







目录
8.7 #if、#ifdef、#if defined( ) 的使用
一. 数据类型
1.1 常见数据类型
long 类型,32位计算机里占4字节,64位计算机里占8字节。
| 关键字 | 字节大小 | 表示范围 |
| (unsigned) char | 1 | (-128~127) 0~255 |
| (unsigned) short | 2 | (-32768~32767) 0~65535 |
| (unsigned) int | 4 | (-21亿多~21亿多) 42亿多 |
| (unsigned) long | 4 | (-21^31~21^31-1) 0~2^32-1 |
| (unsigned) long long | 8 | -(2^64)/2 ~ (2^64)/2-1 |
| float | 4 | -3.4e38 ~ 3.4e38 |
| double | 8 | -1.7e308 ~ 1.7e308 |
实型变量 = 整数部分 + 小数部分
参考源链接: 【C语言】数据类型
1.2 格式化输入输出
可将输出的数据转换为指定的格式输出。格式说明总是由“%”字符开始的。不同类型的数据用不同的格式字符,如 scanf("%d %c", &a, &b); printf(" %d %c\n", a, b);
| 格式 | printf函数 | scanf函数 |
| 单字符 | %c (等价于putchar) | %c (等价于getchar) |
| 字符串 | %s (类似于puts) | %s (类似于gets) |
| 有符号的十进制整数 | %d | %d |
| 有符号的64位十进制整数 | %lld | %lld |
| 无符号的十进制整数 | %u | %u |
| 无符号长整型 | %lu | %lu |
| 无符号的64位十进制整数(长长整型) | %llu | %llu |
| 单精度浮点数 (十进制记数法) | %f | %f |
| 单精度浮点数(紧凑小数输出) | %g | %g |
| 双精度浮点数 (十进制记数法) | %lf | %lf |
| 无符号的十六进制整数(使用“ABCDEF”) | %x | %x |
| 无符号的八进制整数 | %o | %o |
| 打印地址(指针指向的地址/&x(变量)) | %p |
1.2.1 printf 的运算顺序 是 从右到左
int arr[] = {6,7,8,9,10};
int *ptr = arr;
*(ptr++)+=123;
printf( "%d %d", *ptr,*(++ptr) );
输出: 8 8
解析:*(ptr++)+=123,6+123,ptr指向7;
printf( "%d %d", *ptr,*(++ptr) ),先执行*(++ptr),ptr指向8,再执行*ptr1.2 printf输出左对齐、右对齐、补位
博客链接:C语言输出左对齐右对齐,补位
二. 变量、常量
2.1 变量的分类
| 作用域 | 生命周期 | |
| 局部变量 | 变量所在的局部范围 | 进入作用域生命周期开始,出作用域生命周期结束 |
| 全局变量 | 整个工程 | 整个程序的生命周期 |
2.2 常量的分类
const 修饰的常变量 (实际上仍是变量,只是使用const添加了常属性。常属性:不能被改变的属性)
#define 定义的标识符常量
枚举常量
常量在定义之后不能修改
//VS2013环境编译下
int main()
{
#define weekday 7 //#define修饰的常变量
const int week = 7; //const修饰的常变量
enum Sex 括号中的MALE,FEMALE,SECRET,test是枚举常量
{
MALE, //无赋初始值,则默认为0
FEMALE, //无赋初始值,则默认为male+1,即为1
SECRET = 2, //赋初值为2
test //无赋初始值,则默认为female+1,即为2
};
enum Sex s = MALE; //定义枚举变量s,s的值只能是MALE FEMALE SECRET test中的一种,值为0
printf("%d\n", MALE); //0
printf("%d\n", FEMALE); //1
printf("%d\n", SECRET); //2
printf("%d\n", test); //2
return 0;
}三. 字符串 + 转义字符
char arr[ ] = "hello" ;
这种由双引号引起来的一串字符称为字符串字面值(String Literal),或者简称字符串。
注:字符串的结束标志是一个\0 的转义字符。在计算字符串长度的时候\0 是结束标志,不算作字符串内容。
3.1 字符串和字符数组的区别

