







哈希函数2:用于哈希表的存储和扩容
提示:咱们这几篇文章重点讲哈希函数,这些个知识点,用来跟互联网大厂的面试官聊的,不用写代码!
重要的关于哈希函数定义和应用的基础知识:
【1】哈希函数1:用于资源限制类机器统计文件或词频
什么是哈希函数?
Hash函数译为哈希函数,又称散列函数。
是把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出的值称为散列值或消息摘要。
简单来说就是一种将任意长度的输入消息压缩成某一固定长度的消息摘要的函数。
它具备以下的性质(哈希函数所必须的性质):
(1)f的输入无限:可应用于任意大小的数据块。
(2)f的输出有限:产生定长的输出。
(3)f没有随机性,同样的输入一定是同样的输出
(4)多对一:f对不同的输入,可能是同样的输入,因为(1)(2)导致输入很多,但是输出固定那么些
(5)f有均匀性或分散性:输入不同,但是输出是离散均匀分布在输出域中的;
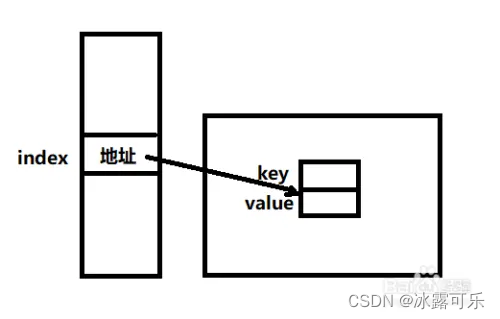
哈希表的存储原理
哈希表存的是键值对:

存储地址的生成:系统先将key值取出,利用hash函数转换成hash值,
再运用散列法(此处用除法散列法取余),得到需要存入数组的下标index;
这个操作就是类似咱们基础知识【1】里面的f%N一样的,


得到数组下标后,我们可以将key-value一起存入到数组中。
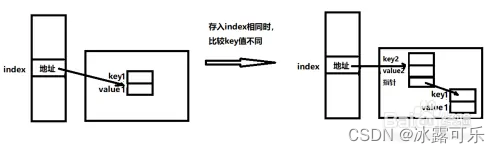
当使用index进行存储键值对的时候,如果此下标已经有了数据,
那么将通过equals方法比较两个hash值是否相同?
如果相等,再比较两个键值对key是否相等?
如果不等,则在此下标位置,以链表的方式,将新存储的数据放到表头;
如果相等,将覆盖更新原先的value;
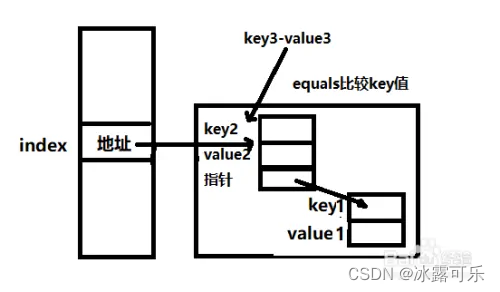
哈希表的查询原理:
同存储时一样,先将key值通过hash函数f转换成指向内存地址的hash值;

通过equals方法,比较hash值查找对应的内存地址,然后再通过内存地址找到对应的链表,
此时再通过equals方法,比较key值是否相等?
若相等,取出键值对返回数据,
如果不等,沿着链表继续向下寻找比较。
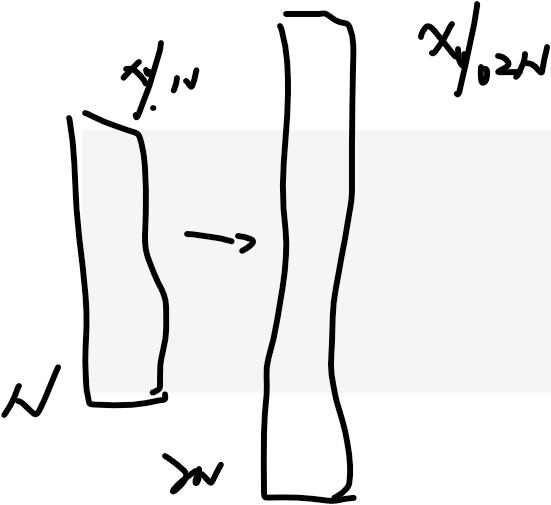
哈希表的离线扩容,操作速度log(n),但操作复杂度仍是o(1)
HashMap的默认长度为16,到达上限时自动扩容
原来长度为N
后来扩容到2N
需要把原来数据的地址统统改一下,f%2N
操作时间是o(log(n))
因此,由于自动扩容时hash表(数组)都需要重新扩容,会耗费性能,
因此一般在知道数据量大小的时候,指定长度更加有利于hashmap运行效率
因为空间变长了,所以呢,整体操作复杂度啊,相当于又除N了
等价于哈希表的操作复杂度仍然还是o(1)的
总结
提示:重要经验:
1)哈希表的存储,查询,都是要经过哈希函数转换地址的,f%N
2)哈希表往往是固定长度,当容量不够,自动扩容,但是整体上哈希表的操作仍然是o(1)时间复杂度!
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











