










创建时间:2024-12-22
首发时间:2025-01-24
最后编辑时间:2024-01-24
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名高一学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
上一篇我们讲完了马尔可夫随机场 MRF,那篇的最后我简单介绍了条件随机场 CRF 但没有展开讲。这不,这篇就来填坑啦!!
这篇的主角是条件随机场 CRF,这东西简直太有趣了,和我们之前讲的 HMM 和 MRF 都有很大的关系,且听我细细展开整个逻辑线…
嗷不过,在看这篇文章之前,你需要对马尔可夫随机场 MRF 有一个基本的了解,可以去看我上一篇文章:
【高中生讲机器学习】29. 马尔可夫随机场 2w 字详解!超!系!统!
start!
标注问题简介
okay,因为 CRF 和这篇文章后面会提到的另外两个模型都是用于标注问题的模型,所以或许我们需要先介绍一下标注问题。
我忘了我在前面 HMM 那篇里说没说过了,标注问题是对分类问题的一种扩展。
分类算法是怎么工作的呢,接收一个输入,给出一个类别标签,对吧。分类算法可以很好地解决单个输入的问题,但如果有些时候,我的输入不是一个,而是一串,或者说一个序列,那怎么办?
你可能马上就想到,那就对这个序列的每个位置都做分类是不是就可以了。或者说,接收一个序列作为输入,并给这中的每个位置一个类别标签。
是的没错!标注问题就是这么工作的,所以它可以看作分类问题在序列上的扩展。
well,不过,扩展到序列上之后,我们要考虑的事情就更多了。
考虑一个最简单的情况。在基础的分类问题里,因为输入只有一个,所以输出(标签)显然只和这一个输入有关。however,在序列当中,某个位置的标签只和这个位置对应的输入有关吗?它会不会和前一个标签也有关?
for eg,我们有一个词性标注的任务,现在要标注一个词 thread。这个词有名词和动词两种词性。所以,如果我们仅仅通过输入这个词来判断它的词性,就会产生一些 confusion。这就在提醒我们,是不是还需要考虑除了输入本身以外的,更多的依赖关系?
(o 另外,你可以回想一下你看到 thread 之后第一反应认为它是什么意思,据说咱们这些搞 CS 的第一反应都是线程((
可以说对依赖关系的建模是标注问题的核心吧。具体来说,对于各种标注问题算法,有两件事是我们需要关注的:
- 我们要建模哪些依赖关系?
- 我们通过什么样的模型结构去建模这些依赖关系?
后面我们会见到三个用于标注问题的模型,包括我们这篇的主角 CRF。每个模型对于这两个问题的回答都不同。
好啦,标注问题我们就说到这,知道 CRF 要干什么之后,我们可以来系统地介绍一下 CRF 了嘿嘿嘿。
条件随机场概述
okay,我们先来简单地介绍一下条件随机场。
(提前 note:这一部分的数学公式或许会让你感到 “莫名其妙”,不过没关系,我们会在后面的部分解释它们是怎么来的~
条件随机场,英文全称 conditional random field,简写为 CRF,广泛地用于各种标注问题中,比如命名实体识别、词性(POS)标注等等。
CRF 可以有各种形状,就像 MRF 和 BN 那样。不过因为主要用在标注问题中,所以通常就是一个输入序列对应一个输出序列,相当于一一对应的两条线,没有更复杂的图结构。
这种一个输入序列对应到一个等长的输出序列的 CRF 被称为线性链 CRF,是 CRF 中图结构最简单但使用范围最广泛的,或者说其实我们遇到的绝大多数 CRF 都是线性链 CRF。
这有可能因为,本身 CRF 就是为了改进别的标注算法才出现的,然后标注问题几乎都是这种一个输入序列对应一个输出序列的形式,所以其实 CRF 本来就该长成线性链 CRF 那样。
哦说远了,相关的内容在后面会专门有一个 part 来讲!
在后面的内容中,我们讨论的对象都是线性链 CRF。
下面是线性链 CRF 的结构图:
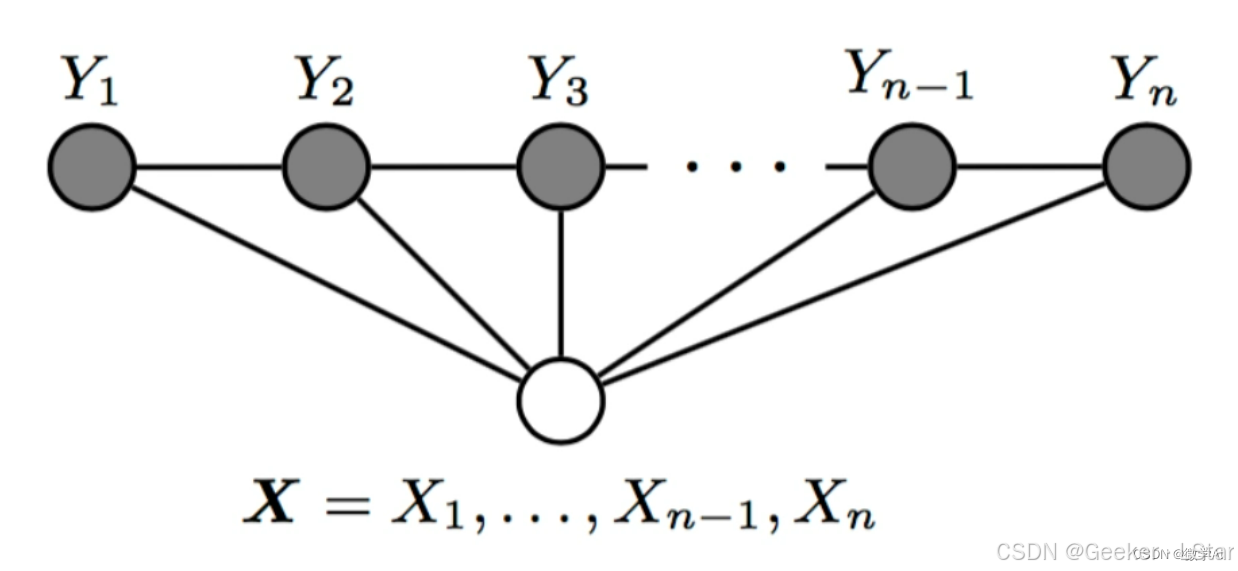
其中 X = { x 1 , x 2 , . . . , x n } X = \{x_1, x_2, ..., x_n\} X={x1,x2,...,xn} 是输入数据, y 1 , y 2 y_1, y_2 y1,y2 这些是各自位置的 x x x 对应的输出。
这个结构图中有两个关键。
第一,CRF 和 MRF 一样是无向图(我们可以看到图中的边都没有箭头),或者说 CRF 和 MRF 遵循一样的概率分解性质。
第二,CRF 是判别模型,即给定输入
X
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
X=\{x_1, x_2, ..., x_n\}
X={x1,x2,...,xn} 之后,计算条件概率
(
Y
∣
X
)
(Y|X)
(Y∣X),并输出条件概率最大的
Y
Y
Y。
记住这两点哦,后面我们会从这两点出发给出 CRF 的公式。
豪德,现在我们知道了 CRF 是判别模型,我们要做的事就简单了。
——找到 CRF 计算条件概率的公式。
嗯,因为这个部分只是一个概述,so 我不会在这里讲这些公式具体的推导过程。我会先给出计算公式,然后在后面的 part 中详细地这些公式是怎么来的 or 为什么它们有道理。
首先,我们先给出计算 CRF 中 “每一个部分” 的条件概率的公式:
ψ
(
y
i
−
1
,
y
i
,
i
)
=
exp
(
∑
k
=
1
d
1
λ
k
t
k
(
y
i
−
1
,
y
i
,
X
,
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
,
X
,
i
)
)
\psi\left(y_{i-1}, y_{i}, i\right)=\exp \left(\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i-1}, y_{i}, X, i\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}, X, i\right)\right)
ψ(yi−1,yi,i)=exp(k=1∑d1λktk(yi−1,yi,X,i)+k=1∑d2μksk(yi,X,i))
(如果你看过 MRF 那篇,你可能会发现诶这好像有点类似于 MRF 中所说的极大团的概率计算式,其实是这样的,不过这里我们先不展开。
(btw!!! 如果你没看过 MRF 那篇,一定要先去看看呀,否则后面会遇到障碍的 emm.