arr1为字符串,在abc后面有看不见的 \0 ,打印字符串时遇到c后面的 \0 停止;
arr2为字符数组,只有abc,打印字符串时会一直打印到c后面的数据,直到遇到 \0 停止。
用sizeof()求大小
sizeof(arr1) = 4, sizeof(arr2) = 3。
3.2 字符串常见函数
注:在使用字符串处理函数时,需要添加头文件 #include <string.h>
3.3 转义字符
作用:在输出想要的字符时,可以防止被编译器误解析,比如想输出 " 时,需添加 \
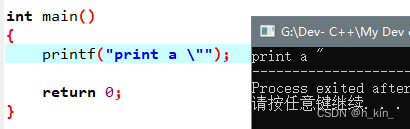
转义字符汇总表:
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \\ | 代表一个反斜线字符''\' | 092 |
| \' | 代表一个单引号(撇号)字符 | 039 |
| \" | 代表一个双引号字符 | 034 |
| \? | 代表一个问号 | 063 |
| \0 | 空字符(NUL) | 000 |
| \ddd | 1到3位八进制数所代表的任意字符 | ddd表示1~3个八进制的数字 如:\130 ,表示八进制的130 |
| \xhh | 十六进制所代表的任意字符 | dd表示2个十六进制的数字 如:\x30 ,表示十六进制的30 |
四. 初识函数和数组
4.1 自定义的函数
一个函数如果不写返回类型,默认为int

4.2 数组
4.2.1 一维数组
数组,就是一组相同类型元素的集合。一维数组的定义有如下
数据类型 数组名 [常量表达式]
int arr [6] = {1, 2, 3, 4, 5, 6};
若数组 未初始化,则元素值为随机数。int arr[10];
若数组 部分初始化,则未初始化的元素值为0。 int arr[3] = {1}; 实际上为 int arr[3] = {1,0,0};
数组的引用
数组名[下标] 。如 arr[0] = 1; arr[5] = 6; //数组下标均以0开始,a[0] ~ a[5]
数组大小
sizeof (arr) 。如sizeof(arr)为24 //数组元素类型 * 元素个数。(单位:字节)
数组元素个数
sizeof (arr) / sizeof ( arr[0] ) 6 //数组总大小 除以 单个数组元素的大小
4.2.2 二维数组
二维数组的定义
数据类型 数组名 [常量表达式] [常量表达式]
char arr [3][4] ;//定义一个二维数组,该数组有3行4列,3个子数组:每个子数组有4个元素。
二维数组的初始化
int arr [3] [4] = {1, 2, 3, 4};
int arr [3] [4] = { {1, 2}, {3, 4} };
int arr [ ] [4] = { {1, 2}, {3, 4} }; //二维数组如果有初始化,行可以省略,列不能省略
二维数组的存储
在内存中数据的存储是一维的,二维数组的存储是按行序优先,如int arr [2] [2]在内存中的存储是
→
| arr [0] [0] | arr [0] [1] | arr [1] [0] | arr [1] [1] |
4.2.3 二维数组打印
int days[4][3]={
{31,28,31},
{30,31,30},
{31,31,30},
{31,30,31}
};
for(int i=0;i<n;i++) // 行 在前
{
for(int j=0;j<m;j++) // 列 在后
{
printf("%d", days[i][j]);
}
}4.3 数组的应用
4.3.1 数组名的含义
除了两种情况外,数组名均表示首元素地址。
① &数组名, &arr 表示取出整个数组的地址,而不是数组首元素的地址
② sizeof(数组名), sizeof (arr) 表示整个数组的大小
4.4 数组的传参 (值传递和地址传递)
值传递
通常,对一般变量的值传递,函数会拷贝一个与实参的值相同的临时变量来使用,因此,在函数内部改变该变量并不会真正改变原变量的实际值。
但是,对数组来说,通过值传递的函数,也能改变原数组的实际值。
因为数组在传参的时候,仅仅只是传的首元素的地址。

