







文章目录
鲸鱼数据
https://www.kaggle.com/mmm4a1/seresnext101-pytorch-starter/edit
利用train.csv对其不同类别的图像数量进行可视化。
首先读取一下
train_df = pd.read_csv('../input/train.csv')
看一下数据的样子,我们要用到Id这一列。
train_df.head()
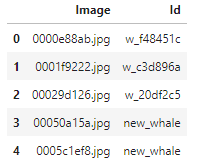
看一下一共有多少种鲸鱼图像?
NCLASSES = len(train_df['Id'].unique())
print(NCLASSES)
5005
然后使用函数统计一下,这个返回值是series类型也可以和列表一样切片。
train_df['Id'].value_counts()[:10]
new_whale 9664
w_23a388d 73
w_9b5109b 65
w_9c506f6 62
w_0369a5c 61
w_700ebb4 57
w_3de579a 54
w_564a34b 51
w_fd3e556 50
w_88e4537 49
Name: Id, dtype: int64
直接plot即可
train_df['Id'].value_counts()[1:15].plot(kind = 'bar')

可视化chest-xray
如果没有csv文件怎么办?
首先看一下目录结构

normal,pneumonia中各存了照片。我们可视化一下两个文件夹中的图像数量的柱状图。
path = '../input/chest-xray-pneumonia/chest_xray/chest_xray'
train_samplesize = pd.DataFrame.from_dict(
{'Normal': [len([os.path.join(path+'/train/NORMAL', filename)
for filename in os.listdir(path+'/train/NORMAL')])],
'Pneumonia': [len([os.path.join(path+'/train/PNEUMONIA', filename)
for filename in os.listdir(path+'/train/PNEUMONIA')])]})
import seaborn as sns
sns.barplot(data=train_samplesize).set_title('Training Set Data Inbalance', fontsize=20)
plt.show()
这样写更方便
path = '../input/chest-xray-pneumonia/chest_xray/chest_xray'
train_samplesize = pd.DataFrame.from_dict(
{'Normal': [len(os.listdir(path+'/train/NORMAL'))],
'Pneumonia': [len(os.listdir(path+'/train/PNEUMONIA'))]})
import seaborn as sns
sns.barplot(data=train_samplesize).set_title('Training Set Data Inbalance', fontsize=20)
plt.show()

结果是一样滴
















 3328
3328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