然后,如何计算整个线性链 CRF 的条件概率呢,我们只需要把在所有 “部分” 上的条件概率乘起来,再除以归一化因子,就可以啦~(对,也是沿用 MRF 的哈哈哈哈哈(
最终计算整体条件概率的公式如下:
P
(
Y
∣
X
)
=
1
Z
(
X
)
exp
(
∑
t
=
1
T
∑
k
d
1
λ
k
f
k
(
y
t
,
y
t
−
1
,
X
)
+
∑
t
=
1
T
∑
k
d
2
γ
k
g
k
(
y
t
,
X
)
)
P(Y \mid X)=\frac{1}{Z(X)} \exp \left(\sum_{t=1}^{T} \sum_{k}^{d_1} \lambda_{k} f_{k}\left(y_{t}, y_{t-1}, X\right)+\sum_{t=1}^{T} \sum_{k}^{d_2} \gamma_{k} g_{k}\left(y_{t}, X\right)\right)
P(Y∣X)=Z(X)1exp(t=1∑Tk∑d1λkfk(yt,yt−1,X)+t=1∑Tk∑d2γkgk(yt,X))
Z
(
X
)
Z(X)
Z(X) 为配分函数,表达式为:
Z
(
X
)
=
∑
i
=
1
N
exp
(
∑
t
=
1
T
∑
k
d
1
λ
k
f
k
(
y
t
(
i
)
,
y
t
−
1
(
i
)
,
X
(
i
)
)
+
∑
t
=
1
T
∑
k
d
2
γ
k
g
k
(
y
t
(
i
)
,
X
(
i
)
)
)
Z(X) =\sum_{i=1}^N\exp \left(\sum_{t=1}^{T} \sum_{k}^{d_1} \lambda_{k} f_{k}\left(y_{t}^{(i)}, y_{t-1}^{(i)}, X^{(i)}\right)+\sum_{t=1}^{T} \sum_{k}^{d_2} \gamma_{k} g_{k}\left(y_{t}^{(i)}, X^{(i)}\right)\right)
Z(X)=i=1∑Nexp(t=1∑Tk∑d1λkfk(yt(i),yt−1(i),X(i))+t=1∑Tk∑d2γkgk(yt(i),X(i)))
其中 f k f_k fk 和 g k g_k gk 为特征函数, λ k \lambda_k λk 和 γ k \gamma_k γk 对应特征函数的权重值, N N N 为所有可能的输出序列 Y Y Y 的数量。线性链条件随机场完全由特征函数和对应的权值确定。
如果你看了 MRF,你可能发现了,这 CRF 的概率计算公式和 MRF 简直也太像了吧!除了 MRF 建模的是
P
(
X
)
P(X)
P(X),CRF 建模的是
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) 之外。
哈哈哈哈哈的确是这样的!!
okay,现在我们大致了解了 CRF 是什么 & 它怎么算,接下来我们有必要理解一下,诶,为什么 CRF 的公式长成这个样子?或者说,CRF 是怎么出现的?
嗯,我觉得有两条路可以用于理解这个事情。从概率无向图模型的原身 MRF 出发,或从标注问题的经典算法 HMM 出发。
后面你会发现,CRF 可以看作 MRF 在标注问题(条件概率)上的应用,也可以看作 HMM 的二阶改进版。
okiiii 那我们先从 MRF 说起吧!
从 MRF 到 CRF
oki,首先我们来看理解 CRF 的一种方式——从马尔可夫随机场 MRF 出发。
(嗷在看这部分以前一定要先对 MRF 有一个了解o!!! 比如从这里~
其实我觉得从 MRF 出发理解 CRF,主要是从无向图的因子分解角度来说的。CRF 除了把 MRF 中的联合概率改成了条件概率之外,别的地方和 MRF 简直是一模一样的,尤其是它的能量函数(也就是最核心的部分),完全就是从 MRF 继承来的。
well,首先我们先来看看 CRF 和 MRF 的区别,这有助于我们理解 CRF 在 MRF 的基础上做了哪些修改。
前面说了,CRF 是判别模型,建模的是条件概率,即在输入一个序列
X
X
X 的时候,输出另一个序列
Y
Y
Y 的概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X);而 MRF 是生成模型,建模的是联合概率,即图中所有
y
i
y_i
yi 共同出现的概率
P
(
Y
)
P(Y)
P(Y)(注意,没有
X
X
X)。
嗯其实区别就在这里。
回忆一下上面给出的那张 CRF 结构图。我们可以先忽略图中的
X
X
X,然后思考一下我们应该如何计算
Y
Y
Y 的联合概率(这个时候
Y
Y
Y 就和
X
X
X 没有关系了哦,我们关注的是
Y
Y
Y 自身或者说内部的情况)。
这就来到 MRF 的领地了哈哈哈。
嗯,按照上一篇讲的 MRF,这个时候应该怎么建模联合概率呢?
obviously,使用极大团,对吧。
对于上面的图,如果我们把
X
X
X 去掉,那么剩下的就是一串连在一起的
Y
Y
Y,这个时候极大团很好找,就是相邻的两个
y
y
y,即每个
y
i
y_i
yi 和
y
i
−
1
y_{i-1}
yi−1 都构成一个极大团(
i
∈
[
1
,
T
]
i \in [1, T]
i∈[1,T],
T
T
T 为输入序列长度)。
嗯不过
y
i
,
y
i
−
1
y_i, y_{i-1}
yi,yi−1 之类的是从 CRF(序列标注)的视角出发说的,在 MRF 中没有顺序这一说,极大团中的节点是相互对称的关系。so 我们用没有顺序意味的
y
i
,
y
j
y_i, y_j
yi,yj 代替原来的
y
i
,
y
i
−
1
y_i, y_{i-1}
yi,yi−1。
嗯,然后按照我们上一篇讲的,每个极大团上的势函数分为两个部分——反映自身稳定性的部分和反映相互作用稳定性的部分。
对于这个例子中的极大团(
y
i
,
y
j
y_i, y_j
yi,yj),反映相互作用稳定性的部分可以构建为:
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
j
)
\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_i, y_j\right)
k=1∑d1λktk(yi,yj)
其实就是 MRF 那里的公式啦~ 只不过因为我们知道每个极大团里就两个元素,所以省去了
∑
y
i
,
y
j
∈
C
\sum_{y_i, y_j \in \mathcal{C}}
∑yi,yj∈C.