地址传递

4.5 sizeof注意事项
void UpperCase( char str[] ) // 功能:将str中的小写字母转换成大写字母
{
for( size_t i=0; i<sizeof(str)/sizeof(str[0]); ++i )
if( 'a'<=str[i] && str[i]<='z' )
str[i] -= ('a'-'A' );
}
char str[] = "aBcDe";
cout << "str 字符长度为: " << sizeof(str)/sizeof(str[0]) << endl;
UpperCase( str );
cout << str << endl;以上程序有什么问题:
答:函数内的 sizeof 有问题。根据语法, sizeof 如用于数组,只能测出静态数组的大小,无法检测动态分配的或外部数组大小。函数外的 str 是一个静态定义的数组,因此其大小为 6, 函数内的 str 实际只是一个指向字符串的指针,没有任何额外的与数组相关的信息,因此 sizeof 作用于上只将其当指针看,一个指针为 4 个字节,因此返回 4。
五. 操作符和关键字
5.1操作符 链接:操作符详解(所有操作符的所有使用方法)
逻辑与,在遇到假条件之前的都会运算,遇到假之后的才不会;
逻辑或,在遇到真条件之前的都会运算,遇到真之后的才不会。

三目运算符 max = (a>b ? a:b); 如果条件为真,表达式a 会运算,表达式b 不会;
如果条件为假,表达式a 不会运算,表示式b 会;
逗号表达式,从左到右依次计算,但表达式的结果是 最后一个表达式的结果。
(printf 里是从右到左一次计算)
5.2关键字 链接:C语言的关键字

注意define 、include不是关键字,是预处理指令。( #define , #include )
关键字typedef 顾名思义是类型定义,这里应该理解为类型重命名。
关键字static
1. static修饰局部变量,改变了变量的生命周期,不改变作用域。
让静态局部变量出了作用域依然存在,到程序结束,生命周期才结束。
2. static修饰全局变量,改变了变量的作用域,不改变生命周期。
修饰后该全局变量只能在本源文件内使用,不能在其他源文件内使用。
(全局变量具有外部链接属性,被static修饰后变成了内部链接属性)
3. static修饰函数,该函数只能在本源文件内使用(当前.c文件),不能在其他源文件使用。
▲static修饰的局部变量,改变了局部变量的生命周期,本质上是改变了变量的存储类型:

