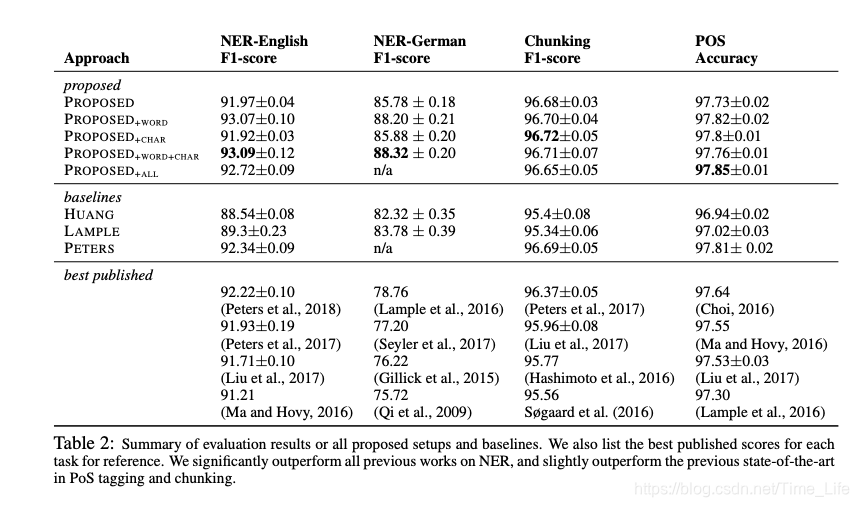
文章还做了一些消融实验,比如再加上Glove词向量或者character-level的特征,得到结果如下图。证明加上character-level的特征是没有必要了,作者认为他的character-level语言模型已经能够获取到char的表示了。
作者针对这个语言模型基于pytorch发布了一个工具flair,加入了各种别的词向量表示、语言模型等特征,而且提高了如何加入自己的模块、如何训练等。地址如下:https://github.com/zalandoresearch/flair。带有教程,使用比较方便。后面打算基于此在语义相似度数据上去做一个实验。
[1]《Glove: Global vectors for word representation》
[2]《Deep contextualized word representations》

















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