(well 如果你不理解这个公式,please 去看上一篇!!
嗯,然后是反映内部每个节点自身稳定性的部分,按理来说应该是:
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
j
)
\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{j}\right)
k=1∑d2μksk(yi)+k=1∑d2μksk(yj)
emm 但是稍等一下,这个时候就涉及到之前被我们暂时忽略的顺序问题了。
y
i
y_i
yi 和
y
j
y_j
yj,前面说了,这里是 generally 代替
y
i
y_i
yi 和
y
i
−
1
y_{i-1}
yi−1 的,但是 err 在考虑节点自身稳定性的时候,我们还是得重新 “记起” 顺序这个问题.
在考虑顺序问题的情况下,自身稳定性部分就可以重新写成:
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
j
)
=
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
−
1
)
\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{j}\right)=\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i-1}\right)
k=1∑d2μksk(yi)+k=1∑d2μksk(yj)=k=1∑d2μksk(yi)+k=1∑d2μksk(yi−1)
嗯,但是我们接着思考一个问题——在这个极大团中的
y
i
−
1
y_{i-1}
yi−1,其实也就是在下一个相邻极大团中的
y
i
y_i
yi 呀,所以我们目前的算法其实会把同一个值计算两遍。
(对于最前面一个节点和最后面一个节点,我们会分别做首尾填充,so 也是计算了两遍。
但是,既然是相同的值,我们其实完全没必要重复计算两遍诶。
呃怎么说呢,就是,如果就用
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
j
)
\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{j}\right)
∑k=1d2μksk(yi)+∑k=1d2μksk(yj) 其实也问题不大,但是何必多算一次捏~
所以,我们就简化一下,在每个位置,衡量自身稳定性的项就用 ∑ k = 1 d 2 μ k s k ( y i ) \sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right) ∑k=1d2μksk(yi) 就好啦~
okay 呀!这样的话,每个极大团上的势函数的形式就出来了:
ψ
(
y
i
,
y
j
)
=
exp
(
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
j
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
=
exp
(
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
\psi\left(y_i, y_j\right)=\exp \left(\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_i, y_j\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right) \\ =\exp \left(\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_i, y_{i-1}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right)
ψ(yi,yj)=exp(k=1∑d1λktk(yi,yj)+k=1∑d2μksk(yi))=exp(k=1∑d1λktk(yi,yi−1)+k=1∑d2μksk(yi))
好诶!现在我们得到了,在忽略
X
X
X,把
Y
Y
Y 看作 MRF 的情况下,每个极大团上的势函数的形式。
嗯,然后按照 MRF 的计算方式,整个 MRF 的联合概率等于每个极大团上的势函数的乘积再除以规范化因子,即:
P
(
Y
)
=
1
Z
∏
i
=
1
T
exp
(
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
P(Y)=\frac{1}{Z} \prod_{i=1}^{T} \exp \left(\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right)
P(Y)=Z1i=1∏Texp(k=1∑d1λktk(yi,yi−1)+k=1∑d2μksk(yi))
其中
Z
Z
Z 为配分函数:
Z
=
∑
y
exp
(
∑
i
=
1
T
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
)
+
∑
i
=
1
T
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
Z=\sum_{y} \exp \left(\sum_{i=1}^{T} \sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}\right)+\sum_{i=1}^{T} \sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right)
Z=y∑exp(i=1∑Tk=1∑d1λktk(yi,yi−1)+i=1∑Tk=1∑d2μksk(yi))
呃豪德,然后虽然我现在很头大但是我们还是把这个
Z
Z
Z 带回去,然后得到了最终
P
(
Y
)
P(Y)
P(Y) 的表达式:
P
(
Y
)
=
exp
(
∑
i
=
1
T
−
1
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
)
+
∑
i
=
1
T
−
1
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
∑
y
exp
(
∑
i
=
1
T
−
1
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
)
+
∑
i
=
1
T
−
1
∑
k
=
1
d
2
μ
k
s
k
(
y
i
)
)
P(Y)=\frac{\exp \left(\sum_{i=1}^{T-1} \sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}\right)+\sum_{i=1}^{T-1} \sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right)}{\sum_{y} \exp \left(\sum_{i=1}^{T-1} \sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}\right)+\sum_{i=1}^{T-1} \sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}\right)\right)}
P(Y)=∑yexp(∑i=1T−1∑k=1d1λktk(yi,yi−1)+∑i=1T−1∑k=1d2μksk(yi))exp(∑i=1T−1∑k=1d1λktk(yi,yi−1)+∑i=1T−1∑k=1d2μksk(yi))
(注意注意,你现在可能感觉非常头大,这个过程的详细解释在 MRF 那篇!!