关键字const
const修饰变量
常量不能被直接修改,但可以通过指针的方式间接修改

const修饰指针
1. const 在 * 左边,修饰的是指针指向的内容,保证指针指向的内容不能通过指针来改变,
但指针本身可变,可以指向其他数。

2. const 在 * 右边,修饰的是指针变量本身,保证了指针变量的内容不能修改。

关键字volitale
1、 保证变量的可见性:当一个被volatile关键字修饰的变量被一个线程修改的时候,其他线程可以立刻得到修改之后的结果。当一个线程向被volatile关键字修饰的变量写入数据的时候,虚拟机会强制它被值刷新到主内存中。当一个线程用到被volatile关键字修饰的值的时候,虚拟机会强制要求它从主内存中读取。
2、 屏蔽指令重排序:指令重排序是编译器和处理器为了高效对程序进行优化的手段,它只能保证程序执行的结果时正确的,但是无法保证程序的操作顺序与代码顺序一致。这在单线程中不会构成问题,但是在多线程中就会出现问题。非常经典的例子是在单例方法中同时对字段加入voliate,就是为了防止指令重排序。
一、可见性
简单来说:当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
六. 指针
内存,是电脑上特别重要的存储器,计算机中程序的运行都是在内存中进行的 。
所以为了有效使用内存,就把内存划分成一个个小的内存单元,每个内存单元的大小是1个字节。
为了能够有效的访问到内存的每个单元,就给内存单元进行了编号,这些编号被称为该内存单元的地址。指针就是地址,指针变量存的内容就是地址。
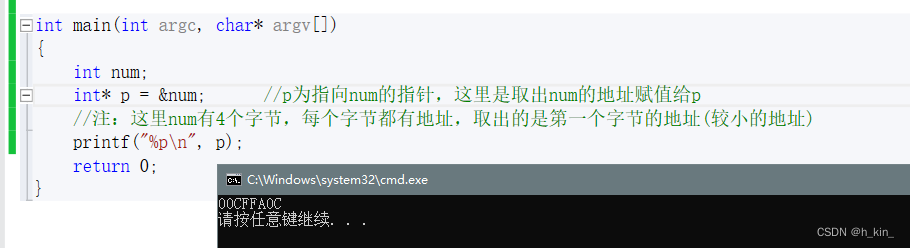
指针变量的大小
指针变量的大小取决于地址的大小。
32位平台下地址是32个bit位(即4个字节);64位平台下地址是64个bit位(即8个字节)。
6.1 指针的定义

6.2指针的解引用
* 为解引用符号,指针指向的类型决定了:
1、解引用时能取得的字节大小
2、指针在 +- 整数时,每一次移动多少个字节
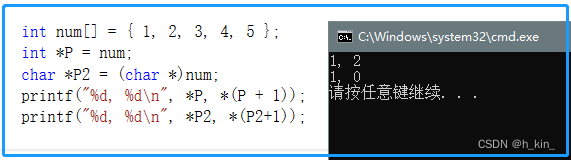
数组num 在本编译器中的存放如下
数据读取时,是由 低地址-->高地址 顺序读取