okay 呀,现在我们来考虑拓展到 CRF 的情况。或者说考虑 CRF 比 MRF 多了什么。
其实比较好想。在 CRF 的情况中我们只是多了一个
X
X
X(输入序列),so 我们只需要在极大团的公式中加上
X
X
X,修改后的极大团概率(条件概率)为:
ψ
(
y
i
,
y
i
−
1
,
i
)
=
exp
(
∑
k
=
1
d
1
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
+
∑
k
=
1
d
2
μ
k
s
k
(
y
i
,
X
,
i
)
)
\psi\left(y_{i}, y_{i-1}, i\right)=\exp \left(\sum_{k=1}^{d_{1}} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)+\sum_{k=1}^{d_{2}} \mu_{k} s_{k}\left(y_{i}, X, i\right)\right)
ψ(yi,yi−1,i)=exp(k=1∑d1λktk(yi,yi−1,X,i)+k=1∑d2μksk(yi,X,i))
真的就是多了个 X X X 和代表位置的 i i i(因为 CRF 是有顺序的),别的什么也没有。
well,为了后面看着简单,其实这个表达式还可以继续简化:
ψ
(
y
i
,
y
i
−
1
,
i
)
=
exp
(
∑
k
=
1
d
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
)
\psi\left(y_{i}, y_{i-1}, i\right)=\exp \left(\sum_{k=1}^{d} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)\right)
ψ(yi,yi−1,i)=exp(k=1∑dλktk(yi,yi−1,X,i))
ee 你可能好奇这个是怎么来的,其实很简单啦,我们只需要把多出项设置为 0 就可以了。
比如说,我们原来有 3 个 衡量相互作用稳定性的特征函数
t
k
t_k
tk 和 4 个衡量自身稳定性的特征函数
s
k
s_k
sk,那么我们就可以把前三个
t
k
t_k
tk 和前三个
s
k
s_k
sk 统一为:
∑
k
=
1
3
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
=
∑
k
=
1
3
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
+
∑
k
=
1
3
μ
k
s
k
(
y
i
,
X
,
i
)
\sum_{k=1}^{3} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)=\sum_{k=1}^{3} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)+\sum_{k=1}^{3} \mu_{k} s_{k}\left(y_{i}, X, i\right)
k=1∑3λktk(yi,yi−1,X,i)=k=1∑3λktk(yi,yi−1,X,i)+k=1∑3μksk(yi,X,i)
然后最后一个
s
k
s_k
sk 可以写为:
λ
4
t
4
(
y
i
,
y
i
−
1
,
X
,
i
)
=
0
+
μ
4
s
4
(
y
i
,
X
,
i
)
\lambda_{4} t_{4}\left(y_{i}, y_{i-1}, X, i\right)=0+ \mu_{4} s_{4}\left(y_{i}, X, i\right)
λ4t4(yi,yi−1,X,i)=0+μ4s4(yi,X,i)
嗯~然后把每一个
λ
i
t
i
\lambda_i t_i
λiti 加起来,就得到我们刚才说的:
ψ
(
y
i
,
y
i
−
1
,
i
)
=
exp
(
∑
k
=
1
d
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
)
\psi\left(y_{i}, y_{i-1}, i\right)=\exp \left(\sum_{k=1}^{d} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)\right)
ψ(yi,yi−1,i)=exp(k=1∑dλktk(yi,yi−1,X,i))
当原始的 t k t_k tk 数量多余 s k s_k sk 数量的时候也是一样的,只不过是把用作补充的 s k s_k sk 恒设为 0.
嗯,然后我们执行和 MRF 一样的操作,把所有极大团的条件概率相乘,就得到了整个 CRF 的条件概率:
P
(
Y
∣
X
)
=
1
Z
(
X
)
exp
(
∑
i
=
1
T
−
1
∑
k
=
1
d
λ
k
t
k
(
y
i
,
y
i
−
1
,
X
,
i
)
)
P(Y \mid X)=\frac{1}{Z(X)} \exp \left(\sum_{i=1}^{T-1} \sum_{k=1}^{d} \lambda_{k} t_{k}\left(y_{i}, y_{i-1}, X, i\right)\right)
P(Y∣X)=Z(X)1exp(i=1∑T−1k=1∑dλktk(yi,yi−1,X,i))
Z ( X ) Z(X) Z(X) 是配分函数,就不展开了。
hey!!
我们得到了 CRF 条件概率的计算公式!!这太棒了!
嗷,这里再重申一下重点。我们可以把 CRF 看成加上了输入的 MRF,或者说,CRF 研究的是在给定输入的情况下,输出的 MRF(后面这句话理解起来有点绕,如果你不懂,just ignore it~)。
所以,从 MRF 出发推导 CRF,我们做的所有工作只是在 MRF 的极大团中加入了输入序列
X
X
X,然后把原来的联合概率变成了条件概率而已。
哈哈哈哈这么一说是不是感觉相当简单~
嗯但是你可能也有点疑惑,,
bruh,现在公式是推出来了,但是这背后好像没有什么特别的 “motivation”?或者说,这好像就是为了拓展而拓展,但是缺少一个 “这么拓展的原因”。
well…怎么说,我也这么觉得()。In my perspective,其实从 MRF 出发理解 CRF 并不是最好的一条路,更好的理解方式应该是从标注问题出发,把尝试解决标注问题的各种模型拉出一条线,看看后一个模型是如何改进前一个模型的,这样才能更好地理解为什么 CRF 的公式长成这个样子!!