小端存储方式:数据的低字节,存在低地址中。
大端存储方式:数据的高字节,存在低地址中。
指针P指向int类型,解引用*P取到4个字节:*P 取得的是"01 00 00 00" 为num[0],即1;
*(P+1) 移动4个字节,取得的是"10 00 00 00",为num[1],即2;
指针P2指向char类型,解引用*P2取到2个字节:*P2取得的是"01 00" 即1;
*(P2+1) 移动2个字节,取得的是"00 00",即0.
6.3 野指针
成因: 1. 指针未初始化 int *p; *p = 20;
2. 指针越界访问 int num[3]; int *p = num; *(p+5) = 20;
如何规避野指针:
1 指针初始化
2 小心指针越界
3 指针指向空间释放即置NULL
4 避免返回局部变量的地址
5 指针使用之前检查有效性
6.4 指针与数组
数组名的地址和数组首元素的地址是一样的
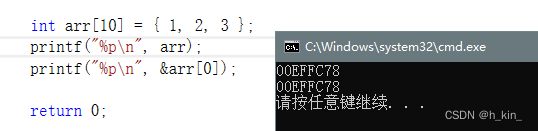
数组名表示的是数组首元素的地址,除了两种例外:
sizeof (数组名) 。表示整个数组的大小,而不是首元素的大小;
&数组名。取出的是数组全部元素的地址,指针若+ - 整数时,将会移动整个数组大小的位移。
七. 结构体
7.1 结构体的定义
struct grade //定义结构体的类型为struct grade
{
double math; //结构体的成员
double english;
} std1; //定义结构体的同时可以顺带定义变量std1
struct student
{
char name[20];//姓名
int age;//年龄
char sex[5];//性别
char id[20];//学号
struct grade;//成绩 //结构体里定义其他结构体变量
};
Typedef struct people
{
sex a;
age b;
}peo; //这里不是定义变量,而是对struct people的重命名
int main()
{
//初始化结构体类型
struct student ly = {"张三", 23, "男", "123456", {98.5, 66.0}};
peo ZS = { 1,20 }; //定义peo类型的变量ZS,并初始化
return 0;
}
匿名结构体类型
语法支持不声类型的明结构体,但也因为没有类型的声明,这种结构体只能使用一次,不能再次定义相同类型的变量。
struct
{
int a;
char b;
double c;
}x;
7.2结构体的乱序初始化
typedef struct {
int bandrate;
int databits;
int stopbits;
int parity;
int dtr;
}serial_hard_config_def;
serial_hard_config_def serial = {
.dtr = 0, //如果不按结构体顺序写,需要加上.成员才能初始化
.bandrate = 115200,
.databits = 8,
.stopbits = 1,
.parity = 0,
};7.3 结构体的访问
变量名 . 成员;
指向变量的指针 -> 成员
struct grade
{
double math;
double english;
};
struct student
{
char name[20];//姓名
int age;//年龄
char sex[5];//性别
char id[20];//学号
struct grade;//成绩
};
int main()
{
struct student ly;
ly = {"张三", 23, "男", "2117305789", {98.5, 66.0}};
ly.name = "李四";
ly.grade.math = 95;
struct student *pSTD = &ly;
pSTD->name = "王五";
pSTD->grade->math = 100;
return 0;
}
7.4 结构体的赋值
两个相同类型的结构体,可以直接赋值
typedef struct PeoInfo{
char name[20];
unsigned char age;
char tele[12];
}PeoInfo;
int main()
{
PeoInfo aa = {"张三", 20, 123321};
PeoInfo bb;
bb = aa; //相同类型的结构体可以直接赋值
}7.5 结构体传参
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
void print_1(struct S s) //结构体值传参
{
printf("%d\n", s.num);
}
void print_2(struct S* ps) //结构体地址传参
{
printf("%d\n", ps->num);
}
int main()
{
print_1(s); //传结构体
print_2(&s); //传地址
return 0; //虽然都能实现功能,但print_2的效率高很多
}7.6 结构体的大小
定义结构体时,一般按字节大到小的顺序定义结构体成员,优化结构体大小。
对齐规则:1. 第一个成员在与结构体变量偏移量为0的地址处 。2. 其他成员变量要对齐到 对齐数 的整数倍的地址处 。对齐数 = 编译器默认的一个对齐数 与 该成员字节大小的 较小值 。 VS中默认的值为83. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍 。4. 如果内部嵌套了结构体的情况, 内部嵌套的结构体对齐到自己的最大对齐数的整数倍处 ,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
练习说明:
#include<stdio.h>
typedef struct Test
{char a; //1+1
short b; //2+4
struct c
{
int x; //4+4