嗷,那既然要追根溯源,大概率是从 HMM 出发了。
那么,接下来我们就来看一看,如何从 HMM 出发,一步步得到 CRF!
从 HMM 到 CRF
嗯!说完从 MRF 理解 CRF 的角度,我们来看一条我个人认为更合理的思路——从 HMM 出发,经过 MEMM,最终理解 CRF。
我觉得这条线是非常能说明 “为什么 CRF 会出现” 的。或者说,这条线相比 MRF 那条线能够更充分地展示 CRF 背后的 motivation。
因为这条线上的三个模型都是标注问题的模型,所以我们再放一遍标注问题中需要重点考虑的两个问题:
- 我们需要建模哪些依赖关系?
- 我们通过什么样的模型结构去建模这些依赖关系?
下面的三个模型对于这两个问题给出了不同的回答,它们是层层递进的,每个模型都在前一个模型的基础上做出了一些改进。
oki! 那么我们接下来就来分别看看它们吧…!!
隐马尔可夫模型 HMM
我们从隐马尔可夫模型 HMM 开始。
其实 HMM 我在之前的文章中有讲过,甚至有上下两篇。如果你希望系统地了解一下 HMM,可以先去看这两篇文章:
【高中生讲机器学习】20. 隐马尔可夫模型好难?看过来!(上篇)
【高中生讲机器学习】21. 隐马尔可夫模型好难?看过来!(下篇)
不过其实不看也没太大问题啦,我会在这里简单介绍一下它。
HMM 可以说是标注问题三大模型的起点,它是贝叶斯网络的一个特例。
HMM 是生成模型,使用有向图结构。HMM 中有两个重要的概念——状态和观测,状态是隐藏的,观测不是。HMM 认为每一个观测都是从对应位置的状态中生成的,每一个位置的状态依赖于前一个位置的状态,而每一个位置的观测依赖于当前位置的状态。
下图是一个标准的 HMM,其中标出了状态序列和观测序列。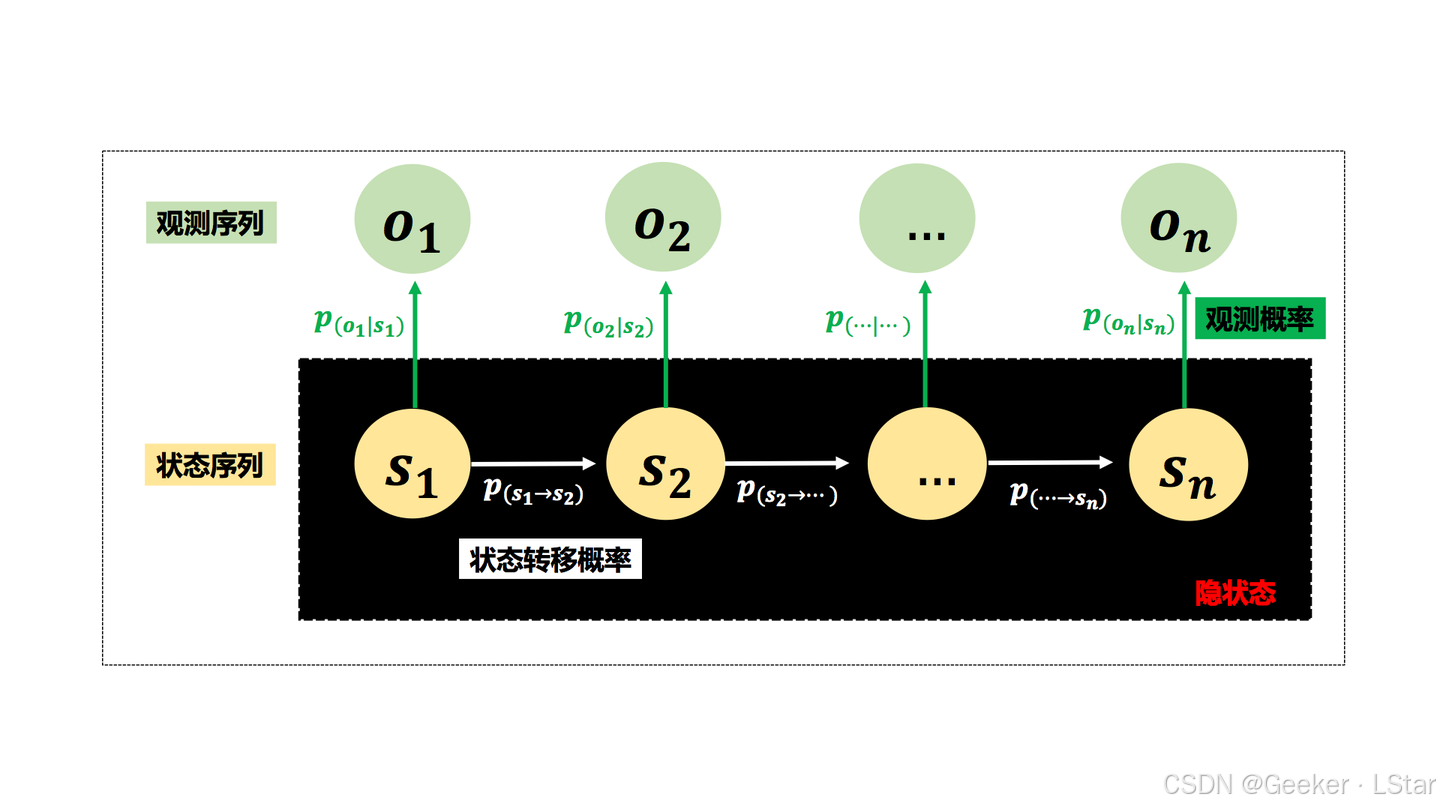
比如说,如果用 HMM 来做词性标注问题,那么词性就是状态,词语就是观测。HMM 认为每个词语都是从对应的词性当中 “生成” 的。at the same time,某个位置的词性(状态)仅依赖于前一个位置的词性(状态),而每个位置的词语(观测)仅依赖于当前位置的词性(观测)。
嗯,上面的内容可以概括为 HMM 的两大假设——观测独立性假设和局部依赖性假设,这两个假设是 HMM 的核心。如果你看过 HMM 那篇的话,这两个词应该不陌生。
观测独立性假设是指,当前位置的观测仅与当前位置的状态有关;或者说,在给定当前位置的状态的情况下,当前位置的观测与图中的其它所有观测 / 状态无关。
局部独立性假设是指,每一个位置的状态都只与上一个位置的状态有关,或者说这种依赖关系可以被看作一个一阶马尔可夫过程。
well,如果你觉得干巴巴的状态 / 观测不好理解,你可以尝试带入到我们上面说的词性标注任务的情景当中。
但是,emm,在实际场景中,序列中间的依赖关系远比 HMM 的这两个假设复杂,跨位置的依赖关系很有可能存在。对于实际问题来说,HMM 这种建模方案太简单了。
自然地,对 HMM 的 “一阶” 改进方案出现了,也就是我们马上要讲到的 MEMM!!
最大熵马尔可夫模型 MEMM
嗷,从上面顺下来,关于 MEMM 对 HMM 的改善,我们可以提前概括一下。
MEMM 相比于 HMM 最大的改进就是它推翻了 HMM 的观测独立性假设。MEMM 认为,当前位置的观测不只和当前位置的状态有关,还和前一个位置的观测有关。同时,在 MEMM 中,当前位置的观测,无论是和当前位置的状态还是和前一个位置的观测,之间的关系都不是单一的,都需要从多个角度去提取和建模。这个内容后面还会说到,这里暂时不展开。
哦!不过这里有一个需要注意的点(or you may be confused),还是拿词性标注的问题作例子吧。在 HMM 中,状态是指词性,观测是指词语;但到了 MEMM 中,状态是指词语,观测是指词性。它们两个是反过来的,这本质上是生成模型和判别模型的区别,我们后面还会再提到。(这个一定要记住o!!
咳咳咳说了这么多好像还没系统地介绍一下 MEMM。。
MEMM,中文是最大熵马尔可夫模型,是一种判别模型(和 HMM 不一样),图结构为有向图。
well,“…马尔可夫模型”,听着好像和马尔可夫随机场有点关系。但其实它的图结构和 HMM 一样依然是有向图,这也就决定了它的概率分解方式和贝叶斯网络(而不是马尔可夫网络)一致。
下图是一个 MEMM,注意下面的 x x x 对应 HMM 中的状态,上面的 y y y 对应 HMM 中的观测。MEMM 的状态和观测和 HMM 是反着的,一定要记住呀。
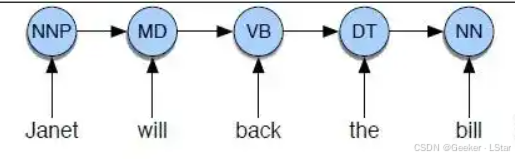
(bushi,MEMM 这么不受待见的吗,怎么感觉网上关于 MEMM 的图都比 HMM 少好多,,
okay,那么我们来看一看在 MEMM 中,每个位置的观测都和什么有关。(aaa 注意哦观测是上面的 y y y,也就是输出的标签序列。
em,这是不是很容易看出来。(除了第一个位置之外)每个位置的观测都被两个箭头指向,一个 from 当前位置的状态,另一个 from 前一个位置的观测。
诶,这说明什么!
说明在 MEMM 中,每个位置的观测都同时受到当前位置的状态和前一个位置的观测的影响,也就是说,MEMM 推翻了 HMM 的观测独立性假设!
(回忆一下,HMM 的观测独立性假设是指,每个位置的观测只和当前位置的状态有关,即在给定当前位置的状态的条件下,当前位置的观测与其它所有节点条件独立。
我的天呐,世界线收束了,MEMM 中的情况不就是我们在贝叶斯网络那篇中讲的,子节点被观测到时,它的各个父节点之间非条件独立嘛!(niiiiice((( 啊这也再次佐证了 MEMM 虽然名字里有马尔可夫,但是它的概率计算方式符合贝叶斯网络。
okay!现在 HMM 中的两大(十分局限的)假设已经被我们解决掉一个了,MEMM 推翻了 HMM 的条件独立性假设,认为当前的观测不仅取决于当前的状态,还取决于前一个位置的观测。这个改进使得 MEMM 相比 HMM 能够捕捉更多的依赖关系,于是乎有了更强的 performance blabla…(套话开始啊不是,,
嗯…但你有没有好奇,bruh,既然这么看着 MEMM 和马尔可夫网络一点关系也没有,那它为什么还叫最大熵马尔可夫模型。。?
okay this is gooooood question。但是谁说这里的 “马尔可夫” 一定就是马尔可夫随机场呀?in fact,这里的 “马尔可夫” 实际上是指局部马尔可夫性,或者说局部依赖性假设!