double y;//8
char z; //1+7
};
int d; //4+4
}Test;
-- char a的变量偏移量为0,0视为任何数的整数倍,char占1字节 //1
-- short b的变量偏移量为1,,由于规则2,short为2字节,要对到偏移量为2的位置,
所以char要补齐为1+1,占2字节。 //(1+1)+2
-- struct c内部中,int 偏移量,0,占4字节, //大小4
double为8字节,偏移量为4,由于规则2,要对到偏移量为8的位置
所以int 要补齐为4+4,占8字节 //大小(4+4)+8
char 偏移量为16,占1字节 //大小(4+4)+8+1
由于规则3,c的大小17不是8(double)的整数倍,所以补齐为24 //大小为24
//大小(4+4)+8+(1+7)=24
-- struct c的变量偏移量为5,由于规则4,成员的最大对齐数为8(double),要对到偏移量为8的
位置,所以short要补齐为2+4,占6字节 //(1+1)+(2+4)+24
-- int d的变量偏移量为32,占4字节 //(1+1)+(2+4)+24 +4=36
由于规则3, 36不是最大对齐数8(double)的整数倍,所以int d补齐为36+4 = 40,
结构体Test的大小为40字节。
----------------------------------------------------- 新增 -------------------------------------------------------
八. 补充
8.1 switch( ) case:
switch( int )
{
case 1:
//
break;
case 2:
{
//
}
break;
default:
break;
}case的作用:决定了从哪开始执行语句
(不同于 if 功能,若没有break语句,会继续往下执行,直到遇到break;)
break的作用:执行分支功能
int main()
{
int day = 1;
switch (day) {
case 1:
printf("星期一\n");
case 2:
printf("星期二\n");
case 3:
printf("星期三\n");
default:
printf("输入错误,请重新输入\n");
break;
}
return 0;
}
输出结果:星期一 星期二 星期三
因为case只决定从哪里开始执行; 没有break语句,当前case之后的其他case也会执行。8.2 逗号表达式
逗号表达式(comma expression)是 C 语言中的一种运算符,它使用逗号将两个或多个表达式连接在一起形成一个新的表达式。(本质上还是一种运算)
(expression1, expression2, ..., expressionN) // 格式
执行规则:从左至右依次执行expression, 并将最后一个expression作为逗号表达式的结果
(printf 函数里的执行顺序是:从右到左)
int main()
{
int x, y;
x = (5, 3, 9); //5,3可直接忽略,最后会将9赋给x;
y = (x++, x + 2, x * 2);
//等价于
int x, y;
x = 9;
y = (x++, x + 2, x * 2);
return 0;
//y的最后结果为20
//1.x++等价于x=x+1,所以这一步x变为10;
//2.x+2 执行结果为12,但并没有进行赋值操作,所以x还是为10;
//3.执行y=x*2;对于逗号表达式来说,只有最后一个子表达式才有赋值的操作
}8.3 引用和指针 (C语言没有引用,C++才有)
参考源链接: C语言中的引用,以及传递引用,数组传递
引用就是对某一变量起了一个新别名,对引用的操作就是对其变量的操作;
声明一个引用并不是新定义一个变量,它只是变量的一个别名,它不是一个数据类型,所以它本身不占内存,系统也不会分派内存空间。(一个引用名只能做为一个变量的引用,而数组是多个元素组成的集合,so无法建立一个数组的引用名)
引用方法: 类型标识符(变量的类型)+ & + 引用名 = 目标变量名;
int & a = b; //定义引用a,它是变量b的引用名即既是别名
“引用”与指针的区别是什么
- 引用必须被初始化,指针不必
- 引用初始化以后不能被改变,指针可以改变所指的对象
- 引用不能指向空值,而指针可以指向空值NULL
int main()
{
int a=5,b=6;
int& c=a; //定义了一个引用c
c=b;
printf("a=%d b=%d c=%d\n",a,b,c);
return 0;
} //输出:a=6 b=6 c=6void swap(int & a,int & b){ //引用作为函数的参数
int temp=a;
a=b;
b=temp;
}
int main(){
int v1=10,v2=20;
printf("v1=%d,v2=%d\n",v1,v2); //v1=10,v2=20
swap(v1,v2);
printf("v1=%d,v2=%d\n",v1,v2); //v1=20,v2=10
return 0;
}8.4 宏定义后面的 U、L、UL
| F(f) | float(浮点) |
| U(u) | unsigned int(无符号整型) |
| L (l) | signed long(符号长整型) |
| LL(ll) | signed long long(符号长长整型) |
| UL(ul) | unsigned long(无符号整型) |
| ULL(ull) | unsigned long long(无符号长长整型) |
宏定义后面的U、L、UL等符号是用来指定数据类型,没有添加则程序默认的类型是 int
- #define NUM 5 // 5是 signed int 类型
- #define NUM 5LL // 5是 signed long long 类型
假设我们有一个宏定义 #define MAX_VALUE 4294967295UL