啊对,就是 HMM 同款的局部依赖性假设。即那个一阶依赖关系。在 MEMM 中可以表述为:当前位置的观测仅和当前位置的状态及前一个位置的观测有关,而和其它(距离更远的)节点无关。
e,这可以看做什么呢,就是,MEMM 和 HMM 都遵循局部依赖性假设,即依赖链的长度为 1;MEMM 在 HMM 的基础上添加了一个依赖节点,但是依然没有改变依赖链长度为 1,或者说局部依赖这件事情。
简单概括一下,MEMM 推翻了 HMM 的观测独立性假设,但是它沿用了 HMM 的局部依赖性假设,也叫齐次马尔可夫性。
嗯哼…我觉得现在你应该理解 MEMM 出现的 motivation 以及它对 HMM 的改进啦!but 说到现在为止我们还没有讲到公式,so 是时候来一点公式了!
我们说了,MEMM 认为每个观测都只依赖于当前状态及前一个位置的观测,这用公式表示就是:
P
(
y
t
∣
x
t
,
y
t
−
1
)
P(y_t | x_t, y_{t-1})
P(yt∣xt,yt−1)
嗯,然后,和 HMM 类似,整个输出序列的概率就是每一个位置的观测的条件概率相乘,即:
P
(
Y
∣
X
)
=
∏
t
=
1
T
P
(
y
t
∣
y
t
−
1
,
x
t
)
P(Y \mid X)=\prod_{t=1}^{T} P\left(y_{t} \mid y_{t-1}, x_{t}\right)
P(Y∣X)=t=1∏TP(yt∣yt−1,xt)
okay,接下来是一个重点部分:每个位置的
P
(
y
t
∣
x
t
,
y
t
−
1
)
P(y_t | x_t, y_{t-1})
P(yt∣xt,yt−1) 具体怎么计算?
嗯,MEMM 采用了一种很有趣而有用的方法——定义多个特征函数,每个特征函数有不同的权重,把这些特征函数加权组合就得到了这个位置的
P
(
y
t
∣
x
t
,
y
t
−
1
)
P(y_t | x_t, y_{t-1})
P(yt∣xt,yt−1).
这个方法是有深意的,不过我们后面再说,先上公式!:
P
(
y
t
∣
x
t
,
y
t
−
1
)
=
exp
(
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
P(y_t | x_t, y_{t-1})=\exp \left(\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)
P(yt∣xt,yt−1)=exp(k∑λkfk(yt−1,yt,xt,t))
这个式子中, f k f_k fk 代表特征函数, λ k \lambda_k λk 代表特征函数的权重,MEMM 由特征函数和其权重完全确定(对和 CRF 一样嘿嘿)。
在 MEMM 中,每一步都选择使得当前条件概率
P
(
y
t
∣
x
t
,
y
t
−
1
)
P(y_t | x_t, y_{t-1})
P(yt∣xt,yt−1) 最大的
y
t
y_t
yt。
well,你可能感觉上面的式子少了些什么,其实是我们没有进行归一化…
Z
(
x
t
)
=
∏
i
=
1
N
P
(
y
t
∣
x
t
,
y
t
−
1
)
=
∏
i
=
1
N
exp
(
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
=
exp
(
∑
i
=
1
N
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
Z(x_t)=\prod _{i=1}^N P(y_t | x_t, y_{t-1})=\prod _{i=1}^N \exp \left(\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right) \\ =\exp \left(\sum_{i=1}^N\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)
Z(xt)=i=1∏NP(yt∣xt,yt−1)=i=1∏Nexp(k∑λkfk(yt−1,yt,xt,t))=exp(i=1∑Nk∑λkfk(yt−1,yt,xt,t))
其中
N
N
N 代表这个位置可供选择的
y
t
y_t
yt 一共有
N
N
N 个。
然后,我们把归一化加上,最终得到的就是在每一个位置选择
y
t
y_t
yt 的公式啦!!
P ( y t ∣ x t , y t − 1 ) = exp ( ∑ k λ k f k ( y t − 1 , y t , x t , t ) ) exp ( ∑ i = 1 N ∑ k λ k f k ( y t − 1 , y t , x t , t ) ) P(y_t | x_t, y_{t-1})=\frac {\exp \left(\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)} {\exp \left(\sum_{i=1}^N\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)} P(yt∣xt,yt−1)=exp(∑i=1N∑kλkfk(yt−1,yt,xt,t))exp(∑kλkfk(yt−1,yt,xt,t))
嗯!!以上就是 MEMM 在每个步骤选择预测 y t y_t yt 的公式!!
嗷,可能你会感觉到,本质上就是人类首先设定好了很多特征(yep 就是特征工程),然后让模型去学习这些特征的权重。
其实它是相当于,人首先设定好一些可能的特征,然后让模型自己去判断这些特征对于预测输出序列是否有用。如果有用,那么最终特征函数的权重就会很大,反之就会很小。而如果特征函数的权重是负的,说明人设定的这个特征和真实情况是相反的,负得越多相反得越严重。
是不是还挺智能的哈哈哈哈((
well,however,虽然 MEMM 在一定程度上解决了 HMM 把依赖关系建模得太过简单的问题,但是它又引进了一个新的问题…
我们还是从 MEMM 的概率计算式出发。
如果你熟悉贪心算法,你可能会发现,诶 MEMM 的做法不就是贪心算法吗?在每一步,它都选择在这一步所有可能的选择中概率最大的那种。把所有步的选择合在一起,就得到了最终的路径。
emmm。。那…既然 MEMM 的路径选择算法本质上是一种贪心算法,那 MEMM 选择出来的路径(每个输入位置对应的输出)是不是就相当于贪心算法的结果?
而我们都知道,贪心算法不保证找到全局最优解,甚至很多时候它都找不到全局最优解。
所以。MEMM 给出的输出,很多时候并不是全局最优解。
我们可以从一个例子直观地感受到这件事情,如下图:
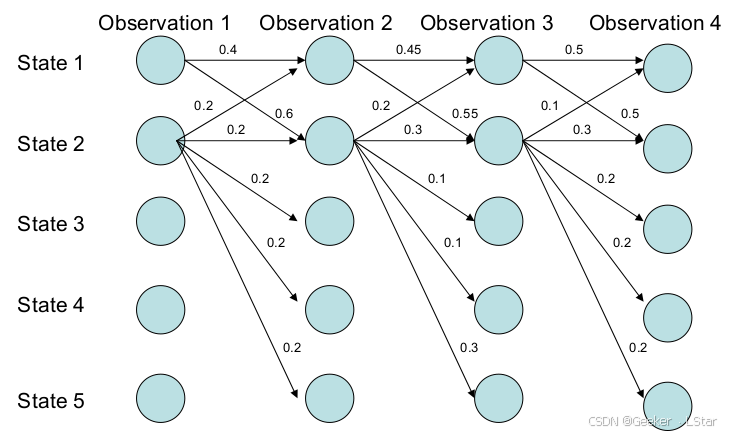
按照 MEMM “在每一步都选择当前步中转移概率最大的路径” 的做法,它最终会选择
1
→
2
→
2
→
2
1 \to 2 \to 2 \to 2
1→2→2→2 这条路径
但是,如果我们实际计算的话,我们会发现,MEMM 选择的路径并不是全局概率最大的路径。路径
1
→
1
→
1
→
1
1 \to 1 \to 1 \to 1
1→1→1→1 的概率更大!
P
(
1
→
1
→
1
→
1
)
=
0.4
×
0.45
×
0.5
=
0.09
P
(
1
→
2
→
2
→
2
)
=
0.6
×
0.3
×
0.3
=
0.054
\begin{array}{c} P(1 \to 1 \to 1 \to 1)=0.4 \times 0.45 \times 0.5=0.09 \\ P(1 \to 2 \to 2 \to 2)=0.6 \times 0.3 \times 0.3=0.054 \\ \end{array}
P(1→1→1→1)=0.4×0.45×0.5=0.09P(1→2→2→2)=0.6×0.3×0.3=0.054
嗯,我觉得问题已经阐述的很清楚了,现在的任务是我们怎么解决 MEMM 找不到全局最优解的问题?
这或许需要从 MEMM 的归一化方式入手了。
MEMM 之所以成为 “贪心算法”,本质上是它的局部归一化导致的。这个局部归一化让它在每个位置都选择这个位置最可能出现的
y
y
y,而忽视了每个位置的概率全局相乘以后可能的情况。
那么,想要解决这个问题,我们只需要把这个归一化从局部改成全局就可以了。
即,我们不再在每个位置都选择这个位置最有可能出现的 y y y,而是考虑整个输出序列,或者说对整个序列而不是序列中的每一个位置进行归一化,这样是不是就可以解决 MEMM 贪心算法无法找到最优解的问题了?
yes!! 在这样的背景下,CRF 诞生了。
啊哈!没错!如果你对概率计算足够熟悉的话,你甚至现在就可以想象出 CRF 的损失函数的长相!
呃啊啊啊不过我们现在先不说那么多关于 CRF 的(读者:不是,你看看你的标题是什么? ),我们先来把前面开的,关于通过 HMM / MEMM 来理解生成模型和判别模型之间的区别的坑,填上(
其实当时我看完 HMM 和 MEMM 的图结构对比之后,我突然发现——它们两个简直是用于对比生成模型和判别模型的绝妙选择!下面举一个词性标注的例子。
HMM 的图结构中,箭头是从不可观测的标签
I
I
I 指向可观测的输入
O
O
O 的,或者说是通过词性指向单词的。
换言之,HMM 认为我们是从词性中生成的单词(或者说按照词性的规律生成的句子),词性是不可观测的,我们需要通过句子去学习各种参数,最终反解出词性。模型学习的参数反映的是这套数据生成的原理。
而在 MEMM 的图结构中,箭头的方向更 straight forward,直接从输入指向标签,或者说通过单词指向词性。
也就是说,在 MEMM 中,我们只关注预测给定的句子中每个词的词性,而不关心每个词是怎么被生成的。模型学习的参数反映的是标注(分类)时的决策边界。
简单来说,(in my perspective)生成模型的尝试更为本质(比如深度学习领域的 diffusion,就是生成模型),而判别模型的做法更为直接。em 不过通常而言,在传统的机器学习领域,判别模型的性能都优于生成模型。
okkkkki,我觉得这个生成模型和判别模型这个问题算是解释清楚了,em 但是我们似乎偏题有点远…?? 好好好我们还是回到主题吧咳咳咳哈哈哈((
继续来说 CRF!
条件随机场 CRF
嗯,前面说了那么多,终于引出了这个~!
接上文,我们说到 MEMM 的局部归一化导致了它难以找到全局最优解,so 我们希望通过进行全局归一化来解决这个问题。
首先先回顾一下 MEMM 的局部条件概率计算公式:
P
(
y
t
∣
x
t
,
y
t
−
1
)
=
exp
(
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
P(y_t | x_t, y_{t-1})=\exp \left(\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)
P(yt∣xt,yt−1)=exp(k∑λkfk(yt−1,yt,xt,t))
想要解决 MEMM 的标签偏置问题,我们只需要先对每个可能的输出序列 Y Y Y 计算出这个 Y Y Y 整体的条件概率,然后再比较所有的 Y Y Y 的条件概率就可以了。
okay,我们先给出 CRF 中各个位置的条件概率:
P
(
y
t
∣
X
,
y
t
−
1
)
P(y_t | X, y_{t-1})
P(yt∣X,yt−1)
整体的形式和 MEMM 一样,不过注意
x
t
x_t
xt 被改成了
X
X
X。这是 CRF 和 MEMM(以及 HMM)之间一个非常重要的区别——CRF 推翻了前面两个模型的局部依赖性假设。
换言之,在 CRF 中,某个位置的
y
y
y 依赖的
x
x
x 不再局限于它对应那个位置的
x
x
x,而是拓展到了整个输入序列。即,CRF 中每个位置的
y
y
y 都能 “看到” 整个输入序列。这赋予了它捕捉更多依赖关系的能力。
clarify 完这一点,我们以某一个
Y
Y
Y 为例,它的整体条件概率就是各个位置(也可以理解为极大团)上的条件概率,也就是我们上面给出的条件概率,相乘,即:
P
(
Y
∣
X
)
=
∏
t
=
1
T
P
(
y
t
∣
X
,
y
t
−
1
)
=
∏
t
=
1
T
exp
(
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
X
,
t
)
)
=
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
X
,
t
)
)
P(Y|X)=\prod _{t=1}^{T}P(y_t | X, y_{t-1})=\prod _{t=1}^{T} \exp \left(\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, X, t\right)\right) \\=\exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, X, t\right)\right)
P(Y∣X)=t=1∏TP(yt∣X,yt−1)=t=1∏Texp(k∑λkfk(yt−1,yt,X,t))=exp(t=1∑Tk∑λkfk(yt−1,yt,X,t))
嗯!这样我们就得到一个
Y
Y
Y 的条件概率了!接下来是很常规的环节,计算配分函数,等于所有
Y
Y
Y 的条件概率相加,这里我们假设所有可能的
Y
Y
Y 共有
N
N
N 个:
Z
(
X
)
=
∑
i
=
1
N
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
(
i
)
,
y
t
(
i
)
,
X
(
i
)
,
t
)
)
Z(X)=\sum_{i=1}^{N} \exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}^{(i)}, y_{t}^{(i)}, X^{(i)}, t\right)\right)
Z(X)=i=1∑Nexp(t=1∑Tk∑λkfk(yt−1(i),yt(i),X(i),t))
okay 呀!最后对每个
Y
Y
Y 的条件概率做一个归一化就可以啦~:
P
(
Y
∣
X
)
=
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
∑
i
=
1
N
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
(
i
)
,
y
t
(
i
)
,
X
(
i
)
,
t
)
)
P(Y|X)=\frac {\exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)} {\sum_{i=1}^{N} \exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}^{(i)}, y_{t}^{(i)}, X^{(i)}, t\right)\right)}
P(Y∣X)=∑i=1Nexp(∑t=1T∑kλkfk(yt−1(i),yt(i),X(i),t))exp(∑t=1T∑kλkfk(yt−1,yt,xt,t))
好耶!!这样我们就得到了 CRF 的最终概率计算式!