- 在这个例子中,
4294967295UL是一个无符号长整数(unsigned long),其值为4294967295。这个值恰好是unsigned long类型可以表示的最大值。 - 如果去掉
UL后缀,只写#define MAX_VALUE 4294967295,那么4294967295就会被当作signed int类型来处理。但是,4294967295超过了signed int类型的最大值,写会导致溢出
8.5 结构体、联合体 位域的大小
博文:C语言位域大小的计算
准则:
1、同类型元素,结构体开辟的空间大小的单位 以该类型大小为单位
2、当未使用的位不够申请时,未使用的位不会被使用;而是重新开辟一个单位大小
//unsigned char类型,开辟的空间大小单位为1byte。用了3bit,结构体大小为1byte
struct BitField_1
{
unsigned char eer : 1;
unsigned char eeq : 2;
}BitField_char;
//unsigned short类型,开辟的空间大小单位为2byte,结构体大小为4byte
struct BitField_2
{
unsigned short sss : 9;
unsigned short dss : 2; //已使用11位。有5位未使用,但不够下次申请(10位)
unsigned short vss : 10; //会新开辟1单位大小(2byte)使用,上面剩下的5位不会被使用
}BitField_short;
//同理int类型,开辟的空间大小单位为4byte(32位操作系统)3、不同类型元素,结构体开辟的空间大小的单位 以类型字节最大的 为单位
//混合类型,开辟的空间大小单位为 类型中字节最大的--int(4byte),结构体大小为4byte
//跟位置无关,即使把int放前面了,结构体大小还是4byte
//若未使用的位不够下次申请,同上述 2结论, 会重新开辟1单位(4byte)空间
struct BitField_3
{
unsigned char aaa : 5;
unsigned short bb : 10;
unsigned int ccccc: 12; //使用了27位,5位未使用
}BitField_3_mix;
//问 sizeof(A) = 8
struct A
{
char t : 4;
char k : 4;
unsigned short i : 8;
unsigned long m; //偏移 2字节保证 4字节对齐
};
结构体位域大小计算原则
1、如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
2、如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
3、如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,Dev-C++采取压缩方式;
4、如果位域字段之间穿插着非位域字段,则不进行压缩;
5、整个结构体的总大小为最宽基本类型成员大小的整数倍
8.6 冒泡排序法
思路:举例 有10个数(0~9)从小到大的排序,那么进行9轮比较(自己不需要跟自己比较)
- 第一轮中把最大的数 9 移动至最右边,那么就剩下9个数需要排序了
- 第二轮剩下的9个数中,把最大的数 8 移动至最右边,那么就剩下8个数需要排序了
- 以此类推
- 如果是从大到小的排序,则把最小的数移动至最右边的思路
void Bubble_sort(uint8_t* buf, uint8_t len)
{
uint8_t i, j, tem;
for(i=0; i<len-1; i++) //len-1是因为不用与自己比较,所以比的数就少一个
{
uint8_t count = 0;
for (j=0; j<len-1-i; j++) //len-1-i是因为每一趟就会少一个数比较
{
//这是升序排法,前一个数和后一个数比较,如果前数大则与后一个数换位置
if (buf[j] > buf[j+1])
{
tem = buf[j];
buf[j] = buf[j+1];
buf[j+1] = tem;
count = 1;
}
}
if (count == 0) //如果某一趟没有交换位置,则说明已经排好序,直接退出循环
break;
}
}8.7 #if、#ifdef、#if defined( ) 的使用
单支或双支条件:
#define (DEBUF)
#ifdef DEBUG
<代码>
#endif
#ifndef DEBUG
<代码>
#endif#if 1 // 0
<代码>
#else
<代码>
#endif多支条件: 可以单个宏,也可以多个宏作条件
//单个宏
#define (SLAVE1)
#if defined (SLAVE1)
#define SN_COUNT (13)
#elif defined (SLAVE2)
#define SN_COUNT (12)
#else
#endif
---------------------------------
#if SN_COUNT==13
<代码>
#elif SN_COUNT==12
<代码>
#endif//多个宏
#if defined(SLAVE1) || (!defined(SLAVE2)) || (!defined(SLAVE3))
<代码>
#elif defined(MACRO_1) && defined(MACRO_2)
<代码>
#else SN_COUNT==13
<代码>
#endif----------------------------------------------------- 结束分割线 ------------------------------------------------------















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