是不是和我们在文章最开始说的形式一模一样!! 嘻嘻~
我觉得这么一说,从 HMM 推下来,你应该就比较明白为什么 CRF 的概率计算公式长这样了~个人认为是比从 MRF 推 CRF 更好的思路!
yes…现在我们已经知道了 CRF 是如何解决 MEMM 的标签偏置问题的了,但是你有没有从上面的计算方式中感觉到什么问题…?
比如说,我现在是知道全局归一化是怎么回事了,但是,errrr,CRF 的这种计算方式可比 MEMM 耗时间多了,我需要找到 “每一条路径” 的概率,然后再比较它们…如果想得更深一层,这些概率怎么计算?或者说,怎么高效地计算?
(噗哈哈哈像极了终于有了一个 idea 然而一旦开始尝试实现就会遇到各种各样的问题。。。)
啊哈!这就涉及到 CRF 的作为标注算法的 “三大任务” 之一——概率计算问题了!
如果你看过 HMM 那篇,你估计会对三大任务比较了解。CRF 的三大任务和 HMM 一样,或者说和所有标注模型一样。
不过,三大任务我们先暂时放在这里(当作一个悬念哈哈哈哈),后面会再说到的~
嗯,那么,总结一下,HMM、MEMM 和 CRF 之间的递进关系可以用几句话精准地概括。
- HMM 有两条假设:(1)观测独立性假设和(2)局部依赖性假设。
- MEMM 推翻了假设(1),但引入了标签偏置问题。
- CRF 在 MEMM 的基础上推翻了假设了(1)和(2),同时解决了 MEMM 的标签偏置问题。
同时,HMM 和 MEMM / CRF 之间有两个本质的区别,要注意区分。
- HMM 是生成模型,建模联合概率 P ( X , Y ) P(X,Y) P(X,Y);而 MEMM 和 CRF 是判别模型,建模条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)。
- HMM 是含有隐藏变量的模型,通过 EM 算法(或 EM + 数值优化算法)进行学习;MEMM 和 CRF 是用完全数据训练的模型,通过 MLE(或直接的数值优化算法)进行学习。
好耶!!!那到现在,我想你对 CRF 公式背后的 motivation 已经非常了解啦!!这个部分很有意思,相当于把主流的标注算法串成了一条线,可以多看几遍嘿嘿嘿。
now,我们已经了解 CRF 的样子,我们不妨来发掘一下它和我们前面讲过的最大熵模型之间的联系。
CRF 与最大熵模型
在 MRF 那篇的末尾我留下了一个悬念——MRF 是生成模型,所以虽然它和最大熵模型的形式很相近,它也不可能是最大熵模型的特例。但是,如果我们搞出了 “条件版” 或者说 “判别模型版” 的 MRF 呢?那是不是就可以成为最大熵模型的特例了?
答案是,yes!
前面我们已经说过,CRF 可以看作在给定输入的条件下,输出的 MRF。
呃呃呃那是不是说 CRF 可以被看作最大熵模型的特例?
不多说,我们直接来看 CRF 的表达式。
P
(
Y
∣
X
)
=
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
,
y
t
,
x
t
,
t
)
)
∑
i
=
1
N
exp
(
∑
t
=
1
T
∑
k
λ
k
f
k
(
y
t
−
1
(
i
)
,
y
t
(
i
)
,
X
(
i
)
,
t
)
)
P(Y|X)=\frac {\exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}, y_{t}, x_{t}, t\right)\right)} {\sum_{i=1}^{N} \exp \left(\sum _{t=1}^{T}\sum_{k} \lambda_{k} f_{k}\left(y_{t-1}^{(i)}, y_{t}^{(i)}, X^{(i)}, t\right)\right)}
P(Y∣X)=∑i=1Nexp(∑t=1T∑kλkfk(yt−1(i),yt(i),X(i),t))exp(∑t=1T∑kλkfk(yt−1,yt,xt,t))
再来看最大熵模型的一般式:
P
w
(
y
∣
x
)
=
exp
(
∑
i
=
1
m
w
i
f
i
(
x
,
y
)
)
Z
w
(
x
)
,
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
m
w
i
f
i
(
x
,
y
)
)
P_w(y|x) = \frac{\exp\bigg(\sum_{i=1}^m w_i f_i(x, y)\bigg)}{Z_w(x)}, \ Z_w(x)=\sum_y\exp\bigg(\sum_{i=1}^m w_i f_i(x, y)\bigg)
Pw(y∣x)=Zw(x)exp(∑i=1mwifi(x,y)), Zw(x)=y∑exp(i=1∑mwifi(x,y))
嘿!CRF 这个形式,这不就是最大熵模型的表达式嘛!
所以,CRF 可以看作是最大熵模型的一个特例,它也符合最大熵原理。
okayyyyy,到现在为止我们算是把 CRF 和其它很多模型之间的关系都梳理清楚啦!!小小总结一下…
【IMPORTANT!!!】
- CRF 是 MRF 的条件化形式。具体来说,CRF 定义为在给定输入的情况下,输出的 MRF。
- CRF 是最大熵模型(对数线性模型)的特例,满足最大熵原理。
- CRF 是 MEMM 的改进版本,MEMM 则是 HMM 的改进版本。CRF 推翻了 HMM 的两个限制过于严格的假设,同时解决了 MEMM 的标注偏置问题。
nice!!! 我觉得现在你应该已经很好地理解了 CRF 的来源以及它和其它模型的联系啦!接下来我们来看看 CRF 作为一个标注模型,它的 “三大任务”。
注意,这三大任务(或者说三大问题),我们在 HMM 那篇中都有系统的介绍,解决 CRF 中这三大问题的核心思想和 HMM 那篇几乎一模一样。建议先去看一看 HMM 那两篇中对这三个问题的基本介绍。
嗯!!因为这三大任务涉及到很多的数学,so 我单独开了一篇写,link:
【高中生讲机器学习】31. 理解条件随机场最清晰的思路!(下篇)
详细的数学细节都可以在下篇中找到!!
好耶,那这篇文章就到这里啦~~
感觉这篇的脉络梳理的还是很清晰的,嘿嘿。
下一篇再见啦!
这篇文章介绍了条件随机场的概念,并从多个角度阐述了条件随机场出现的 motivation,希望对你有所帮助!!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









